 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFedPM: Federated Learning Using Second-order Optimization with Preconditioned Mixing of Local Parameters
Nov 12, 2025We propose Federated Preconditioned Mixing (FedPM), a novel Federated Learning (FL) method that leverages second-order optimization. Prior methods--such as LocalNewton, LTDA, and FedSophia--have incorporated second-order optimization in FL by performing iterative local updates on clients and applying simple mixing of local parameters on the server. However, these methods often suffer from drift in local preconditioners, which significantly disrupts the convergence of parameter training, particularly in heterogeneous data settings. To overcome this issue, we refine the update rules by decomposing the ideal second-order update--computed using globally preconditioned global gradients--into parameter mixing on the server and local parameter updates on clients. As a result, our FedPM introduces preconditioned mixing of local parameters on the server, effectively mitigating drift in local preconditioners. We provide a theoretical convergence analysis demonstrating a superlinear rate for strongly convex objectives in scenarios involving a single local update. To demonstrate the practical benefits of FedPM, we conducted extensive experiments. The results showed significant improvements with FedPM in the test accuracy compared to conventional methods incorporating simple mixing, fully leveraging the potential of second-order optimization.
High Quality Diffusion Distillation on a Single GPU with Relative and Absolute Position Matching
Mar 26, 2025We introduce relative and absolute position matching (RAPM), a diffusion distillation method resulting in high quality generation that can be trained efficiently on a single GPU. Recent diffusion distillation research has achieved excellent results for high-resolution text-to-image generation with methods such as phased consistency models (PCM) and improved distribution matching distillation (DMD2). However, these methods generally require many GPUs (e.g.~8-64) and significant batchsizes (e.g.~128-2048) during training, resulting in memory and compute requirements that are beyond the resources of some researchers. RAPM provides effective single-GPU diffusion distillation training with a batchsize of 1. The new method attempts to mimic the sampling trajectories of the teacher model by matching the relative and absolute positions. The design of relative positions is inspired by PCM. Two discriminators are introduced accordingly in RAPM, one for matching relative positions and the other for absolute positions. Experimental results on StableDiffusion (SD) V1.5 and SDXL indicate that RAPM with 4 timesteps produces comparable FID scores as the best method with 1 timestep under very limited computational resources.
NeurIPS 2023 Competition: Privacy Preserving Federated Learning Document VQA
Nov 06, 2024



The Privacy Preserving Federated Learning Document VQA (PFL-DocVQA) competition challenged the community to develop provably private and communication-efficient solutions in a federated setting for a real-life use case: invoice processing. The competition introduced a dataset of real invoice documents, along with associated questions and answers requiring information extraction and reasoning over the document images. Thereby, it brings together researchers and expertise from the document analysis, privacy, and federated learning communities. Participants fine-tuned a pre-trained, state-of-the-art Document Visual Question Answering model provided by the organizers for this new domain, mimicking a typical federated invoice processing setup. The base model is a multi-modal generative language model, and sensitive information could be exposed through either the visual or textual input modality. Participants proposed elegant solutions to reduce communication costs while maintaining a minimum utility threshold in track 1 and to protect all information from each document provider using differential privacy in track 2. The competition served as a new testbed for developing and testing private federated learning methods, simultaneously raising awareness about privacy within the document image analysis and recognition community. Ultimately, the competition analysis provides best practices and recommendations for successfully running privacy-focused federated learning challenges in the future.
Polyak Meets Parameter-free Clipped Gradient Descent
May 23, 2024
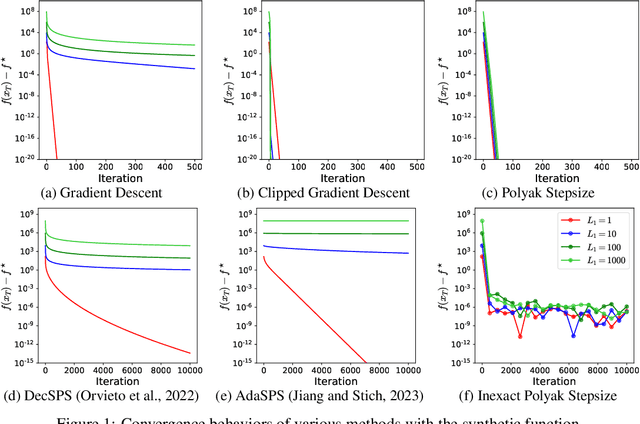
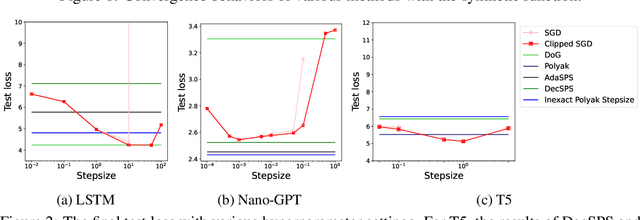
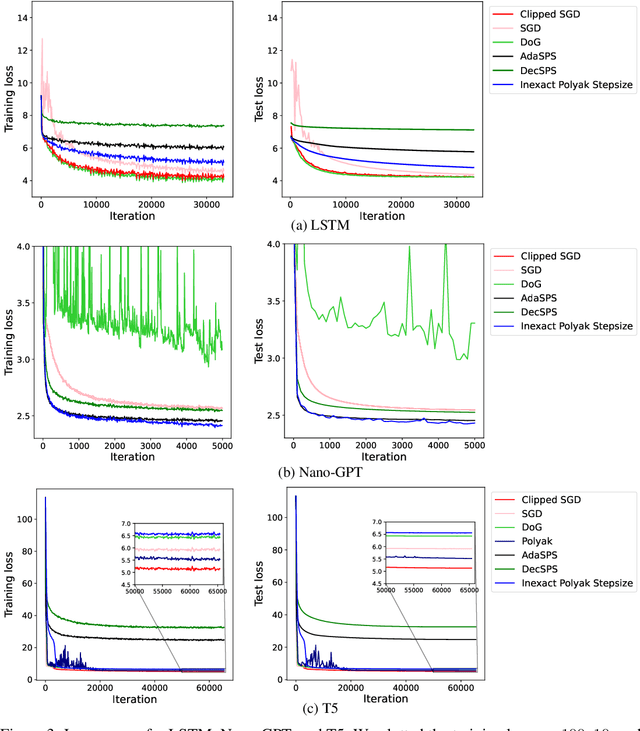
Gradient descent and its variants are de facto standard algorithms for training machine learning models. As gradient descent is sensitive to its hyperparameters, we need to tune the hyperparameters carefully using a grid search, but it is time-consuming, especially when multiple hyperparameters exist. Recently, parameter-free methods that adjust the hyperparameters on the fly have been studied. However, the existing work only studied parameter-free methods for the stepsize, and parameter-free methods for other hyperparameters have not been explored. For instance, the gradient clipping threshold is also a crucial hyperparameter in addition to the stepsize to prevent gradient explosion issues, but none of the existing studies investigated the parameter-free methods for clipped gradient descent. In this work, we study the parameter-free methods for clipped gradient descent. Specifically, we propose Inexact Polyak Stepsize, which converges to the optimal solution without any hyperparameters tuning, and its convergence rate is asymptotically independent of L under L-smooth and $(L_0, L_1)$-smooth assumptions of the loss function as that of clipped gradient descent with well-tuned hyperparameters. We numerically validated our convergence results using a synthetic function and demonstrated the effectiveness of our proposed methods using LSTM, Nano-GPT, and T5.
Optimal Transport with Cyclic Symmetry
Nov 22, 2023


We propose novel fast algorithms for optimal transport (OT) utilizing a cyclic symmetry structure of input data. Such OT with cyclic symmetry appears universally in various real-world examples: image processing, urban planning, and graph processing. Our main idea is to reduce OT to a small optimization problem that has significantly fewer variables by utilizing cyclic symmetry and various optimization techniques. On the basis of this reduction, our algorithms solve the small optimization problem instead of the original OT. As a result, our algorithms obtain the optimal solution and the objective function value of the original OT faster than solving the original OT directly. In this paper, our focus is on two crucial OT formulations: the linear programming OT (LOT) and the strongly convex-regularized OT, which includes the well-known entropy-regularized OT (EROT). Experiments show the effectiveness of our algorithms for LOT and EROT in synthetic/real-world data that has a strict/approximate cyclic symmetry structure. Through theoretical and experimental results, this paper successfully introduces the concept of symmetry into the OT research field for the first time.
Embarrassingly Simple Text Watermarks
Oct 13, 2023



We propose Easymark, a family of embarrassingly simple yet effective watermarks. Text watermarking is becoming increasingly important with the advent of Large Language Models (LLM). LLMs can generate texts that cannot be distinguished from human-written texts. This is a serious problem for the credibility of the text. Easymark is a simple yet effective solution to this problem. Easymark can inject a watermark without changing the meaning of the text at all while a validator can detect if a text was generated from a system that adopted Easymark or not with high credibility. Easymark is extremely easy to implement so that it only requires a few lines of code. Easymark does not require access to LLMs, so it can be implemented on the user-side when the LLM providers do not offer watermarked LLMs. In spite of its simplicity, it achieves higher detection accuracy and BLEU scores than the state-of-the-art text watermarking methods. We also prove the impossibility theorem of perfect watermarking, which is valuable in its own right. This theorem shows that no matter how sophisticated a watermark is, a malicious user could remove it from the text, which motivate us to use a simple watermark such as Easymark. We carry out experiments with LLM-generated texts and confirm that Easymark can be detected reliably without any degradation of BLEU and perplexity, and outperform state-of-the-art watermarks in terms of both quality and reliability.
Necessary and Sufficient Watermark for Large Language Models
Oct 02, 2023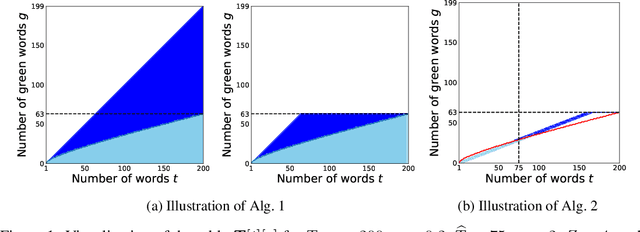


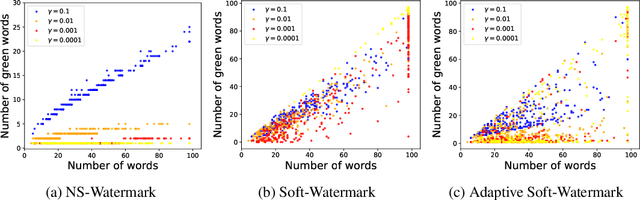
In recent years, large language models (LLMs) have achieved remarkable performances in various NLP tasks. They can generate texts that are indistinguishable from those written by humans. Such remarkable performance of LLMs increases their risk of being used for malicious purposes, such as generating fake news articles. Therefore, it is necessary to develop methods for distinguishing texts written by LLMs from those written by humans. Watermarking is one of the most powerful methods for achieving this. Although existing watermarking methods have successfully detected texts generated by LLMs, they significantly degrade the quality of the generated texts. In this study, we propose the Necessary and Sufficient Watermark (NS-Watermark) for inserting watermarks into generated texts without degrading the text quality. More specifically, we derive minimum constraints required to be imposed on the generated texts to distinguish whether LLMs or humans write the texts. Then, we formulate the NS-Watermark as a constrained optimization problem and propose an efficient algorithm to solve it. Through the experiments, we demonstrate that the NS-Watermark can generate more natural texts than existing watermarking methods and distinguish more accurately between texts written by LLMs and those written by humans. Especially in machine translation tasks, the NS-Watermark can outperform the existing watermarking method by up to 30 BLEU scores.
Beyond Exponential Graph: Communication-Efficient Topologies for Decentralized Learning via Finite-time Convergence
May 19, 2023Decentralized learning has recently been attracting increasing attention for its applications in parallel computation and privacy preservation. Many recent studies stated that the underlying network topology with a faster consensus rate (a.k.a. spectral gap) leads to a better convergence rate and accuracy for decentralized learning. However, a topology with a fast consensus rate, e.g., the exponential graph, generally has a large maximum degree, which incurs significant communication costs. Thus, seeking topologies with both a fast consensus rate and small maximum degree is important. In this study, we propose a novel topology combining both a fast consensus rate and small maximum degree called the Base-$(k + 1)$ Graph. Unlike the existing topologies, the Base-$(k + 1)$ Graph enables all nodes to reach the exact consensus after a finite number of iterations for any number of nodes and maximum degree k. Thanks to this favorable property, the Base-$(k + 1)$ Graph endows Decentralized SGD (DSGD) with both a faster convergence rate and more communication efficiency than the exponential graph. We conducted experiments with various topologies, demonstrating that the Base-$(k + 1)$ Graph enables various decentralized learning methods to achieve higher accuracy with better communication efficiency than the existing topologies.
Momentum Tracking: Momentum Acceleration for Decentralized Deep Learning on Heterogeneous Data
Sep 30, 2022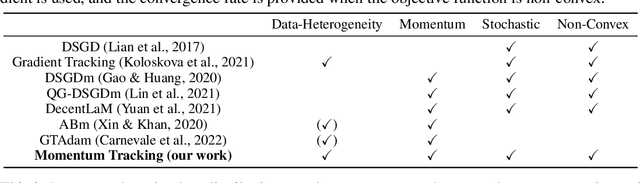
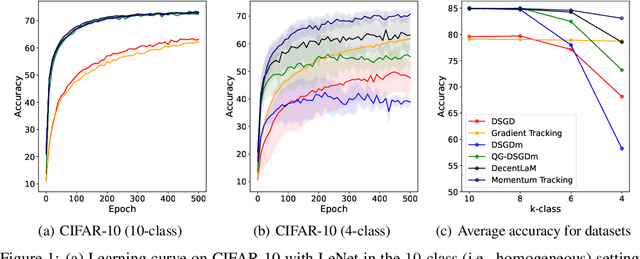
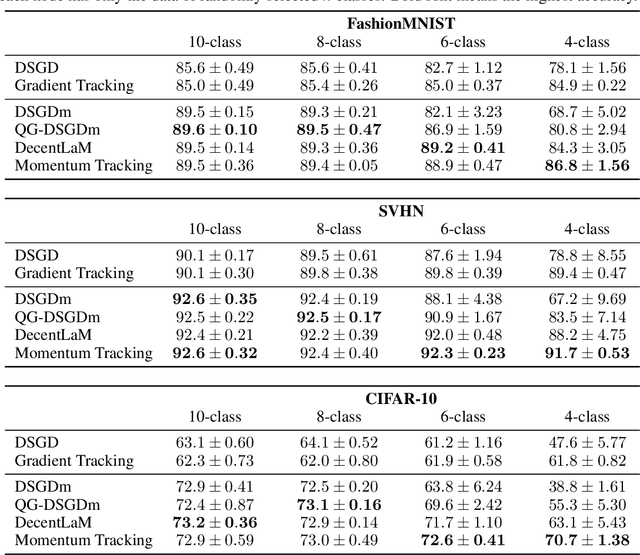
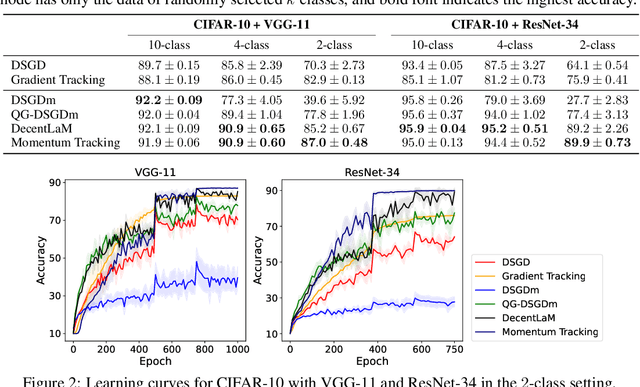
SGD with momentum acceleration is one of the key components for improving the performance of neural networks. For decentralized learning, a straightforward approach using momentum acceleration is Distributed SGD (DSGD) with momentum acceleration (DSGDm). However, DSGDm performs worse than DSGD when the data distributions are statistically heterogeneous. Recently, several studies have addressed this issue and proposed methods with momentum acceleration that are more robust to data heterogeneity than DSGDm, although their convergence rates remain dependent on data heterogeneity and decrease when the data distributions are heterogeneous. In this study, we propose Momentum Tracking, which is a method with momentum acceleration whose convergence rate is proven to be independent of data heterogeneity. More specifically, we analyze the convergence rate of Momentum Tracking in the standard deep learning setting, where the objective function is non-convex and the stochastic gradient is used. Then, we identify that it is independent of data heterogeneity for any momentum coefficient $\beta\in [0, 1)$. Through image classification tasks, we demonstrate that Momentum Tracking is more robust to data heterogeneity than the existing decentralized learning methods with momentum acceleration and can consistently outperform these existing methods when the data distributions are heterogeneous.
Theoretical Analysis of Primal-Dual Algorithm for Non-Convex Stochastic Decentralized Optimization
May 23, 2022
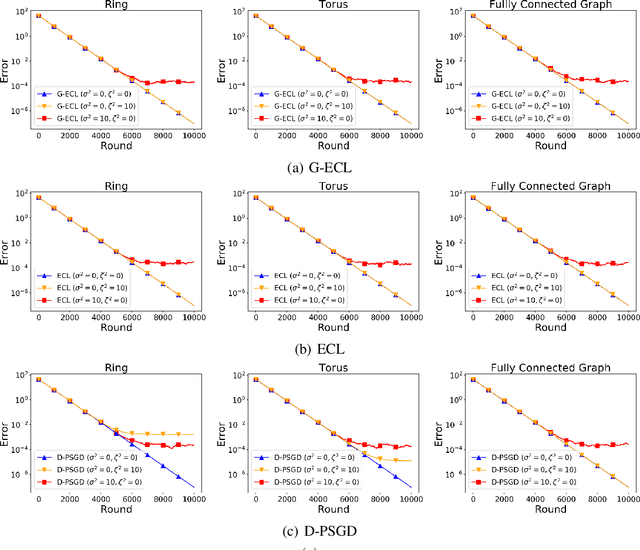
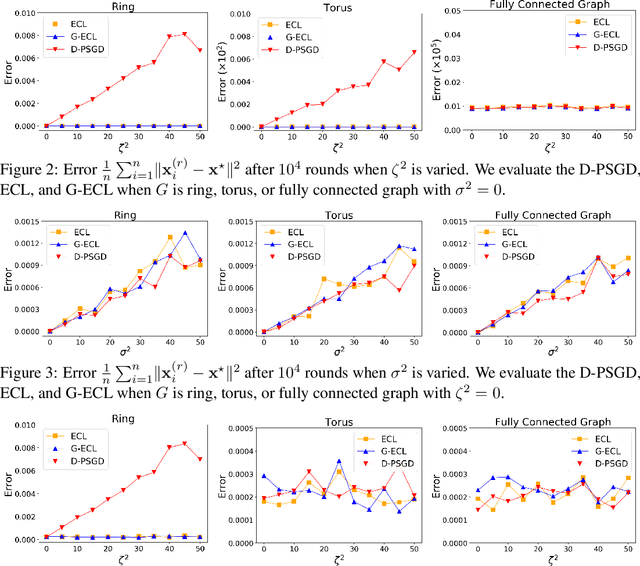
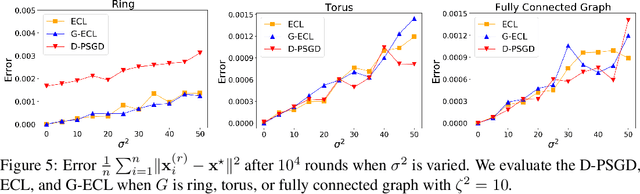
In recent years, decentralized learning has emerged as a powerful tool not only for large-scale machine learning, but also for preserving privacy. One of the key challenges in decentralized learning is that the data distribution held by each node is statistically heterogeneous. To address this challenge, the primal-dual algorithm called the Edge-Consensus Learning (ECL) was proposed and was experimentally shown to be robust to the heterogeneity of data distributions. However, the convergence rate of the ECL is provided only when the objective function is convex, and has not been shown in a standard machine learning setting where the objective function is non-convex. Furthermore, the intuitive reason why the ECL is robust to the heterogeneity of data distributions has not been investigated. In this work, we first investigate the relationship between the ECL and Gossip algorithm and show that the update formulas of the ECL can be regarded as correcting the local stochastic gradient in the Gossip algorithm. Then, we propose the Generalized ECL (G-ECL), which contains the ECL as a special case, and provide the convergence rates of the G-ECL in both (strongly) convex and non-convex settings, which do not depend on the heterogeneity of data distributions. Through synthetic experiments, we demonstrate that the numerical results of both the G-ECL and ECL coincide with the convergence rate of the G-ECL.