 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStealix: Model Stealing via Prompt Evolution
Jun 06, 2025Model stealing poses a significant security risk in machine learning by enabling attackers to replicate a black-box model without access to its training data, thus jeopardizing intellectual property and exposing sensitive information. Recent methods that use pre-trained diffusion models for data synthesis improve efficiency and performance but rely heavily on manually crafted prompts, limiting automation and scalability, especially for attackers with little expertise. To assess the risks posed by open-source pre-trained models, we propose a more realistic threat model that eliminates the need for prompt design skills or knowledge of class names. In this context, we introduce Stealix, the first approach to perform model stealing without predefined prompts. Stealix uses two open-source pre-trained models to infer the victim model's data distribution, and iteratively refines prompts through a genetic algorithm, progressively improving the precision and diversity of synthetic images. Our experimental results demonstrate that Stealix significantly outperforms other methods, even those with access to class names or fine-grained prompts, while operating under the same query budget. These findings highlight the scalability of our approach and suggest that the risks posed by pre-trained generative models in model stealing may be greater than previously recognized.
DP-2Stage: Adapting Language Models as Differentially Private Tabular Data Generators
Dec 03, 2024



Generating tabular data under differential privacy (DP) protection ensures theoretical privacy guarantees but poses challenges for training machine learning models, primarily due to the need to capture complex structures under noisy supervision signals. Recently, pre-trained Large Language Models (LLMs) -- even those at the scale of GPT-2 -- have demonstrated great potential in synthesizing tabular data. However, their applications under DP constraints remain largely unexplored. In this work, we address this gap by applying DP techniques to the generation of synthetic tabular data. Our findings shows that LLMs face difficulties in generating coherent text when fine-tuned with DP, as privacy budgets are inefficiently allocated to non-private elements like table structures. To overcome this, we propose \ours, a two-stage fine-tuning framework for differentially private tabular data generation. The first stage involves non-private fine-tuning on a pseudo dataset, followed by DP fine-tuning on a private dataset. Our empirical results show that this approach improves performance across various settings and metrics compared to directly fine-tuned LLMs in DP contexts. We release our code and setup at https://github.com/tejuafonja/DP-2Stage.
Language Models as Zero-shot Lossless Gradient Compressors: Towards General Neural Parameter Prior Models
Sep 26, 2024Despite the widespread use of statistical prior models in various fields, such models for neural network gradients have long been overlooked. The inherent challenge stems from their high-dimensional structures and complex interdependencies, which complicate effective modeling. In this work, we demonstrate the potential of large language models (LLMs) to act as gradient priors in a zero-shot setting. We examine the property by considering lossless gradient compression -- a critical application in distributed learning -- that depends heavily on precise probability modeling. To achieve this, we introduce LM-GC, a novel method that integrates LLMs with arithmetic coding. Our technique converts plain gradients into text-like formats, enhancing token efficiency by up to 38 times compared to their plain representations. We ensure that this data conversion maintains a close alignment with the structure of plain gradients and the symbols commonly recognized by LLMs. Our experiments indicate that LM-GC surpasses existing state-of-the-art lossless compression methods, improving compression rates by 10\% up to 17.2\% across various datasets and architectures. Additionally, our approach shows promising compatibility with lossy compression techniques such as quantization and sparsification. These findings highlight the significant potential of LLMs as a model for effectively handling gradients. We will release the source code upon publication.
Fed-GLOSS-DP: Federated, Global Learning using Synthetic Sets with Record Level Differential Privacy
Feb 02, 2023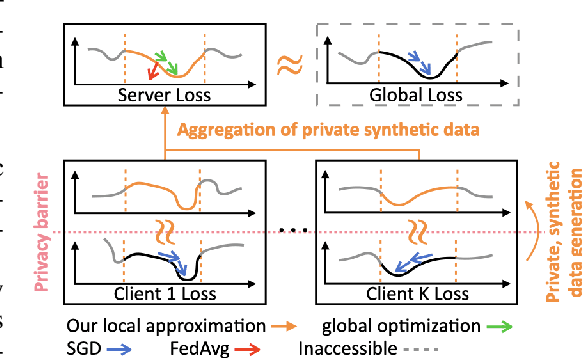

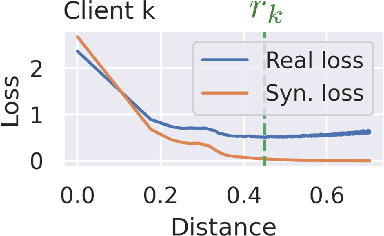

This work proposes Fed-GLOSS-DP, a novel approach to privacy-preserving learning that uses synthetic data to train federated models. In our approach, the server recovers an approximation of the global loss landscape in a local neighborhood based on synthetic samples received from the clients. In contrast to previous, point-wise, gradient-based, linear approximation (such as FedAvg), our formulation enables a type of global optimization that is particularly beneficial in non-IID federated settings. We also present how it rigorously complements record-level differential privacy. Extensive results show that our novel formulation gives rise to considerable improvements in terms of convergence speed and communication costs. We argue that our new approach to federated learning can provide a potential path toward reconciling privacy and accountability by sending differentially private, synthetic data instead of gradient updates. The source code will be released upon publication.
ProgFed: Effective, Communication, and Computation Efficient Federated Learning by Progressive Training
Oct 11, 2021
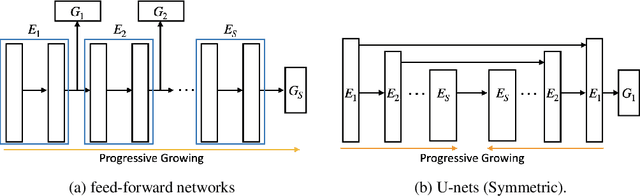
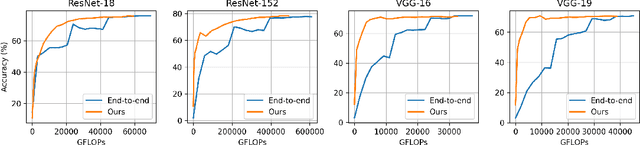
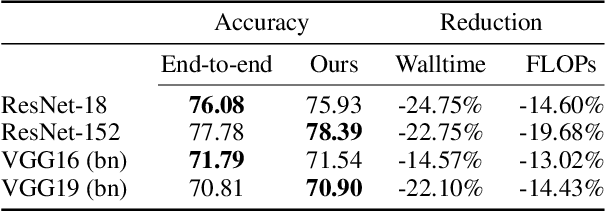
Federated learning is a powerful distributed learning scheme that allows numerous edge devices to collaboratively train a model without sharing their data. However, training is resource-intensive for edge devices, and limited network bandwidth is often the main bottleneck. Prior work often overcomes the constraints by condensing the models or messages into compact formats, e.g., by gradient compression or distillation. In contrast, we propose ProgFed, the first progressive training framework for efficient and effective federated learning. It inherently reduces computation and two-way communication costs while maintaining the strong performance of the final models. We theoretically prove that ProgFed converges at the same asymptotic rate as standard training on full models. Extensive results on a broad range of architectures, including CNNs (VGG, ResNet, ConvNets) and U-nets, and diverse tasks from simple classification to medical image segmentation show that our highly effective training approach saves up to $20\%$ computation and up to $63\%$ communication costs for converged models. As our approach is also complimentary to prior work on compression, we can achieve a wide range of trade-offs, showing reduced communication of up to $50\times$ at only $0.1\%$ loss in utility.
Video Rescaling Networks with Joint Optimization Strategies for Downscaling and Upscaling
Mar 27, 2021

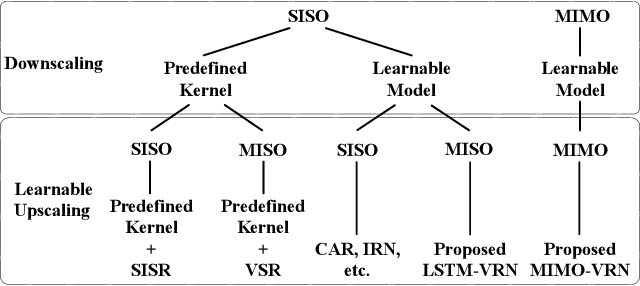
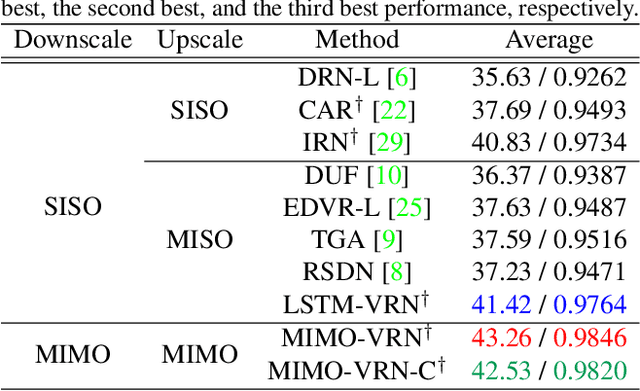
This paper addresses the video rescaling task, which arises from the needs of adapting the video spatial resolution to suit individual viewing devices. We aim to jointly optimize video downscaling and upscaling as a combined task. Most recent studies focus on image-based solutions, which do not consider temporal information. We present two joint optimization approaches based on invertible neural networks with coupling layers. Our Long Short-Term Memory Video Rescaling Network (LSTM-VRN) leverages temporal information in the low-resolution video to form an explicit prediction of the missing high-frequency information for upscaling. Our Multi-input Multi-output Video Rescaling Network (MIMO-VRN) proposes a new strategy for downscaling and upscaling a group of video frames simultaneously. Not only do they outperform the image-based invertible model in terms of quantitative and qualitative results, but also show much improved upscaling quality than the video rescaling methods without joint optimization. To our best knowledge, this work is the first attempt at the joint optimization of video downscaling and upscaling.
Hijack-GAN: Unintended-Use of Pretrained, Black-Box GANs
Nov 28, 2020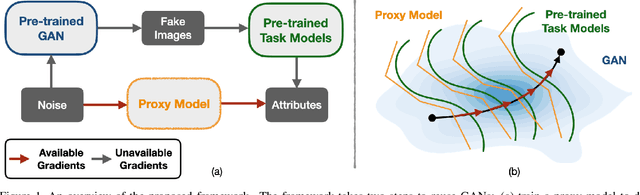
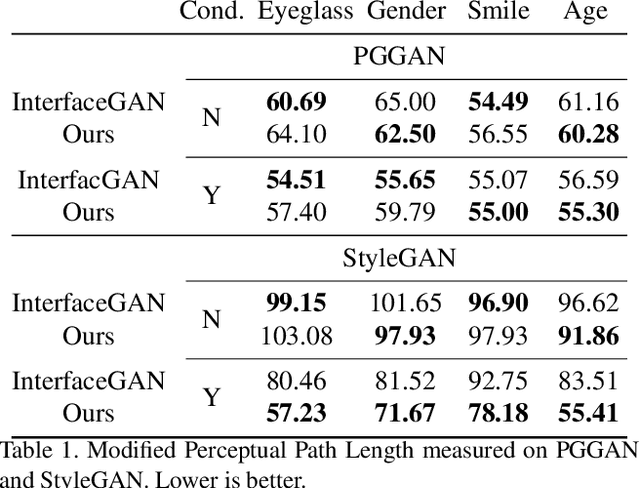

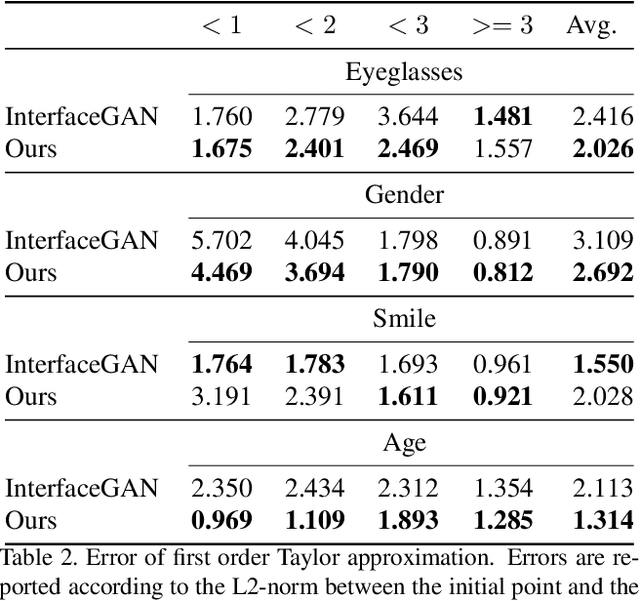
While Generative Adversarial Networks (GANs) show increasing performance and the level of realism is becoming indistinguishable from natural images, this also comes with high demands on data and computation. We show that state-of-the-art GAN models -- such as they are being publicly released by researchers and industry -- can be used for a range of applications beyond unconditional image generation. We achieve this by an iterative scheme that also allows gaining control over the image generation process despite the highly non-linear latent spaces of the latest GAN models. We demonstrate that this opens up the possibility to re-use state-of-the-art, difficult to train, pre-trained GANs with a high level of control even if only black-box access is granted. Our work also raises concerns and awareness that the use cases of a published GAN model may well reach beyond the creators' intention, which needs to be taken into account before a full public release.
InfoScrub: Towards Attribute Privacy by Targeted Obfuscation
May 20, 2020

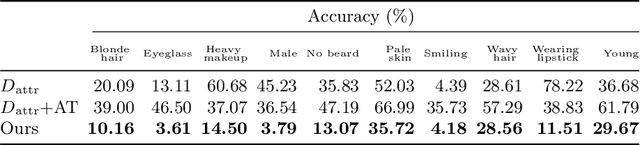
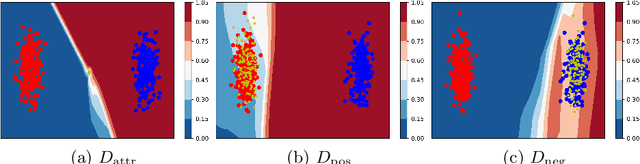
Personal photos of individuals when shared online, apart from exhibiting a myriad of memorable details, also reveals a wide range of private information and potentially entails privacy risks (e.g., online harassment, tracking). To mitigate such risks, it is crucial to study techniques that allow individuals to limit the private information leaked in visual data. We tackle this problem in a novel image obfuscation framework: to maximize entropy on inferences over targeted privacy attributes, while retaining image fidelity. We approach the problem based on an encoder-decoder style architecture, with two key novelties: (a) introducing a discriminator to perform bi-directional translation simultaneously from multiple unpaired domains; (b) predicting an image interpolation which maximizes uncertainty over a target set of attributes. We find our approach generates obfuscated images faithful to the original input images, and additionally increase uncertainty by 6.2$\times$ (or up to 0.85 bits) over the non-obfuscated counterparts.
Learning Priors for Adversarial Autoencoders
Sep 10, 2019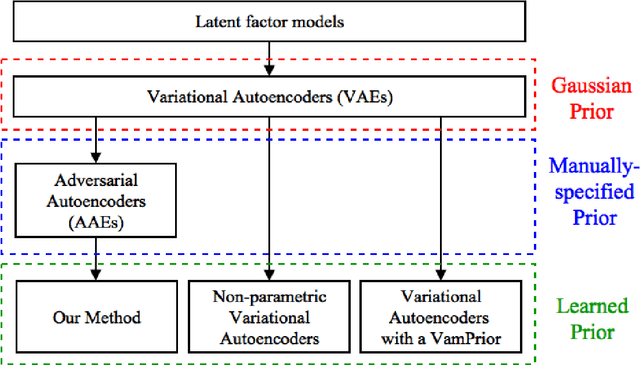
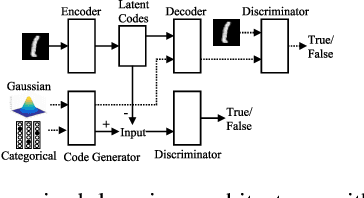

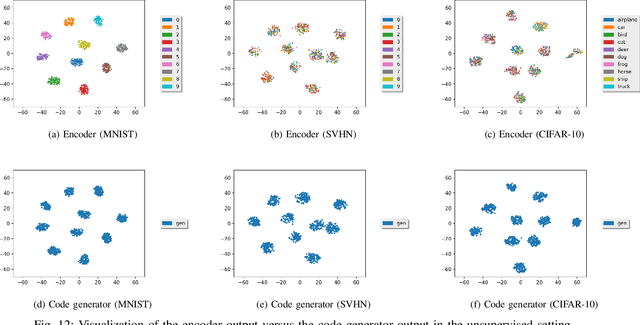
Most deep latent factor models choose simple priors for simplicity, tractability or not knowing what prior to use. Recent studies show that the choice of the prior may have a profound effect on the expressiveness of the model,especially when its generative network has limited capacity. In this paper, we propose to learn a proper prior from data for adversarial autoencoders(AAEs). We introduce the notion of code generators to transform manually selected simple priors into ones that can better characterize the data distribution. Experimental results show that the proposed model can generate better image quality and learn better disentangled representations than AAEs in both supervised and unsupervised settings. Lastly, we present its ability to do cross-domain translation in a text-to-image synthesis task.
All about Structure: Adapting Structural Information across Domains for Boosting Semantic Segmentation
Mar 26, 2019
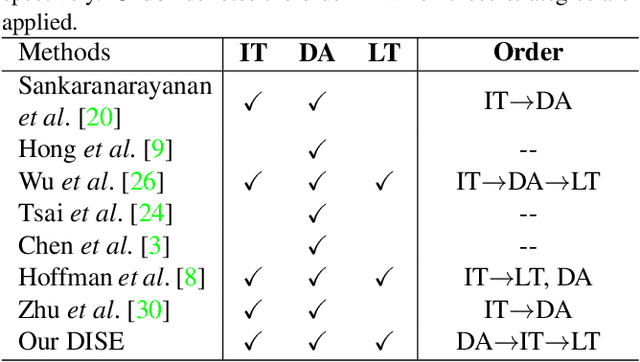
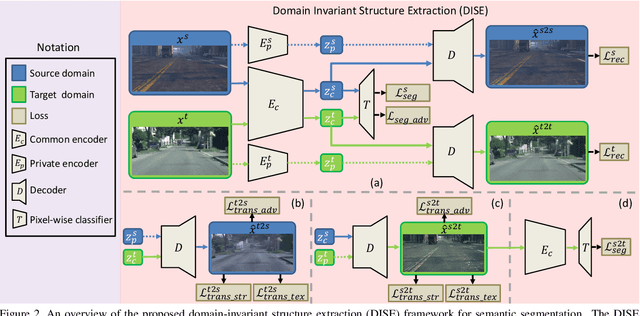
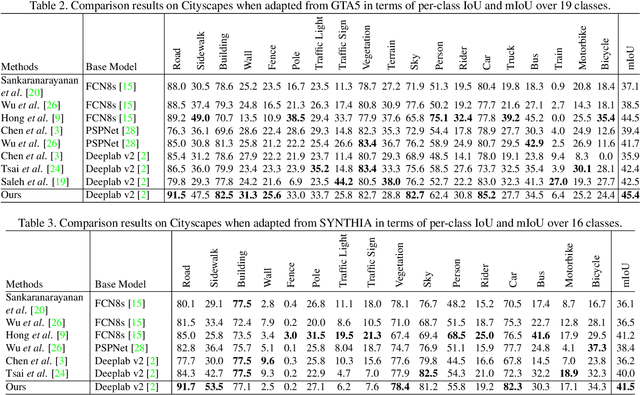
In this paper we tackle the problem of unsupervised domain adaptation for the task of semantic segmentation, where we attempt to transfer the knowledge learned upon synthetic datasets with ground-truth labels to real-world images without any annotation. With the hypothesis that the structural content of images is the most informative and decisive factor to semantic segmentation and can be readily shared across domains, we propose a Domain Invariant Structure Extraction (DISE) framework to disentangle images into domain-invariant structure and domain-specific texture representations, which can further realize image-translation across domains and enable label transfer to improve segmentation performance. Extensive experiments verify the effectiveness of our proposed DISE model and demonstrate its superiority over several state-of-the-art approaches.