 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIndoFashion : Apparel Classification for Indian Ethnic Clothes
Apr 06, 2021


Cloth categorization is an important research problem that is used by e-commerce websites for displaying correct products to the end-users. Indian clothes have a large number of clothing categories both for men and women. The traditional Indian clothes like "Saree" and "Dhoti" are worn very differently from western clothes like t-shirts and jeans. Moreover, the style and patterns of ethnic clothes have a very different distribution from western outfits. Thus the models trained on standard cloth datasets fail miserably on ethnic outfits. To address these challenges, we introduce the first large-scale ethnic dataset of over 106k images with 15 different categories for fine-grained classification of Indian ethnic clothes. We gathered a diverse dataset from a large number of Indian e-commerce websites. We then evaluate several baselines for the cloth classification task on our dataset. In the end, we obtain 88.43% classification accuracy. We hope that our dataset would foster research in the development of several algorithms such as cloth classification, landmark detection, especially for ethnic clothes.
Heuristics2Annotate: Efficient Annotation of Large-Scale Marathon Dataset For Bounding Box Regression
Apr 06, 2021
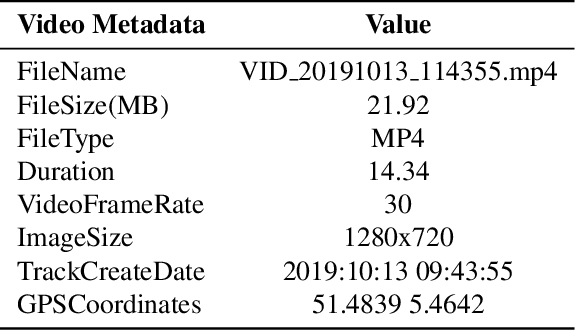
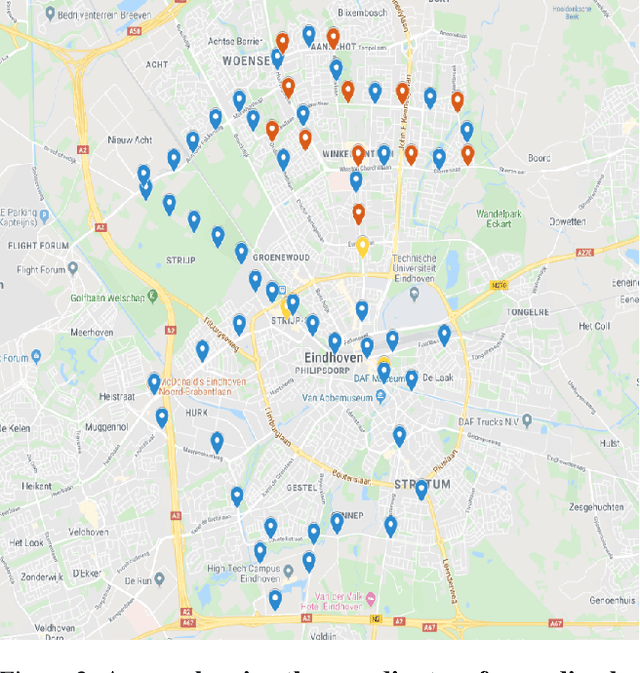
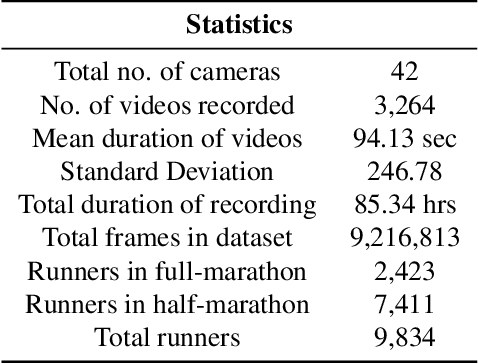
Annotating a large-scale in-the-wild person re-identification dataset especially of marathon runners is a challenging task. The variations in the scenarios such as camera viewpoints, resolution, occlusion, and illumination make the problem non-trivial. Manually annotating bounding boxes in such large-scale datasets is cost-inefficient. Additionally, due to crowdedness and occlusion in the videos, aligning the identity of runners across multiple disjoint cameras is a challenge. We collected a novel large-scale in-the-wild video dataset of marathon runners. The dataset consists of hours of recording of thousands of runners captured using 42 hand-held smartphone cameras and covering real-world scenarios. Due to the presence of crowdedness and occlusion in the videos, the annotation of runners becomes a challenging task. We propose a new scheme for tackling the challenges in the annotation of such large dataset. Our technique reduces the overall cost of annotation in terms of time as well as budget. We demonstrate performing fps analysis to reduce the effort and time of annotation. We investigate several annotation methods for efficiently generating tight bounding boxes. Our results prove that interpolating bounding boxes between keyframes is the most efficient method of bounding box generation amongst several other methods and is 3x times faster than the naive baseline method. We introduce a novel way of aligning the identity of runners in disjoint cameras. Our inter-camera alignment tool integrated with the state-of-the-art person re-id system proves to be sufficient and effective in the alignment of the runners across multiple cameras with non-overlapping views. Our proposed framework of annotation reduces the annotation cost of the dataset by a factor of 16x, also effectively aligning 93.64% of the runners in the cross-camera setting.
cGANs for Cartoon to Real-life Images
Jan 24, 2021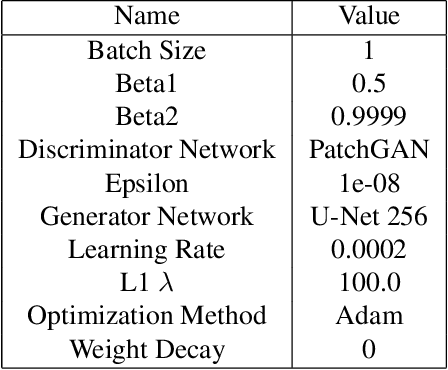

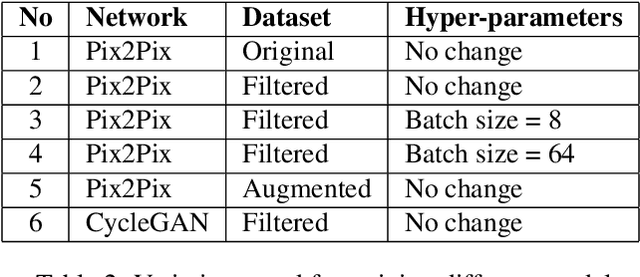

The image-to-image translation is a learning task to establish a visual mapping between an input and output image. The task has several variations differentiated based on the purpose of the translation, such as synthetic to real translation, photo to caricature translation, and many others. The problem has been tackled using different approaches, either through traditional computer vision methods, as well as deep learning approaches in recent trends. One approach currently deemed popular and effective is using the conditional generative adversarial network, also known shortly as cGAN. It is adapted to perform image-to-image translation tasks with typically two networks: a generator and a discriminator. This project aims to evaluate the robustness of the Pix2Pix model by applying the Pix2Pix model to datasets consisting of cartoonized images. Using the Pix2Pix model, it should be possible to train the network to generate real-life images from the cartoonized images.