 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTrailBlazer: Trajectory Control for Diffusion-Based Video Generation
Dec 31, 2023Within recent approaches to text-to-video (T2V) generation, achieving controllability in the synthesized video is often a challenge. Typically, this issue is addressed by providing low-level per-frame guidance in the form of edge maps, depth maps, or an existing video to be altered. However, the process of obtaining such guidance can be labor-intensive. This paper focuses on enhancing controllability in video synthesis by employing straightforward bounding boxes to guide the subject in various ways, all without the need for neural network training, finetuning, optimization at inference time, or the use of pre-existing videos. Our algorithm, TrailBlazer, is constructed upon a pre-trained (T2V) model, and easy to implement. The subject is directed by a bounding box through the proposed spatial and temporal attention map editing. Moreover, we introduce the concept of keyframing, allowing the subject trajectory and overall appearance to be guided by both a moving bounding box and corresponding prompts, without the need to provide a detailed mask. The method is efficient, with negligible additional computation relative to the underlying pre-trained model. Despite the simplicity of the bounding box guidance, the resulting motion is surprisingly natural, with emergent effects including perspective and movement toward the virtual camera as the box size increases.
FDLS: A Deep Learning Approach to Production Quality, Controllable, and Retargetable Facial Performances
Sep 26, 2023
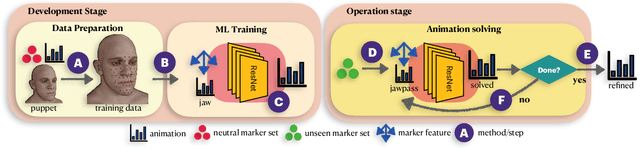
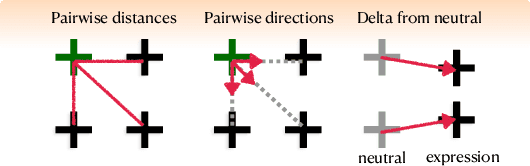
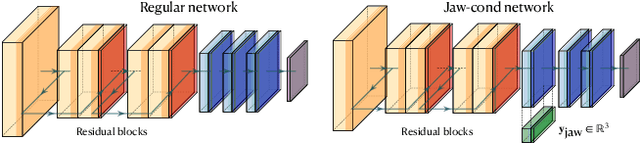
Visual effects commonly requires both the creation of realistic synthetic humans as well as retargeting actors' performances to humanoid characters such as aliens and monsters. Achieving the expressive performances demanded in entertainment requires manipulating complex models with hundreds of parameters. Full creative control requires the freedom to make edits at any stage of the production, which prohibits the use of a fully automatic ``black box'' solution with uninterpretable parameters. On the other hand, producing realistic animation with these sophisticated models is difficult and laborious. This paper describes FDLS (Facial Deep Learning Solver), which is Weta Digital's solution to these challenges. FDLS adopts a coarse-to-fine and human-in-the-loop strategy, allowing a solved performance to be verified and edited at several stages in the solving process. To train FDLS, we first transform the raw motion-captured data into robust graph features. Secondly, based on the observation that the artists typically finalize the jaw pass animation before proceeding to finer detail, we solve for the jaw motion first and predict fine expressions with region-based networks conditioned on the jaw position. Finally, artists can optionally invoke a non-linear finetuning process on top of the FDLS solution to follow the motion-captured virtual markers as closely as possible. FDLS supports editing if needed to improve the results of the deep learning solution and it can handle small daily changes in the actor's face shape. FDLS permits reliable and production-quality performance solving with minimal training and little or no manual effort in many cases, while also allowing the solve to be guided and edited in unusual and difficult cases. The system has been under development for several years and has been used in major movies.
Directed Diffusion: Direct Control of Object Placement through Attention Guidance
Feb 25, 2023Text-guided diffusion models such as DALLE-2, IMAGEN, and Stable Diffusion are able to generate an effectively endless variety of images given only a short text prompt describing the desired image content. In many cases the images are very high quality as well. However, these models often struggle to compose scenes containing several key objects such as characters in specified positional relationships. Unfortunately, this capability to ``direct'' the placement of characters and objects both within and across images is crucial in storytelling, as recognized in the literature on film and animation theory. In this work we take a particularly straightforward approach to providing the needed direction, by injecting ``activation'' at desired positions in the cross-attention maps corresponding to the objects under control, while attenuating the remainder of the map. The resulting approach is a step toward generalizing the applicability of text-guided diffusion models beyond single images to collections of related images, as in storybooks. To the best of our knowledge, our Directed Diffusion method is the first diffusion technique that provides positional control over multiple objects, while making use of an existing pre-trained model and maintaining a coherent blend between the positioned objects and the background. Moreover, it requires only a few lines to implement.
The HSIC Bottleneck: Deep Learning without Back-Propagation
Aug 05, 2019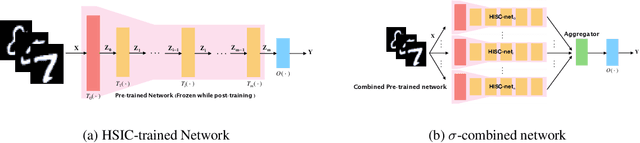
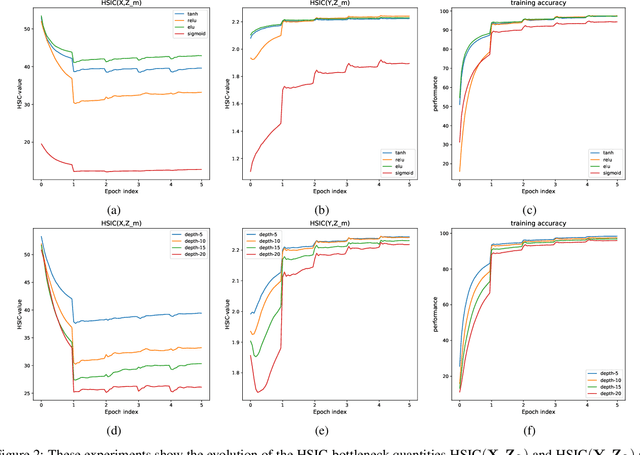
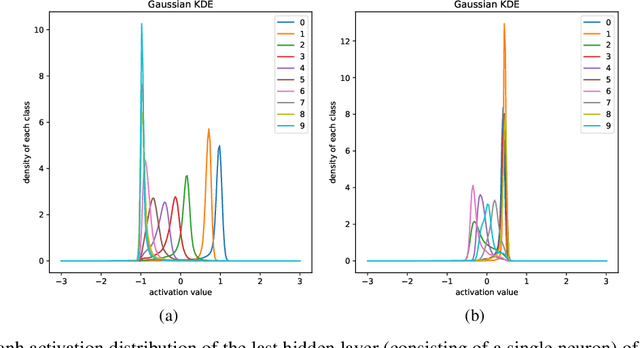
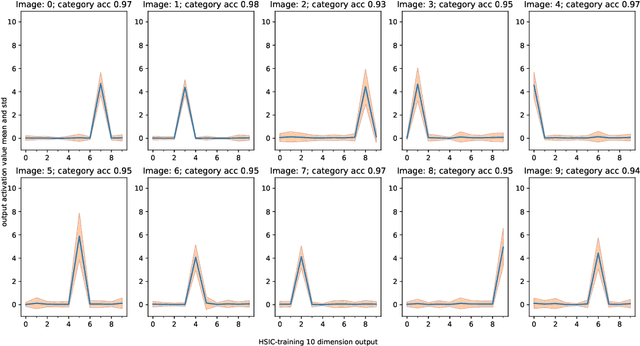
We introduce the HSIC (Hilbert-Schmidt independence criterion) bottleneck for training deep neural networks. The HSIC bottleneck is an alternative to conventional backpropagation, that has a number of distinct advantages. The method facilitates parallel processing and requires significantly less operations. It does not suffer from exploding or vanishing gradients. It is biologically more plausible than backpropagation as there is no requirement for symmetric feedback. We find that the HSIC bottleneck provides a performance on the MNIST/FashionMNIST/CIFAR10 classification comparable to backpropagation with a cross-entropy target, even when the system is not encouraged to make the output resemble the classification labels. Appending a single layer trained with SGD (without backpropagation) results in state-of-the-art performance.