 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHigh Quality Diffusion Distillation on a Single GPU with Relative and Absolute Position Matching
Mar 26, 2025We introduce relative and absolute position matching (RAPM), a diffusion distillation method resulting in high quality generation that can be trained efficiently on a single GPU. Recent diffusion distillation research has achieved excellent results for high-resolution text-to-image generation with methods such as phased consistency models (PCM) and improved distribution matching distillation (DMD2). However, these methods generally require many GPUs (e.g.~8-64) and significant batchsizes (e.g.~128-2048) during training, resulting in memory and compute requirements that are beyond the resources of some researchers. RAPM provides effective single-GPU diffusion distillation training with a batchsize of 1. The new method attempts to mimic the sampling trajectories of the teacher model by matching the relative and absolute positions. The design of relative positions is inspired by PCM. Two discriminators are introduced accordingly in RAPM, one for matching relative positions and the other for absolute positions. Experimental results on StableDiffusion (SD) V1.5 and SDXL indicate that RAPM with 4 timesteps produces comparable FID scores as the best method with 1 timestep under very limited computational resources.
Edify Image: High-Quality Image Generation with Pixel Space Laplacian Diffusion Models
Nov 11, 2024We introduce Edify Image, a family of diffusion models capable of generating photorealistic image content with pixel-perfect accuracy. Edify Image utilizes cascaded pixel-space diffusion models trained using a novel Laplacian diffusion process, in which image signals at different frequency bands are attenuated at varying rates. Edify Image supports a wide range of applications, including text-to-image synthesis, 4K upsampling, ControlNets, 360 HDR panorama generation, and finetuning for image customization.
Edify 3D: Scalable High-Quality 3D Asset Generation
Nov 11, 2024
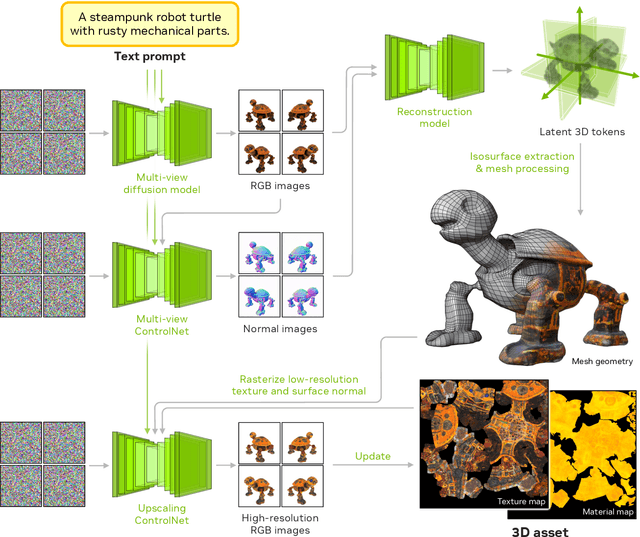
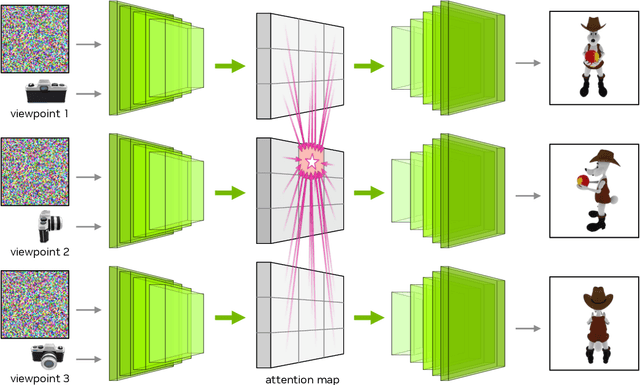

We introduce Edify 3D, an advanced solution designed for high-quality 3D asset generation. Our method first synthesizes RGB and surface normal images of the described object at multiple viewpoints using a diffusion model. The multi-view observations are then used to reconstruct the shape, texture, and PBR materials of the object. Our method can generate high-quality 3D assets with detailed geometry, clean shape topologies, high-resolution textures, and materials within 2 minutes of runtime.
On Exact Bit-level Reversible Transformers Without Changing Architectures
Jul 12, 2024In the literature, various reversible deep neural networks (DNN) models have been proposed to reduce memory consumption or improve data-throughput in the training process. However, almost all existing reversible DNNs either are constrained to have special structures or are constructed by modifying the original DNN architectures considerably to enable reversibility. In this work, we propose exact bit-level reversible transformers without changing the architectures in the inference procedure. The basic idea is to first treat each transformer block as the Euler integration approximation for solving an ordinary differential equation (ODE) and then incorporate the technique of bidirectional integration approximation (BDIA) (see [26]) for BDIA-based diffusion inversion) into the neural architecture together with activation quantization to make it exactly bit-level reversible, referred to as BDIA-transformer. In the training process, we let a hyper-parameter $\gamma$ in BDIA-transformer randomly take one of the two values $\{0.5, -0.5\}$ per transformer block for averaging two consecutive integration approximations, which regularizes the models for improving the validation accuracy. Light-weight side information per transformer block is required to be stored in the forward process to account for binary quantization loss to enable exact bit-level reversibility. In the inference procedure, the expectation $\mathbb{E}(\gamma)=0$ is taken to make the resulting architectures of BDIA-transformer be identical to transformers up to activation quantization. Empirical study indicates that BDIA-transformers outperform their original counterparts notably due to the regularization effect of the $\gamma$ parameter.
TrailBlazer: Trajectory Control for Diffusion-Based Video Generation
Dec 31, 2023Within recent approaches to text-to-video (T2V) generation, achieving controllability in the synthesized video is often a challenge. Typically, this issue is addressed by providing low-level per-frame guidance in the form of edge maps, depth maps, or an existing video to be altered. However, the process of obtaining such guidance can be labor-intensive. This paper focuses on enhancing controllability in video synthesis by employing straightforward bounding boxes to guide the subject in various ways, all without the need for neural network training, finetuning, optimization at inference time, or the use of pre-existing videos. Our algorithm, TrailBlazer, is constructed upon a pre-trained (T2V) model, and easy to implement. The subject is directed by a bounding box through the proposed spatial and temporal attention map editing. Moreover, we introduce the concept of keyframing, allowing the subject trajectory and overall appearance to be guided by both a moving bounding box and corresponding prompts, without the need to provide a detailed mask. The method is efficient, with negligible additional computation relative to the underlying pre-trained model. Despite the simplicity of the bounding box guidance, the resulting motion is surprisingly natural, with emergent effects including perspective and movement toward the virtual camera as the box size increases.
FDLS: A Deep Learning Approach to Production Quality, Controllable, and Retargetable Facial Performances
Sep 26, 2023
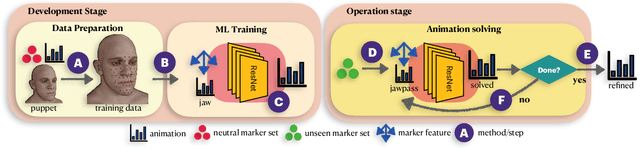
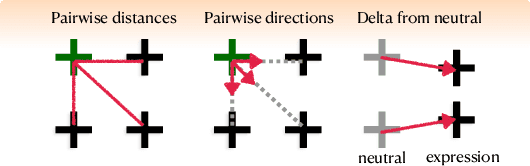
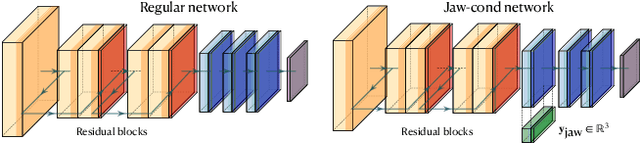
Visual effects commonly requires both the creation of realistic synthetic humans as well as retargeting actors' performances to humanoid characters such as aliens and monsters. Achieving the expressive performances demanded in entertainment requires manipulating complex models with hundreds of parameters. Full creative control requires the freedom to make edits at any stage of the production, which prohibits the use of a fully automatic ``black box'' solution with uninterpretable parameters. On the other hand, producing realistic animation with these sophisticated models is difficult and laborious. This paper describes FDLS (Facial Deep Learning Solver), which is Weta Digital's solution to these challenges. FDLS adopts a coarse-to-fine and human-in-the-loop strategy, allowing a solved performance to be verified and edited at several stages in the solving process. To train FDLS, we first transform the raw motion-captured data into robust graph features. Secondly, based on the observation that the artists typically finalize the jaw pass animation before proceeding to finer detail, we solve for the jaw motion first and predict fine expressions with region-based networks conditioned on the jaw position. Finally, artists can optionally invoke a non-linear finetuning process on top of the FDLS solution to follow the motion-captured virtual markers as closely as possible. FDLS supports editing if needed to improve the results of the deep learning solution and it can handle small daily changes in the actor's face shape. FDLS permits reliable and production-quality performance solving with minimal training and little or no manual effort in many cases, while also allowing the solve to be guided and edited in unusual and difficult cases. The system has been under development for several years and has been used in major movies.
Exact Diffusion Inversion via Bi-directional Integration Approximation
Jul 21, 2023



Recently, different methods have been proposed to address the inconsistency issue of DDIM inversion to enable image editing, such as EDICT \cite{Wallace23EDICT} and Null-text inversion \cite{Mokady23NullTestInv}. However, the above methods introduce considerable computational overhead. In this paper, we propose a new technique, named \emph{bi-directional integration approximation} (BDIA), to perform exact diffusion inversion with neglible computational overhead. Suppose we would like to estimate the next diffusion state $\boldsymbol{z}_{i-1}$ at timestep $t_i$ with the historical information $(i,\boldsymbol{z}_i)$ and $(i+1,\boldsymbol{z}_{i+1})$. We first obtain the estimated Gaussian noise $\hat{\boldsymbol{\epsilon}}(\boldsymbol{z}_i,i)$, and then apply the DDIM update procedure twice for approximating the ODE integration over the next time-slot $[t_i, t_{i-1}]$ in the forward manner and the previous time-slot $[t_i, t_{t+1}]$ in the backward manner. The DDIM step for the previous time-slot is used to refine the integration approximation made earlier when computing $\boldsymbol{z}_i$. One nice property with BDIA-DDIM is that the update expression for $\boldsymbol{z}_{i-1}$ is a linear combination of $(\boldsymbol{z}_{i+1}, \boldsymbol{z}_i, \hat{\boldsymbol{\epsilon}}(\boldsymbol{z}_i,i))$. This allows for exact backward computation of $\boldsymbol{z}_{i+1}$ given $(\boldsymbol{z}_i, \boldsymbol{z}_{i-1})$, thus leading to exact diffusion inversion. Experiments on both image reconstruction and image editing were conducted, confirming our statement. BDIA can also be applied to improve the performance of other ODE solvers in addition to DDIM. In our work, it is found that applying BDIA to the EDM sampling procedure produces slightly better FID score over CIFAR10.
Training-Free Neural Matte Extraction for Visual Effects
Jun 29, 2023
Alpha matting is widely used in video conferencing as well as in movies, television, and social media sites. Deep learning approaches to the matte extraction problem are well suited to video conferencing due to the consistent subject matter (front-facing humans), however training-based approaches are somewhat pointless for entertainment videos where varied subjects (spaceships, monsters, etc.) may appear only a few times in a single movie -- if a method of creating ground truth for training exists, just use that method to produce the desired mattes. We introduce a training-free high quality neural matte extraction approach that specifically targets the assumptions of visual effects production. Our approach is based on the deep image prior, which optimizes a deep neural network to fit a single image, thereby providing a deep encoding of the particular image. We make use of the representations in the penultimate layer to interpolate coarse and incomplete "trimap" constraints. Videos processed with this approach are temporally consistent. The algorithm is both very simple and surprisingly effective.
Directed Diffusion: Direct Control of Object Placement through Attention Guidance
Feb 25, 2023Text-guided diffusion models such as DALLE-2, IMAGEN, and Stable Diffusion are able to generate an effectively endless variety of images given only a short text prompt describing the desired image content. In many cases the images are very high quality as well. However, these models often struggle to compose scenes containing several key objects such as characters in specified positional relationships. Unfortunately, this capability to ``direct'' the placement of characters and objects both within and across images is crucial in storytelling, as recognized in the literature on film and animation theory. In this work we take a particularly straightforward approach to providing the needed direction, by injecting ``activation'' at desired positions in the cross-attention maps corresponding to the objects under control, while attenuating the remainder of the map. The resulting approach is a step toward generalizing the applicability of text-guided diffusion models beyond single images to collections of related images, as in storybooks. To the best of our knowledge, our Directed Diffusion method is the first diffusion technique that provides positional control over multiple objects, while making use of an existing pre-trained model and maintaining a coherent blend between the positioned objects and the background. Moreover, it requires only a few lines to implement.
The HSIC Bottleneck: Deep Learning without Back-Propagation
Aug 05, 2019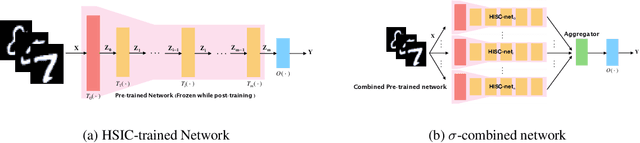
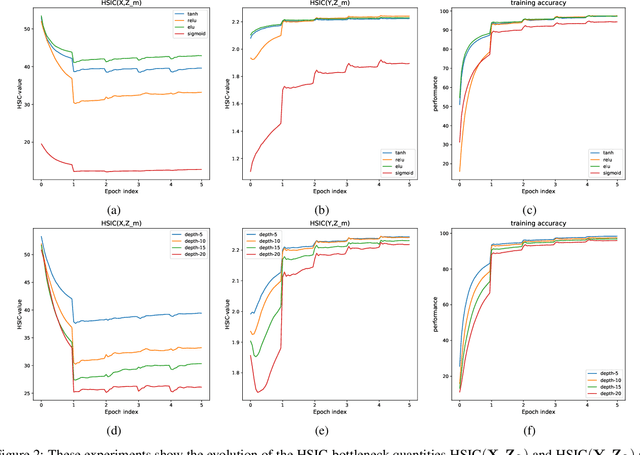
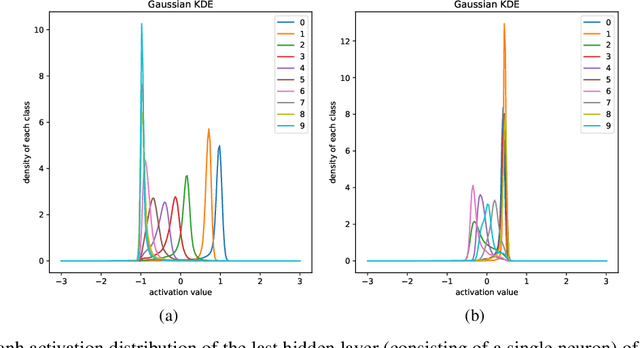
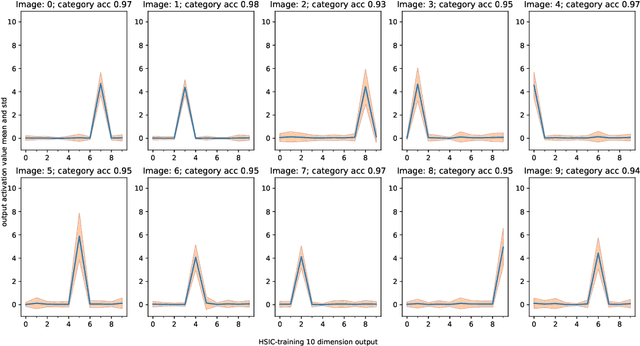
We introduce the HSIC (Hilbert-Schmidt independence criterion) bottleneck for training deep neural networks. The HSIC bottleneck is an alternative to conventional backpropagation, that has a number of distinct advantages. The method facilitates parallel processing and requires significantly less operations. It does not suffer from exploding or vanishing gradients. It is biologically more plausible than backpropagation as there is no requirement for symmetric feedback. We find that the HSIC bottleneck provides a performance on the MNIST/FashionMNIST/CIFAR10 classification comparable to backpropagation with a cross-entropy target, even when the system is not encouraged to make the output resemble the classification labels. Appending a single layer trained with SGD (without backpropagation) results in state-of-the-art performance.