 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTraining-Free Neural Matte Extraction for Visual Effects
Jun 29, 2023
Alpha matting is widely used in video conferencing as well as in movies, television, and social media sites. Deep learning approaches to the matte extraction problem are well suited to video conferencing due to the consistent subject matter (front-facing humans), however training-based approaches are somewhat pointless for entertainment videos where varied subjects (spaceships, monsters, etc.) may appear only a few times in a single movie -- if a method of creating ground truth for training exists, just use that method to produce the desired mattes. We introduce a training-free high quality neural matte extraction approach that specifically targets the assumptions of visual effects production. Our approach is based on the deep image prior, which optimizes a deep neural network to fit a single image, thereby providing a deep encoding of the particular image. We make use of the representations in the penultimate layer to interpolate coarse and incomplete "trimap" constraints. Videos processed with this approach are temporally consistent. The algorithm is both very simple and surprisingly effective.
Catching Out-of-Context Misinformation with Self-supervised Learning
Jan 27, 2021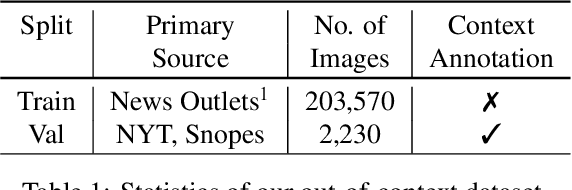

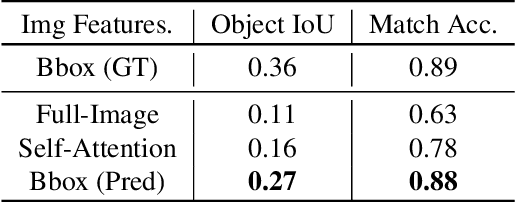
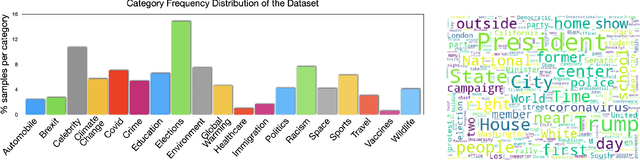
Despite the recent attention to DeepFakes and other forms of image manipulations, one of the most prevalent ways to mislead audiences is the use of unaltered images in a new but false context. To address these challenges and support fact-checkers, we propose a new method that automatically detects out-of-context image and text pairs. Our core idea is a self-supervised training strategy where we only need images with matching (and non-matching) captions from different sources. At train time, our method learns to selectively align individual objects in an image with textual claims, without explicit supervision. At test time, we check for a given text pair if both texts correspond to same object(s) in the image but semantically convey different descriptions, which allows us to make fairly accurate out-of-context predictions. Our method achieves 82% out-of-context detection accuracy. To facilitate training our method, we created a large-scale dataset of 200K images which we match with 450K textual captions from a variety of news websites, blogs, and social media posts; i.e., for each image, we obtained several captions.
SimPose: Effectively Learning DensePose and Surface Normals of People from Simulated Data
Jul 30, 2020


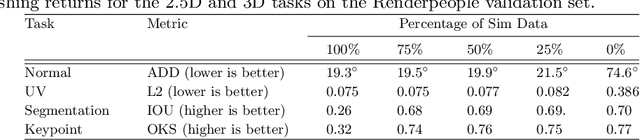
With a proliferation of generic domain-adaptation approaches, we report a simple yet effective technique for learning difficult per-pixel 2.5D and 3D regression representations of articulated people. We obtained strong sim-to-real domain generalization for the 2.5D DensePose estimation task and the 3D human surface normal estimation task. On the multi-person DensePose MSCOCO benchmark, our approach outperforms the state-of-the-art methods which are trained on real images that are densely labelled. This is an important result since obtaining human manifold's intrinsic uv coordinates on real images is time consuming and prone to labeling noise. Additionally, we present our model's 3D surface normal predictions on the MSCOCO dataset that lacks any real 3D surface normal labels. The key to our approach is to mitigate the "Inter-domain Covariate Shift" with a carefully selected training batch from a mixture of domain samples, a deep batch-normalized residual network, and a modified multi-task learning objective. Our approach is complementary to existing domain-adaptation techniques and can be applied to other dense per-pixel pose estimation problems.
MoDeep: A Deep Learning Framework Using Motion Features for Human Pose Estimation
Sep 28, 2014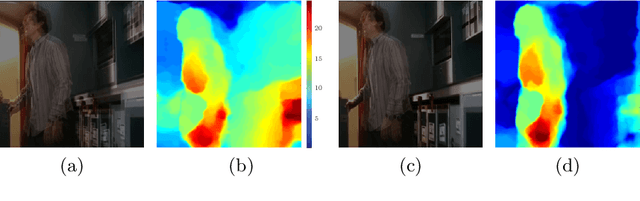
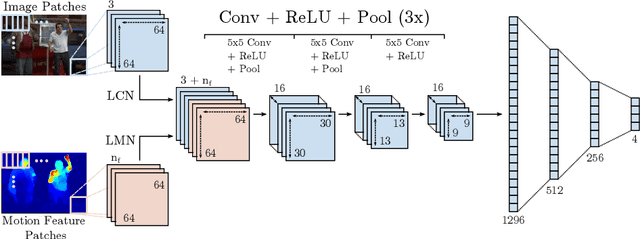
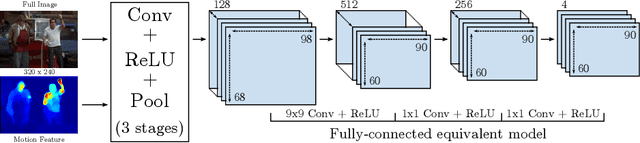
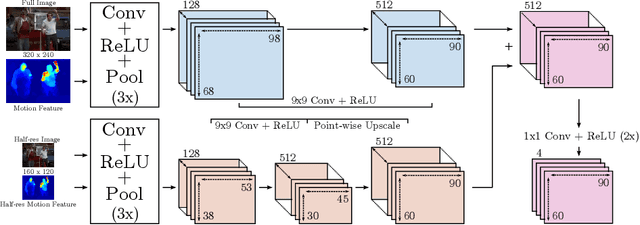
In this work, we propose a novel and efficient method for articulated human pose estimation in videos using a convolutional network architecture, which incorporates both color and motion features. We propose a new human body pose dataset, FLIC-motion, that extends the FLIC dataset with additional motion features. We apply our architecture to this dataset and report significantly better performance than current state-of-the-art pose detection systems.
Joint Training of a Convolutional Network and a Graphical Model for Human Pose Estimation
Sep 17, 2014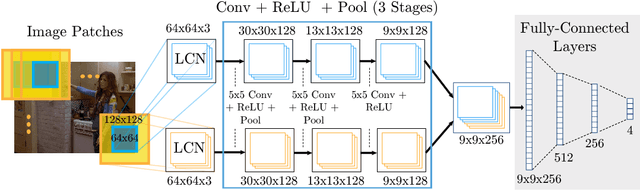
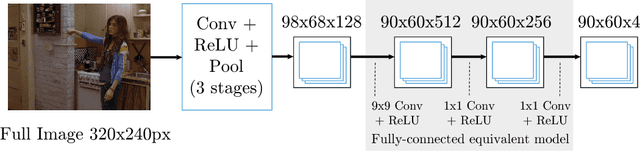
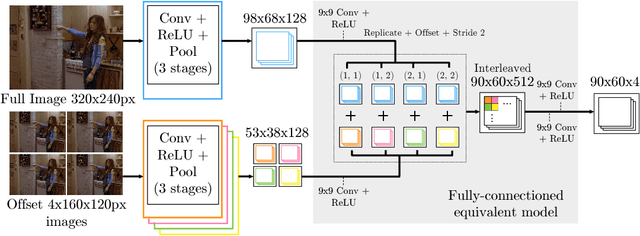
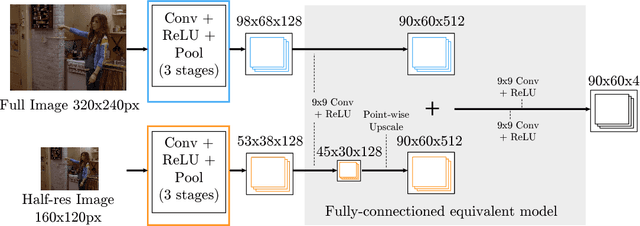
This paper proposes a new hybrid architecture that consists of a deep Convolutional Network and a Markov Random Field. We show how this architecture is successfully applied to the challenging problem of articulated human pose estimation in monocular images. The architecture can exploit structural domain constraints such as geometric relationships between body joint locations. We show that joint training of these two model paradigms improves performance and allows us to significantly outperform existing state-of-the-art techniques.
Learning Human Pose Estimation Features with Convolutional Networks
Apr 23, 2014
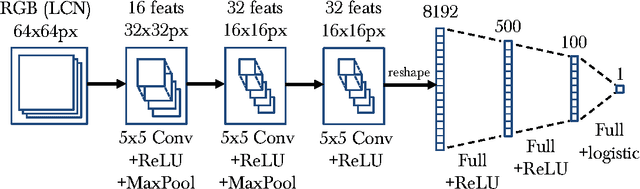
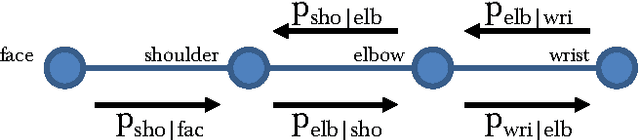
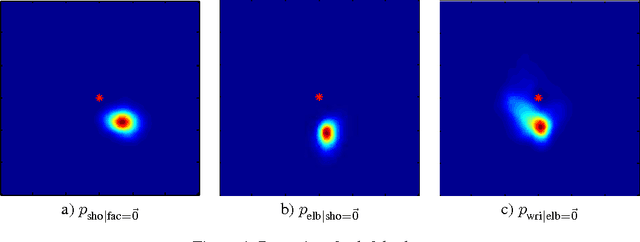
This paper introduces a new architecture for human pose estimation using a multi- layer convolutional network architecture and a modified learning technique that learns low-level features and higher-level weak spatial models. Unconstrained human pose estimation is one of the hardest problems in computer vision, and our new architecture and learning schema shows significant improvement over the current state-of-the-art results. The main contribution of this paper is showing, for the first time, that a specific variation of deep learning is able to outperform all existing traditional architectures on this task. The paper also discusses several lessons learned while researching alternatives, most notably, that it is possible to learn strong low-level feature detectors on features that might even just cover a few pixels in the image. Higher-level spatial models improve somewhat the overall result, but to a much lesser extent then expected. Many researchers previously argued that the kinematic structure and top-down information is crucial for this domain, but with our purely bottom up, and weak spatial model, we could improve other more complicated architectures that currently produce the best results. This mirrors what many other researchers, like those in the speech recognition, object recognition, and other domains have experienced.