 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeClient-specific Property Inference against Secure Aggregation in Federated Learning
Paper and Code
Mar 07, 2023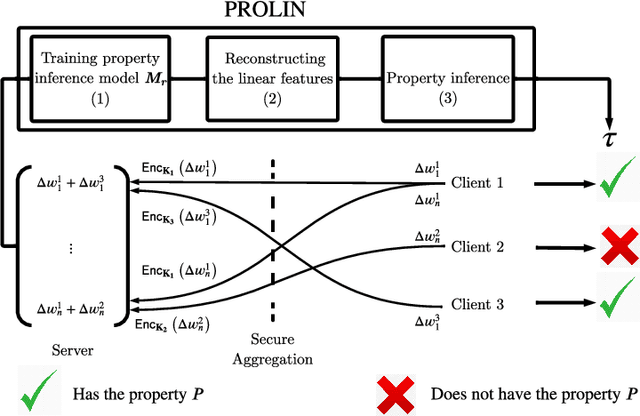

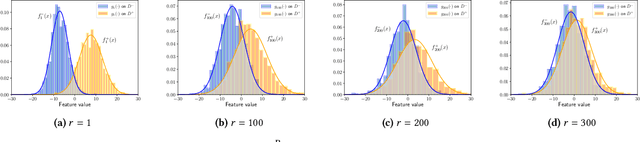
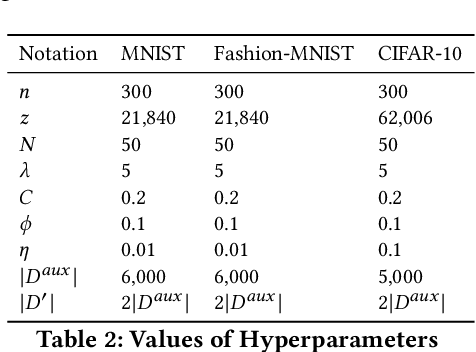
Federated learning has become a widely used paradigm for collaboratively training a common model among different participants with the help of a central server that coordinates the training. Although only the model parameters or other model updates are exchanged during the federated training instead of the participant's data, many attacks have shown that it is still possible to infer sensitive information such as membership, property, or outright reconstruction of participant data. Although differential privacy is considered an effective solution to protect against privacy attacks, it is also criticized for its negative effect on utility. Another possible defense is to use secure aggregation which allows the server to only access the aggregated update instead of each individual one, and it is often more appealing because it does not degrade model quality. However, combining only the aggregated updates, which are generated by a different composition of clients in every round, may still allow the inference of some client-specific information. In this paper, we show that simple linear models can effectively capture client-specific properties only from the aggregated model updates due to the linearity of aggregation. We formulate an optimization problem across different rounds in order to infer a tested property of every client from the output of the linear models, for example, whether they have a specific sample in their training data (membership inference) or whether they misbehave and attempt to degrade the performance of the common model by poisoning attacks. Our reconstruction technique is completely passive and undetectable. We demonstrate the efficacy of our approach on several scenarios which shows that secure aggregation provides very limited privacy guarantees in practice. The source code will be released upon publication.