 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHeart rate estimation in intense exercise videos
Aug 04, 2022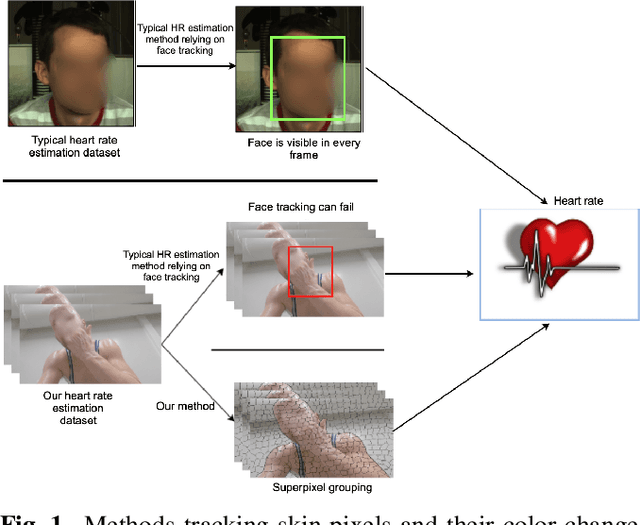

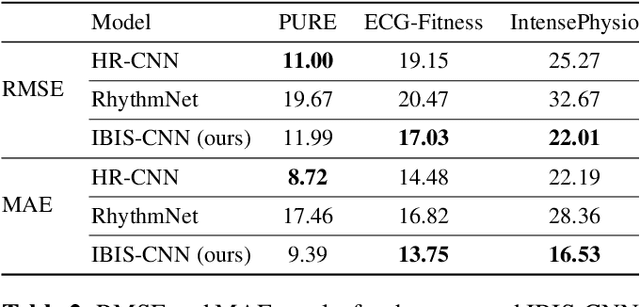
Estimating heart rate from video allows non-contact health monitoring with applications in patient care, human interaction, and sports. Existing work can robustly measure heart rate under some degree of motion by face tracking. However, this is not always possible in unconstrained settings, as the face might be occluded or even outside the camera. Here, we present IntensePhysio: a challenging video heart rate estimation dataset with realistic face occlusions, severe subject motion, and ample heart rate variation. To ensure heart rate variation in a realistic setting we record each subject for around 1-2 hours. The subject is exercising (at a moderate to high intensity) on a cycling ergometer with an attached video camera and is given no instructions regarding positioning or movement. We have 11 subjects, and approximately 20 total hours of video. We show that the existing remote photo-plethysmography methods have difficulty in estimating heart rate in this setting. In addition, we present IBIS-CNN, a new baseline using spatio-temporal superpixels, which improves on existing models by eliminating the need for a visible face/face tracking. We will make the code and data publically available soon.
The Arm-Swing Is Discriminative in Video Gait Recognition for Athlete Re-Identification
Jun 21, 2021

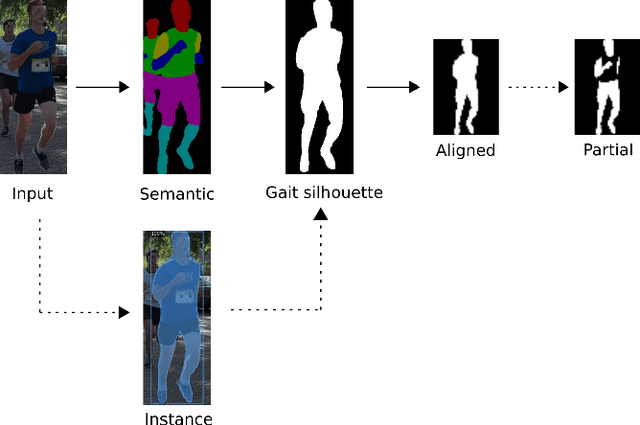
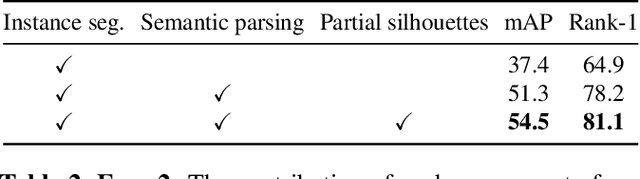
In this paper we evaluate running gait as an attribute for video person re-identification in a long-distance running event. We show that running gait recognition achieves competitive performance compared to appearance-based approaches in the cross-camera retrieval task and that gait and appearance features are complementary to each other. For gait, the arm swing during running is less distinguishable when using binary gait silhouettes, due to ambiguity in the torso region. We propose to use human semantic parsing to create partial gait silhouettes where the torso is left out. Leaving out the torso improves recognition results by allowing the arm swing to be more visible in the frontal and oblique viewing angles, which offers hints that arm swings are somewhat personal. Experiments show an increase of 3.2% mAP on the CampusRun and increased accuracy with 4.8% in the frontal and rear view on CASIA-B, compared to using the full body silhouettes.
Heuristics2Annotate: Efficient Annotation of Large-Scale Marathon Dataset For Bounding Box Regression
Apr 06, 2021
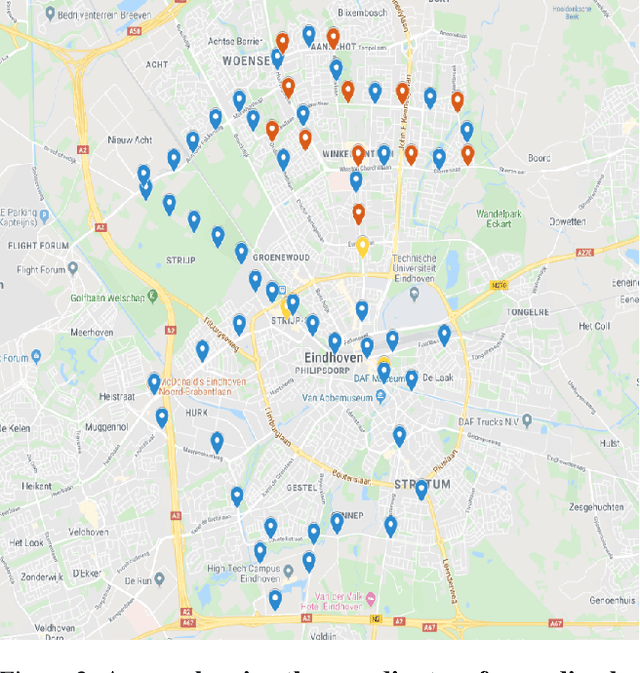
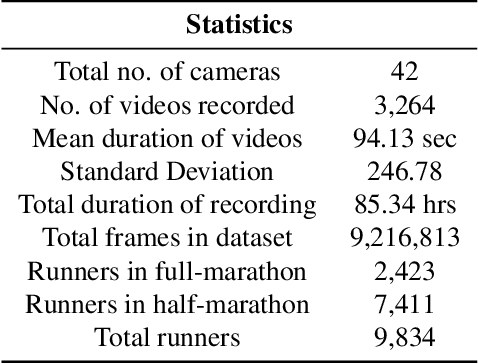
Annotating a large-scale in-the-wild person re-identification dataset especially of marathon runners is a challenging task. The variations in the scenarios such as camera viewpoints, resolution, occlusion, and illumination make the problem non-trivial. Manually annotating bounding boxes in such large-scale datasets is cost-inefficient. Additionally, due to crowdedness and occlusion in the videos, aligning the identity of runners across multiple disjoint cameras is a challenge. We collected a novel large-scale in-the-wild video dataset of marathon runners. The dataset consists of hours of recording of thousands of runners captured using 42 hand-held smartphone cameras and covering real-world scenarios. Due to the presence of crowdedness and occlusion in the videos, the annotation of runners becomes a challenging task. We propose a new scheme for tackling the challenges in the annotation of such large dataset. Our technique reduces the overall cost of annotation in terms of time as well as budget. We demonstrate performing fps analysis to reduce the effort and time of annotation. We investigate several annotation methods for efficiently generating tight bounding boxes. Our results prove that interpolating bounding boxes between keyframes is the most efficient method of bounding box generation amongst several other methods and is 3x times faster than the naive baseline method. We introduce a novel way of aligning the identity of runners in disjoint cameras. Our inter-camera alignment tool integrated with the state-of-the-art person re-id system proves to be sufficient and effective in the alignment of the runners across multiple cameras with non-overlapping views. Our proposed framework of annotation reduces the annotation cost of the dataset by a factor of 16x, also effectively aligning 93.64% of the runners in the cross-camera setting.
Running Event Visualization using Videos from Multiple Cameras
Sep 06, 2019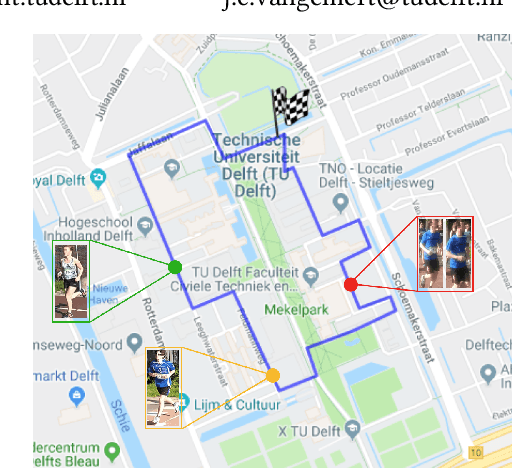
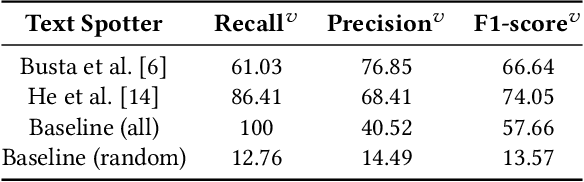

Visualizing the trajectory of multiple runners with videos collected at different points in a race could be useful for sports performance analysis. The videos and the trajectories can also aid in athlete health monitoring. While the runners unique ID and their appearance are distinct, the task is not straightforward because the video data does not contain explicit information as to which runners appear in each of the videos. There is no direct supervision of the model in tracking athletes, only filtering steps to remove irrelevant detections. Other factors of concern include occlusion of runners and harsh illumination. To this end, we identify two methods for runner identification at different points of the event, for determining their trajectory. One is scene text detection which recognizes the runners by detecting a unique 'bib number' attached to their clothes and the other is person re-identification which detects the runners based on their appearance. We train our method without ground truth but to evaluate the proposed methods, we create a ground truth database which consists of video and frame interval information where the runners appear. The videos in the dataset was recorded by nine cameras at different locations during the a marathon event. This data is annotated with bib numbers of runners appearing in each video. The bib numbers of runners known to occur in the frame are used to filter irrelevant text and numbers detected. Except for this filtering step, no supervisory signal is used. The experimental evidence shows that the scene text recognition method achieves an F1-score of 74. Combining the two methods, that is - using samples collected by text spotter to train the re-identification model yields a higher F1-score of 85.8. Re-training the person re-identification model with identified inliers yields a slight improvement in performance(F1 score of 87.8).