 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGaussianSpeech: Audio-Driven Gaussian Avatars
Nov 27, 2024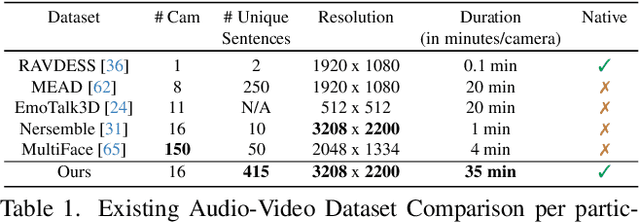
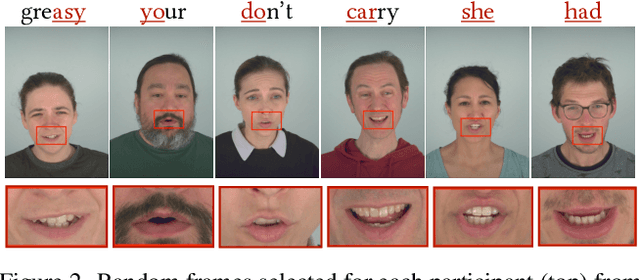
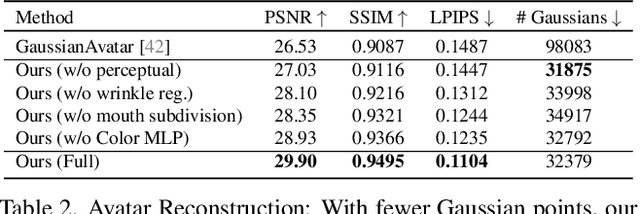
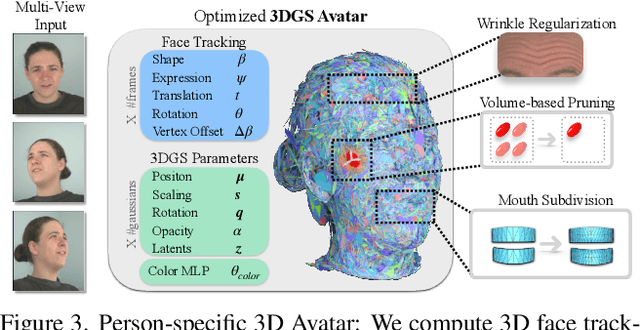
We introduce GaussianSpeech, a novel approach that synthesizes high-fidelity animation sequences of photo-realistic, personalized 3D human head avatars from spoken audio. To capture the expressive, detailed nature of human heads, including skin furrowing and finer-scale facial movements, we propose to couple speech signal with 3D Gaussian splatting to create realistic, temporally coherent motion sequences. We propose a compact and efficient 3DGS-based avatar representation that generates expression-dependent color and leverages wrinkle- and perceptually-based losses to synthesize facial details, including wrinkles that occur with different expressions. To enable sequence modeling of 3D Gaussian splats with audio, we devise an audio-conditioned transformer model capable of extracting lip and expression features directly from audio input. Due to the absence of high-quality datasets of talking humans in correspondence with audio, we captured a new large-scale multi-view dataset of audio-visual sequences of talking humans with native English accents and diverse facial geometry. GaussianSpeech consistently achieves state-of-the-art performance with visually natural motion at real time rendering rates, while encompassing diverse facial expressions and styles.
FaceTalk: Audio-Driven Motion Diffusion for Neural Parametric Head Models
Dec 13, 2023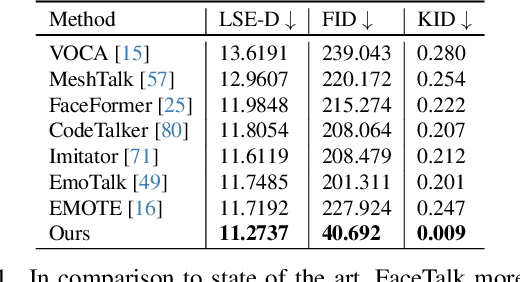
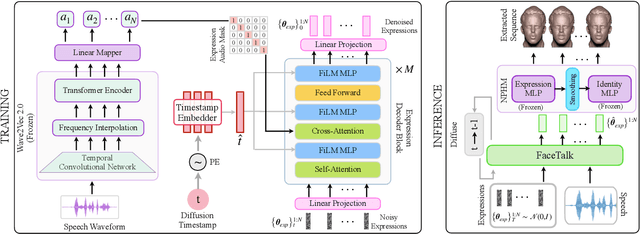
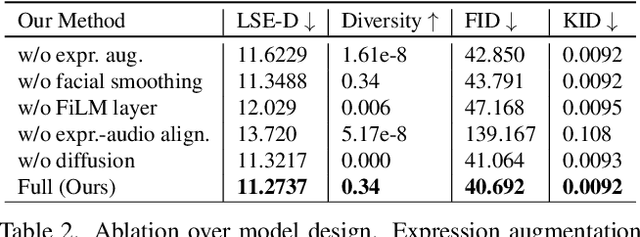
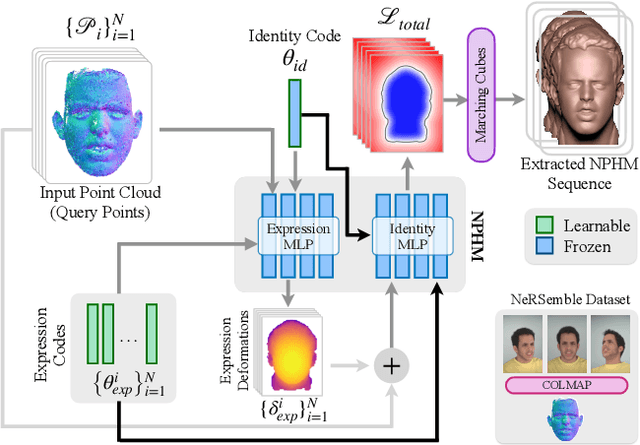
We introduce FaceTalk, a novel generative approach designed for synthesizing high-fidelity 3D motion sequences of talking human heads from input audio signal. To capture the expressive, detailed nature of human heads, including hair, ears, and finer-scale eye movements, we propose to couple speech signal with the latent space of neural parametric head models to create high-fidelity, temporally coherent motion sequences. We propose a new latent diffusion model for this task, operating in the expression space of neural parametric head models, to synthesize audio-driven realistic head sequences. In the absence of a dataset with corresponding NPHM expressions to audio, we optimize for these correspondences to produce a dataset of temporally-optimized NPHM expressions fit to audio-video recordings of people talking. To the best of our knowledge, this is the first work to propose a generative approach for realistic and high-quality motion synthesis of volumetric human heads, representing a significant advancement in the field of audio-driven 3D animation. Notably, our approach stands out in its ability to generate plausible motion sequences that can produce high-fidelity head animation coupled with the NPHM shape space. Our experimental results substantiate the effectiveness of FaceTalk, consistently achieving superior and visually natural motion, encompassing diverse facial expressions and styles, outperforming existing methods by 75% in perceptual user study evaluation.
ClipFace: Text-guided Editing of Textured 3D Morphable Models
Dec 02, 2022We propose ClipFace, a novel self-supervised approach for text-guided editing of textured 3D morphable model of faces. Specifically, we employ user-friendly language prompts to enable control of the expressions as well as appearance of 3D faces. We leverage the geometric expressiveness of 3D morphable models, which inherently possess limited controllability and texture expressivity, and develop a self-supervised generative model to jointly synthesize expressive, textured, and articulated faces in 3D. We enable high-quality texture generation for 3D faces by adversarial self-supervised training, guided by differentiable rendering against collections of real RGB images. Controllable editing and manipulation are given by language prompts to adapt texture and expression of the 3D morphable model. To this end, we propose a neural network that predicts both texture and expression latent codes of the morphable model. Our model is trained in a self-supervised fashion by exploiting differentiable rendering and losses based on a pre-trained CLIP model. Once trained, our model jointly predicts face textures in UV-space, along with expression parameters to capture both geometry and texture changes in facial expressions in a single forward pass. We further show the applicability of our method to generate temporally changing textures for a given animation sequence.
TAFIM: Targeted Adversarial Attacks against Facial Image Manipulations
Dec 16, 2021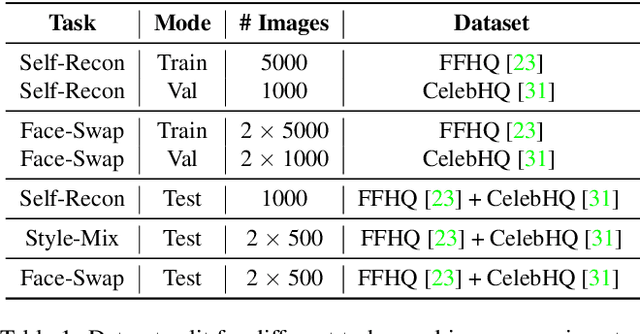
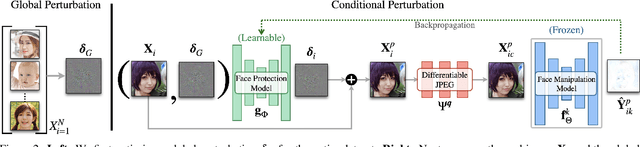
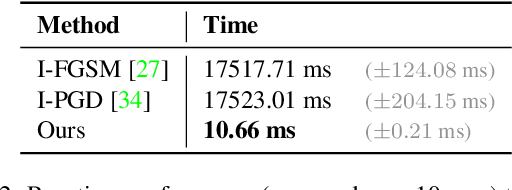
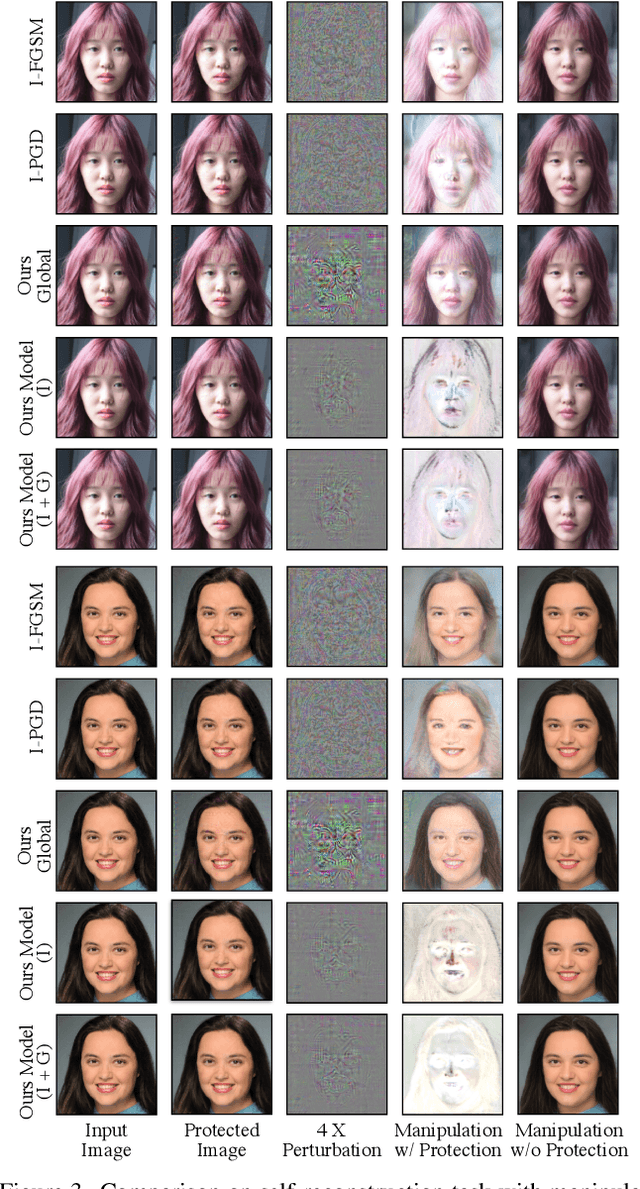
Face image manipulation methods, despite having many beneficial applications in computer graphics, can also raise concerns by affecting an individual's privacy or spreading disinformation. In this work, we propose a proactive defense to prevent face manipulation from happening in the first place. To this end, we introduce a novel data-driven approach that produces image-specific perturbations which are embedded in the original images. The key idea is that these protected images prevent face manipulation by causing the manipulation model to produce a predefined manipulation target (uniformly colored output image in our case) instead of the actual manipulation. Compared to traditional adversarial attacks that optimize noise patterns for each image individually, our generalized model only needs a single forward pass, thus running orders of magnitude faster and allowing for easy integration in image processing stacks, even on resource-constrained devices like smartphones. In addition, we propose to leverage a differentiable compression approximation, hence making generated perturbations robust to common image compression. We further show that a generated perturbation can simultaneously prevent against multiple manipulation methods.
IndoFashion : Apparel Classification for Indian Ethnic Clothes
Apr 06, 2021


Cloth categorization is an important research problem that is used by e-commerce websites for displaying correct products to the end-users. Indian clothes have a large number of clothing categories both for men and women. The traditional Indian clothes like "Saree" and "Dhoti" are worn very differently from western clothes like t-shirts and jeans. Moreover, the style and patterns of ethnic clothes have a very different distribution from western outfits. Thus the models trained on standard cloth datasets fail miserably on ethnic outfits. To address these challenges, we introduce the first large-scale ethnic dataset of over 106k images with 15 different categories for fine-grained classification of Indian ethnic clothes. We gathered a diverse dataset from a large number of Indian e-commerce websites. We then evaluate several baselines for the cloth classification task on our dataset. In the end, we obtain 88.43% classification accuracy. We hope that our dataset would foster research in the development of several algorithms such as cloth classification, landmark detection, especially for ethnic clothes.
Deep Image Compositing
Mar 29, 2021

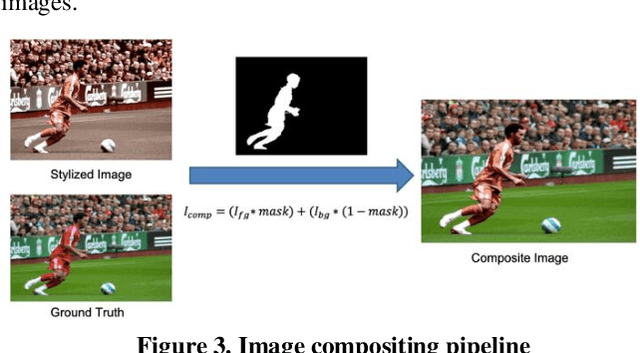
In image editing, the most common task is pasting objects from one image to the other and then eventually adjusting the manifestation of the foreground object with the background object. This task is called image compositing. But image compositing is a challenging problem that requires professional editing skills and a considerable amount of time. Not only these professionals are expensive to hire, but the tools (like Adobe Photoshop) used for doing such tasks are also expensive to purchase making the overall task of image compositing difficult for people without this skillset. In this work, we aim to cater to this problem by making composite images look realistic. To achieve this, we are using Generative Adversarial Networks (GANS). By training the network with a diverse range of filters applied to the images and special loss functions, the model is able to decode the color histogram of the foreground and background part of the image and also learns to blend the foreground object with the background. The hue and saturation values of the image play an important role as discussed in this paper. To the best of our knowledge, this is the first work that uses GANs for the task of image compositing. Currently, there is no benchmark dataset available for image compositing. So we created the dataset and will also make the dataset publicly available for benchmarking. Experimental results on this dataset show that our method outperforms all current state-of-the-art methods.
* ESSE 2020: Proceedings of the 2020 European Symposium on Software Engineering
Catching Out-of-Context Misinformation with Self-supervised Learning
Jan 27, 2021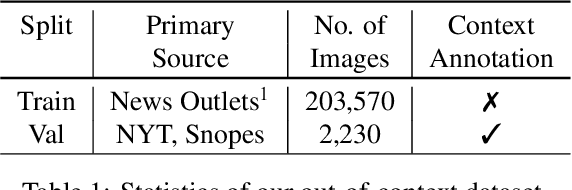

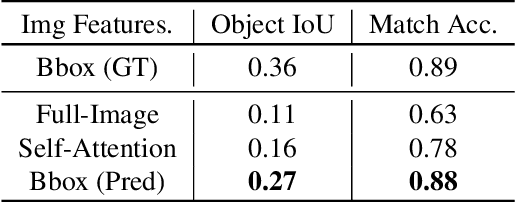
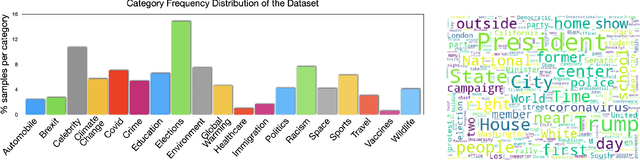
Despite the recent attention to DeepFakes and other forms of image manipulations, one of the most prevalent ways to mislead audiences is the use of unaltered images in a new but false context. To address these challenges and support fact-checkers, we propose a new method that automatically detects out-of-context image and text pairs. Our core idea is a self-supervised training strategy where we only need images with matching (and non-matching) captions from different sources. At train time, our method learns to selectively align individual objects in an image with textual claims, without explicit supervision. At test time, we check for a given text pair if both texts correspond to same object(s) in the image but semantically convey different descriptions, which allows us to make fairly accurate out-of-context predictions. Our method achieves 82% out-of-context detection accuracy. To facilitate training our method, we created a large-scale dataset of 200K images which we match with 450K textual captions from a variety of news websites, blogs, and social media posts; i.e., for each image, we obtained several captions.
Generalized Zero and Few-Shot Transfer for Facial Forgery Detection
Jun 21, 2020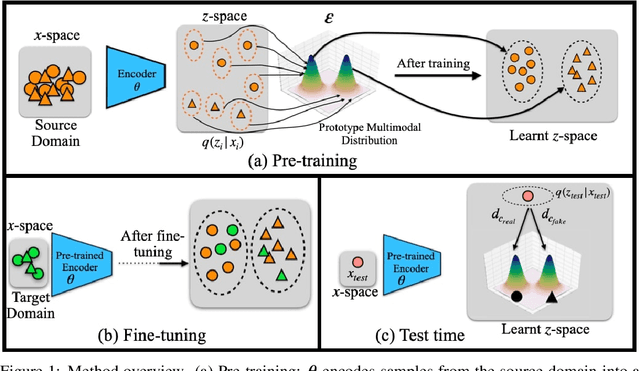
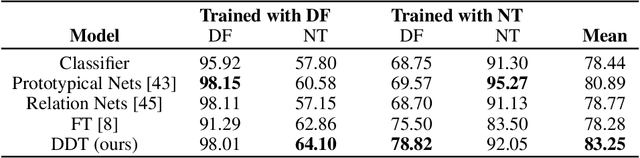

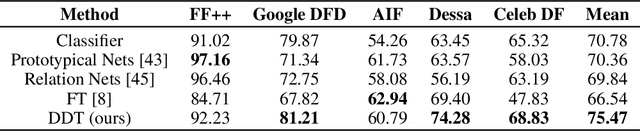
We propose Deep Distribution Transfer(DDT), a new transfer learning approach to address the problem of zero and few-shot transfer in the context of facial forgery detection. We examine how well a model (pre-)trained with one forgery creation method generalizes towards a previously unseen manipulation technique or different dataset. To facilitate this transfer, we introduce a new mixture model-based loss formulation that learns a multi-modal distribution, with modes corresponding to class categories of the underlying data of the source forgery method. Our core idea is to first pre-train an encoder neural network, which maps each mode of this distribution to the respective class labels, i.e., real or fake images in the source domain by minimizing wasserstein distance between them. In order to transfer this model to a new domain, we associate a few target samples with one of the previously trained modes. In addition, we propose a spatial mixup augmentation strategy that further helps generalization across domains. We find this learning strategy to be surprisingly effective at domain transfer compared to a traditional classification or even state-of-the-art domain adaptation/few-shot learning methods. For instance, compared to the best baseline, our method improves the classification accuracy by 4.88% for zero-shot and by 8.38% for the few-shot case transferred from the FaceForensics++ to Dessa dataset.