 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUltra-Low-Bitrate Speech Coding with Pretrained Transformers
Paper and Code
Jul 05, 2022
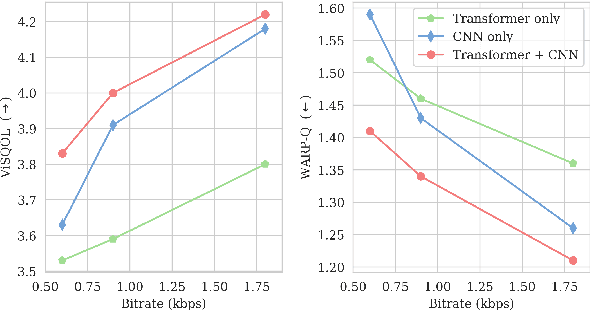
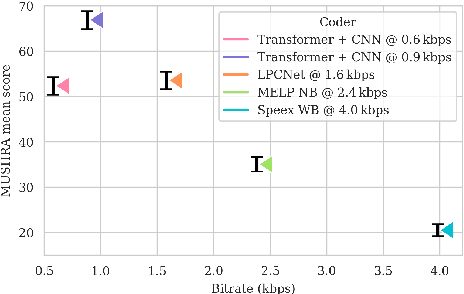
Speech coding facilitates the transmission of speech over low-bandwidth networks with minimal distortion. Neural-network based speech codecs have recently demonstrated significant improvements in quality over traditional approaches. While this new generation of codecs is capable of synthesizing high-fidelity speech, their use of recurrent or convolutional layers often restricts their effective receptive fields, which prevents them from compressing speech efficiently. We propose to further reduce the bitrate of neural speech codecs through the use of pretrained Transformers, capable of exploiting long-range dependencies in the input signal due to their inductive bias. As such, we use a pretrained Transformer in tandem with a convolutional encoder, which is trained end-to-end with a quantizer and a generative adversarial net decoder. Our numerical experiments show that supplementing the convolutional encoder of a neural speech codec with Transformer speech embeddings yields a speech codec with a bitrate of $600\,\mathrm{bps}$ that outperforms the original neural speech codec in synthesized speech quality when trained at the same bitrate. Subjective human evaluations suggest that the quality of the resulting codec is comparable or better than that of conventional codecs operating at three to four times the rate.