 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDocMIA: Document-Level Membership Inference Attacks against DocVQA Models
Feb 06, 2025



Document Visual Question Answering (DocVQA) has introduced a new paradigm for end-to-end document understanding, and quickly became one of the standard benchmarks for multimodal LLMs. Automating document processing workflows, driven by DocVQA models, presents significant potential for many business sectors. However, documents tend to contain highly sensitive information, raising concerns about privacy risks associated with training such DocVQA models. One significant privacy vulnerability, exploited by the membership inference attack, is the possibility for an adversary to determine if a particular record was part of the model's training data. In this paper, we introduce two novel membership inference attacks tailored specifically to DocVQA models. These attacks are designed for two different adversarial scenarios: a white-box setting, where the attacker has full access to the model architecture and parameters, and a black-box setting, where only the model's outputs are available. Notably, our attacks assume the adversary lacks access to auxiliary datasets, which is more realistic in practice but also more challenging. Our unsupervised methods outperform existing state-of-the-art membership inference attacks across a variety of DocVQA models and datasets, demonstrating their effectiveness and highlighting the privacy risks in this domain.
DP-2Stage: Adapting Language Models as Differentially Private Tabular Data Generators
Dec 03, 2024



Generating tabular data under differential privacy (DP) protection ensures theoretical privacy guarantees but poses challenges for training machine learning models, primarily due to the need to capture complex structures under noisy supervision signals. Recently, pre-trained Large Language Models (LLMs) -- even those at the scale of GPT-2 -- have demonstrated great potential in synthesizing tabular data. However, their applications under DP constraints remain largely unexplored. In this work, we address this gap by applying DP techniques to the generation of synthetic tabular data. Our findings shows that LLMs face difficulties in generating coherent text when fine-tuned with DP, as privacy budgets are inefficiently allocated to non-private elements like table structures. To overcome this, we propose \ours, a two-stage fine-tuning framework for differentially private tabular data generation. The first stage involves non-private fine-tuning on a pseudo dataset, followed by DP fine-tuning on a private dataset. Our empirical results show that this approach improves performance across various settings and metrics compared to directly fine-tuned LLMs in DP contexts. We release our code and setup at https://github.com/tejuafonja/DP-2Stage.
NeurIPS 2023 Competition: Privacy Preserving Federated Learning Document VQA
Nov 06, 2024



The Privacy Preserving Federated Learning Document VQA (PFL-DocVQA) competition challenged the community to develop provably private and communication-efficient solutions in a federated setting for a real-life use case: invoice processing. The competition introduced a dataset of real invoice documents, along with associated questions and answers requiring information extraction and reasoning over the document images. Thereby, it brings together researchers and expertise from the document analysis, privacy, and federated learning communities. Participants fine-tuned a pre-trained, state-of-the-art Document Visual Question Answering model provided by the organizers for this new domain, mimicking a typical federated invoice processing setup. The base model is a multi-modal generative language model, and sensitive information could be exposed through either the visual or textual input modality. Participants proposed elegant solutions to reduce communication costs while maintaining a minimum utility threshold in track 1 and to protect all information from each document provider using differential privacy in track 2. The competition served as a new testbed for developing and testing private federated learning methods, simultaneously raising awareness about privacy within the document image analysis and recognition community. Ultimately, the competition analysis provides best practices and recommendations for successfully running privacy-focused federated learning challenges in the future.
Towards Biologically Plausible and Private Gene Expression Data Generation
Feb 07, 2024
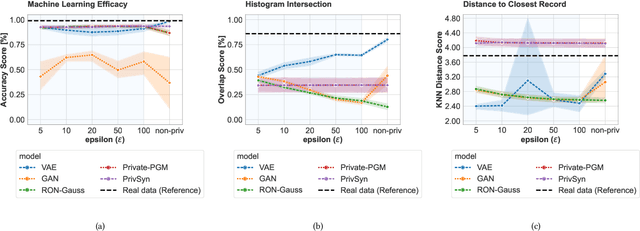

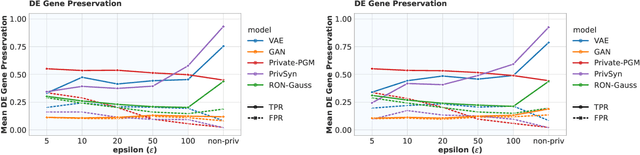
Generative models trained with Differential Privacy (DP) are becoming increasingly prominent in the creation of synthetic data for downstream applications. Existing literature, however, primarily focuses on basic benchmarking datasets and tends to report promising results only for elementary metrics and relatively simple data distributions. In this paper, we initiate a systematic analysis of how DP generative models perform in their natural application scenarios, specifically focusing on real-world gene expression data. We conduct a comprehensive analysis of five representative DP generation methods, examining them from various angles, such as downstream utility, statistical properties, and biological plausibility. Our extensive evaluation illuminates the unique characteristics of each DP generation method, offering critical insights into the strengths and weaknesses of each approach, and uncovering intriguing possibilities for future developments. Perhaps surprisingly, our analysis reveals that most methods are capable of achieving seemingly reasonable downstream utility, according to the standard evaluation metrics considered in existing literature. Nevertheless, we find that none of the DP methods are able to accurately capture the biological characteristics of the real dataset. This observation suggests a potential over-optimistic assessment of current methodologies in this field and underscores a pressing need for future enhancements in model design.
Privacy-Aware Document Visual Question Answering
Dec 15, 2023

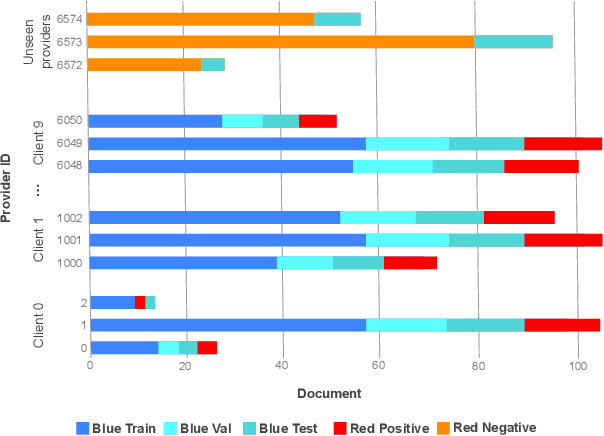

Document Visual Question Answering (DocVQA) is a fast growing branch of document understanding. Despite the fact that documents contain sensitive or copyrighted information, none of the current DocVQA methods offers strong privacy guarantees. In this work, we explore privacy in the domain of DocVQA for the first time. We highlight privacy issues in state of the art multi-modal LLM models used for DocVQA, and explore possible solutions. Specifically, we focus on the invoice processing use case as a realistic, widely used scenario for document understanding, and propose a large scale DocVQA dataset comprising invoice documents and associated questions and answers. We employ a federated learning scheme, that reflects the real-life distribution of documents in different businesses, and we explore the use case where the ID of the invoice issuer is the sensitive information to be protected. We demonstrate that non-private models tend to memorise, behaviour that can lead to exposing private information. We then evaluate baseline training schemes employing federated learning and differential privacy in this multi-modal scenario, where the sensitive information might be exposed through any of the two input modalities: vision (document image) or language (OCR tokens). Finally, we design an attack exploiting the memorisation effect of the model, and demonstrate its effectiveness in probing different DocVQA models.
A Unified View of Differentially Private Deep Generative Modeling
Sep 27, 2023
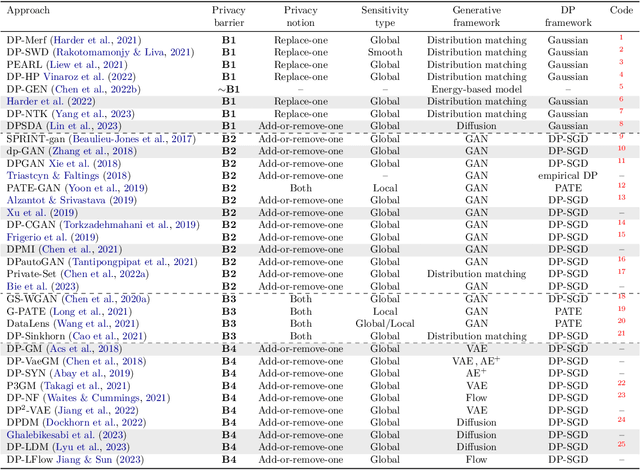
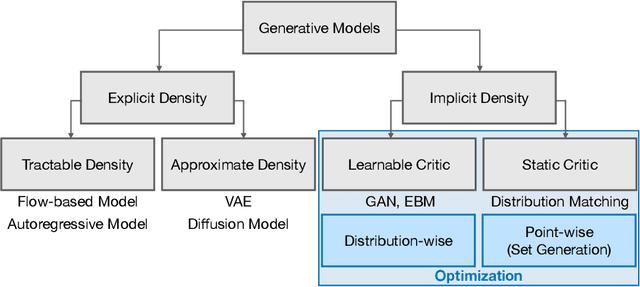
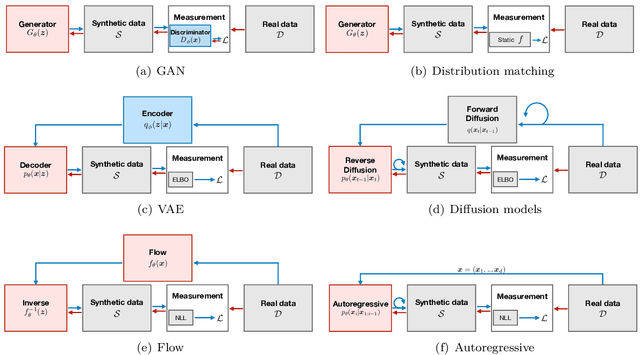
The availability of rich and vast data sources has greatly advanced machine learning applications in various domains. However, data with privacy concerns comes with stringent regulations that frequently prohibited data access and data sharing. Overcoming these obstacles in compliance with privacy considerations is key for technological progress in many real-world application scenarios that involve privacy sensitive data. Differentially private (DP) data publishing provides a compelling solution, where only a sanitized form of the data is publicly released, enabling privacy-preserving downstream analysis and reproducible research in sensitive domains. In recent years, various approaches have been proposed for achieving privacy-preserving high-dimensional data generation by private training on top of deep neural networks. In this paper, we present a novel unified view that systematizes these approaches. Our view provides a joint design space for systematically deriving methods that cater to different use cases. We then discuss the strengths, limitations, and inherent correlations between different approaches, aiming to shed light on crucial aspects and inspire future research. We conclude by presenting potential paths forward for the field of DP data generation, with the aim of steering the community toward making the next important steps in advancing privacy-preserving learning.
Client-specific Property Inference against Secure Aggregation in Federated Learning
Mar 07, 2023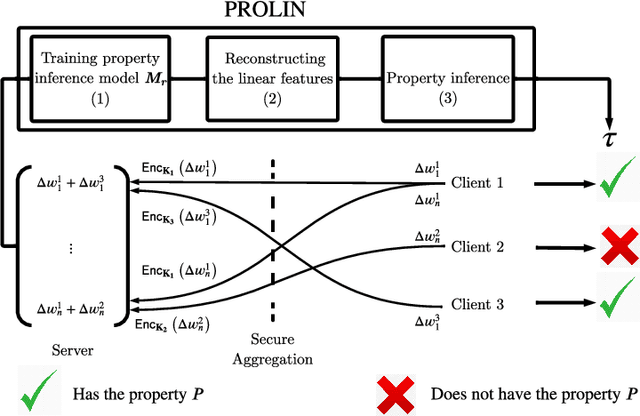

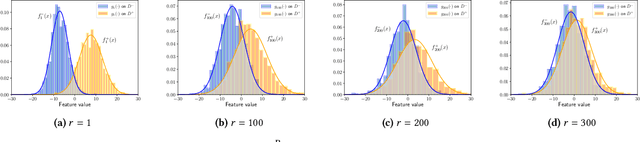
Federated learning has become a widely used paradigm for collaboratively training a common model among different participants with the help of a central server that coordinates the training. Although only the model parameters or other model updates are exchanged during the federated training instead of the participant's data, many attacks have shown that it is still possible to infer sensitive information such as membership, property, or outright reconstruction of participant data. Although differential privacy is considered an effective solution to protect against privacy attacks, it is also criticized for its negative effect on utility. Another possible defense is to use secure aggregation which allows the server to only access the aggregated update instead of each individual one, and it is often more appealing because it does not degrade model quality. However, combining only the aggregated updates, which are generated by a different composition of clients in every round, may still allow the inference of some client-specific information. In this paper, we show that simple linear models can effectively capture client-specific properties only from the aggregated model updates due to the linearity of aggregation. We formulate an optimization problem across different rounds in order to infer a tested property of every client from the output of the linear models, for example, whether they have a specific sample in their training data (membership inference) or whether they misbehave and attempt to degrade the performance of the common model by poisoning attacks. Our reconstruction technique is completely passive and undetectable. We demonstrate the efficacy of our approach on several scenarios which shows that secure aggregation provides very limited privacy guarantees in practice. The source code will be released upon publication.
Fed-GLOSS-DP: Federated, Global Learning using Synthetic Sets with Record Level Differential Privacy
Feb 02, 2023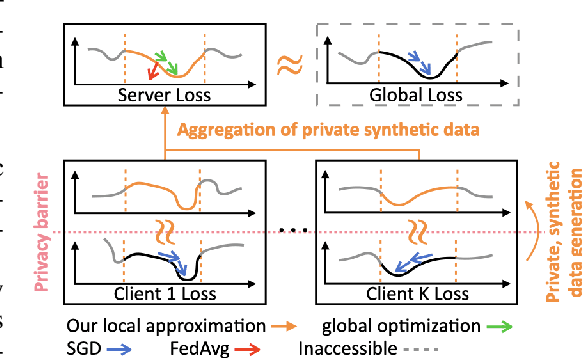

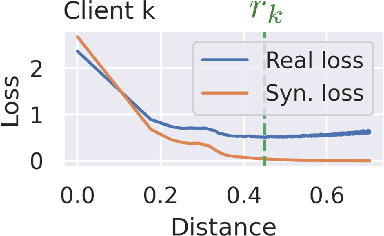

This work proposes Fed-GLOSS-DP, a novel approach to privacy-preserving learning that uses synthetic data to train federated models. In our approach, the server recovers an approximation of the global loss landscape in a local neighborhood based on synthetic samples received from the clients. In contrast to previous, point-wise, gradient-based, linear approximation (such as FedAvg), our formulation enables a type of global optimization that is particularly beneficial in non-IID federated settings. We also present how it rigorously complements record-level differential privacy. Extensive results show that our novel formulation gives rise to considerable improvements in terms of convergence speed and communication costs. We argue that our new approach to federated learning can provide a potential path toward reconciling privacy and accountability by sending differentially private, synthetic data instead of gradient updates. The source code will be released upon publication.
Private Set Generation with Discriminative Information
Nov 07, 2022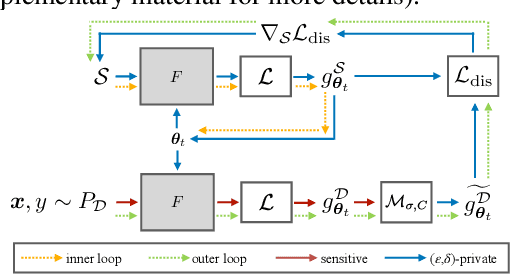
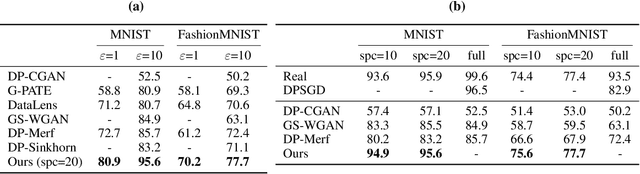
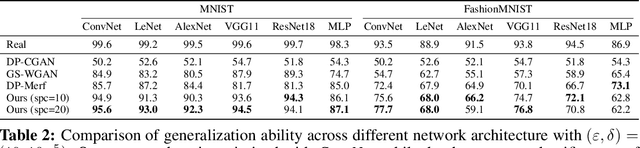
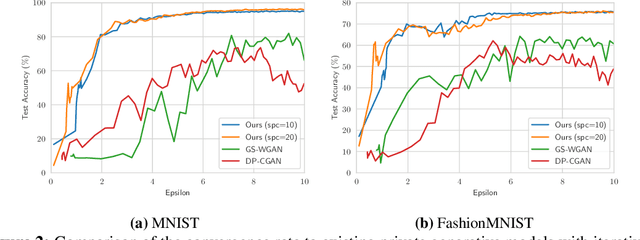
Differentially private data generation techniques have become a promising solution to the data privacy challenge -- it enables sharing of data while complying with rigorous privacy guarantees, which is essential for scientific progress in sensitive domains. Unfortunately, restricted by the inherent complexity of modeling high-dimensional distributions, existing private generative models are struggling with the utility of synthetic samples. In contrast to existing works that aim at fitting the complete data distribution, we directly optimize for a small set of samples that are representative of the distribution under the supervision of discriminative information from downstream tasks, which is generally an easier task and more suitable for private training. Our work provides an alternative view for differentially private generation of high-dimensional data and introduces a simple yet effective method that greatly improves the sample utility of state-of-the-art approaches.
* NeurIPS 2022, 19 pages
Practical Challenges in Differentially-Private Federated Survival Analysis of Medical Data
Feb 08, 2022
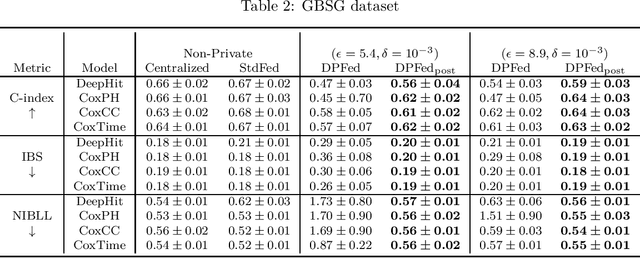
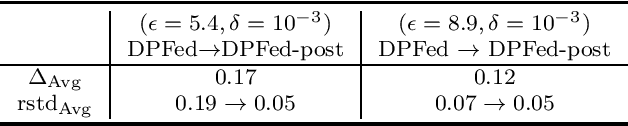
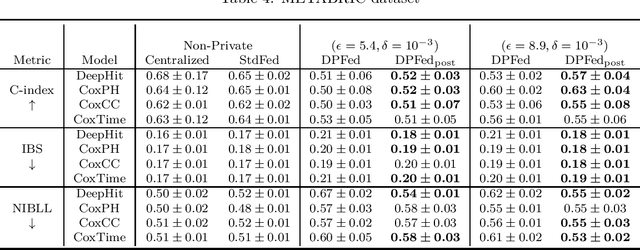
Survival analysis or time-to-event analysis aims to model and predict the time it takes for an event of interest to happen in a population or an individual. In the medical context this event might be the time of dying, metastasis, recurrence of cancer, etc. Recently, the use of neural networks that are specifically designed for survival analysis has become more popular and an attractive alternative to more traditional methods. In this paper, we take advantage of the inherent properties of neural networks to federate the process of training of these models. This is crucial in the medical domain since data is scarce and collaboration of multiple health centers is essential to make a conclusive decision about the properties of a treatment or a disease. To ensure the privacy of the datasets, it is common to utilize differential privacy on top of federated learning. Differential privacy acts by introducing random noise to different stages of training, thus making it harder for an adversary to extract details about the data. However, in the realistic setting of small medical datasets and only a few data centers, this noise makes it harder for the models to converge. To address this problem, we propose DPFed-post which adds a post-processing stage to the private federated learning scheme. This extra step helps to regulate the magnitude of the noisy average parameter update and easier convergence of the model. For our experiments, we choose 3 real-world datasets in the realistic setting when each health center has only a few hundred records, and we show that DPFed-post successfully increases the performance of the models by an average of up to $17\%$ compared to the standard differentially private federated learning scheme.