 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDF3DV-1K: A Large-Scale Dataset and Benchmark for Distractor-Free Novel View Synthesis
Apr 15, 2026Advances in radiance fields have enabled photorealistic novel view synthesis. In several domains, large-scale real-world datasets have been developed to support comprehensive benchmarking and to facilitate progress beyond scene-specific reconstruction. However, for distractor-free radiance fields, a large-scale dataset with clean and cluttered images per scene remains lacking, limiting the development. To address this gap, we introduce DF3DV-1K, a large-scale real-world dataset comprising 1,048 scenes, each providing clean and cluttered image sets for benchmarking. In total, the dataset contains 89,924 images captured using consumer cameras to mimic casual capture, spanning 128 distractor types and 161 scene themes across indoor and outdoor environments. A curated subset of 41 scenes, DF3DV-41, is systematically designed to evaluate the robustness of distractor-free radiance field methods under challenging scenarios. Using DF3DV-1K, we benchmark nine recent distractor-free radiance field methods and 3D Gaussian Splatting, identifying the most robust methods and the most challenging scenarios. Beyond benchmarking, we demonstrate an application of DF3DV-1K by fine-tuning a diffusion-based 2D enhancer to improve radiance field methods, achieving average improvements of 0.96 dB PSNR and 0.057 LPIPS on the held-out set (e.g., DF3DV-41) and the On-the-go dataset. We hope DF3DV-1K facilitates the development of distractor-free vision and promotes progress beyond scene-specific approaches.
AEGIS: Human Attention-based Explainable Guidance for Intelligent Vehicle Systems
Apr 08, 2025



Improving decision-making capabilities in Autonomous Intelligent Vehicles (AIVs) has been a heated topic in recent years. Despite advancements, training machines to capture regions of interest for comprehensive scene understanding, like human perception and reasoning, remains a significant challenge. This study introduces a novel framework, Human Attention-based Explainable Guidance for Intelligent Vehicle Systems (AEGIS). AEGIS utilizes human attention, converted from eye-tracking, to guide reinforcement learning (RL) models to identify critical regions of interest for decision-making. AEGIS uses a pre-trained human attention model to guide RL models to identify critical regions of interest for decision-making. By collecting 1.2 million frames from 20 participants across six scenarios, AEGIS pre-trains a model to predict human attention patterns.
HFGaussian: Learning Generalizable Gaussian Human with Integrated Human Features
Nov 05, 2024



Recent advancements in radiance field rendering show promising results in 3D scene representation, where Gaussian splatting-based techniques emerge as state-of-the-art due to their quality and efficiency. Gaussian splatting is widely used for various applications, including 3D human representation. However, previous 3D Gaussian splatting methods either use parametric body models as additional information or fail to provide any underlying structure, like human biomechanical features, which are essential for different applications. In this paper, we present a novel approach called HFGaussian that can estimate novel views and human features, such as the 3D skeleton, 3D key points, and dense pose, from sparse input images in real time at 25 FPS. The proposed method leverages generalizable Gaussian splatting technique to represent the human subject and its associated features, enabling efficient and generalizable reconstruction. By incorporating a pose regression network and the feature splatting technique with Gaussian splatting, HFGaussian demonstrates improved capabilities over existing 3D human methods, showcasing the potential of 3D human representations with integrated biomechanics. We thoroughly evaluate our HFGaussian method against the latest state-of-the-art techniques in human Gaussian splatting and pose estimation, demonstrating its real-time, state-of-the-art performance.
DiVA-360: The Dynamic Visuo-Audio Dataset for Immersive Neural Fields
Jul 31, 2023
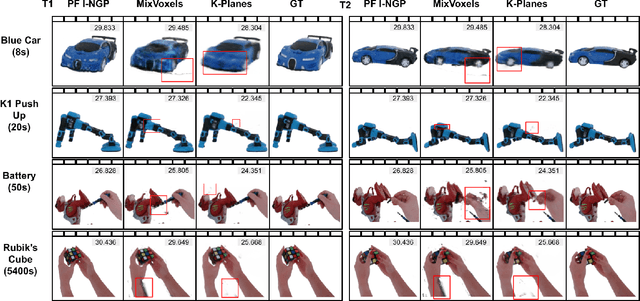
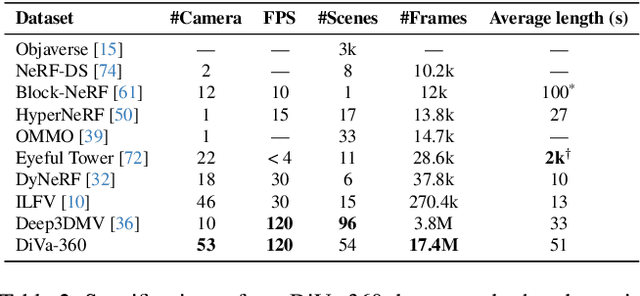

Advances in neural fields are enabling high-fidelity capture of the shape and appearance of static and dynamic scenes. However, their capabilities lag behind those offered by representations such as pixels or meshes due to algorithmic challenges and the lack of large-scale real-world datasets. We address the dataset limitation with DiVA-360, a real-world 360 dynamic visual-audio dataset with synchronized multimodal visual, audio, and textual information about table-scale scenes. It contains 46 dynamic scenes, 30 static scenes, and 95 static objects spanning 11 categories captured using a new hardware system using 53 RGB cameras at 120 FPS and 6 microphones for a total of 8.6M image frames and 1360 s of dynamic data. We provide detailed text descriptions for all scenes, foreground-background segmentation masks, category-specific 3D pose alignment for static objects, as well as metrics for comparison. Our data, hardware and software, and code are available at https://diva360.github.io/.
NeuralODF: Learning Omnidirectional Distance Fields for 3D Shape Representation
Jun 12, 2022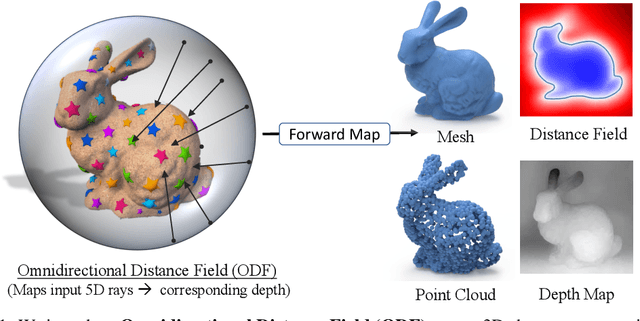

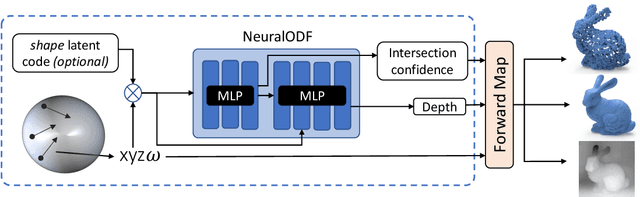
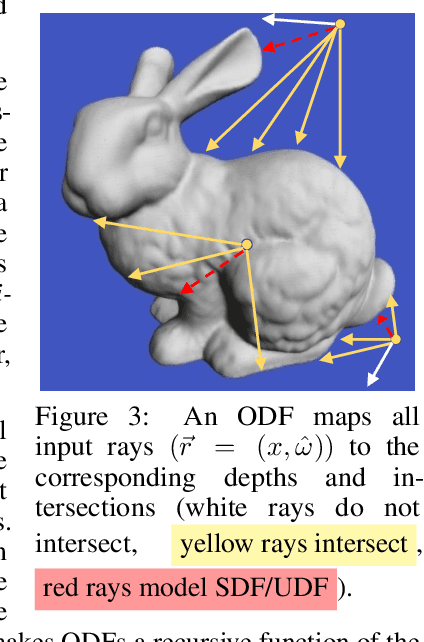
In visual computing, 3D geometry is represented in many different forms including meshes, point clouds, voxel grids, level sets, and depth images. Each representation is suited for different tasks thus making the transformation of one representation into another (forward map) an important and common problem. We propose Omnidirectional Distance Fields (ODFs), a new 3D shape representation that encodes geometry by storing the depth to the object's surface from any 3D position in any viewing direction. Since rays are the fundamental unit of an ODF, it can be used to easily transform to and from common 3D representations like meshes or point clouds. Different from level set methods that are limited to representing closed surfaces, ODFs are unsigned and can thus model open surfaces (e.g., garments). We demonstrate that ODFs can be effectively learned with a neural network (NeuralODF) despite the inherent discontinuities at occlusion boundaries. We also introduce efficient forward mapping algorithms for transforming ODFs to and from common 3D representations. Specifically, we introduce an efficient Jumping Cubes algorithm for generating meshes from ODFs. Experiments demonstrate that NeuralODF can learn to capture high-quality shape by overfitting to a single object, and also learn to generalize on common shape categories.
Weakly-Supervised Image Semantic Segmentation Using Graph Convolutional Networks
Apr 01, 2021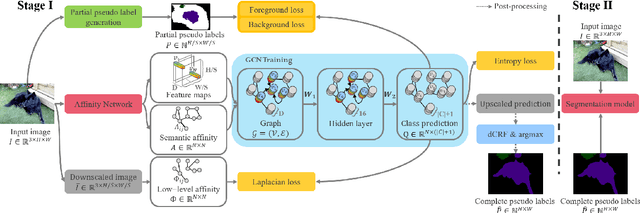
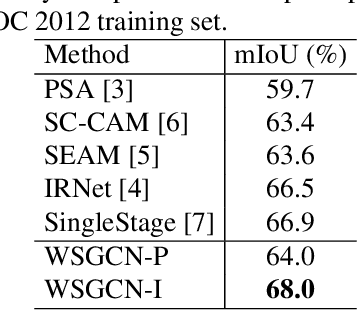


This work addresses weakly-supervised image semantic segmentation based on image-level class labels. One common approach to this task is to propagate the activation scores of Class Activation Maps (CAMs) using a random-walk mechanism in order to arrive at complete pseudo labels for training a semantic segmentation network in a fully-supervised manner. However, the feed-forward nature of the random walk imposes no regularization on the quality of the resulting complete pseudo labels. To overcome this issue, we propose a Graph Convolutional Network (GCN)-based feature propagation framework. We formulate the generation of complete pseudo labels as a semi-supervised learning task and learn a 2-layer GCN separately for every training image by back-propagating a Laplacian and an entropy regularization loss. Experimental results on the PASCAL VOC 2012 dataset confirm the superiority of our scheme to several state-of-the-art baselines. Our code is available at https://github.com/Xavier-Pan/WSGCN.
Video Rescaling Networks with Joint Optimization Strategies for Downscaling and Upscaling
Mar 27, 2021

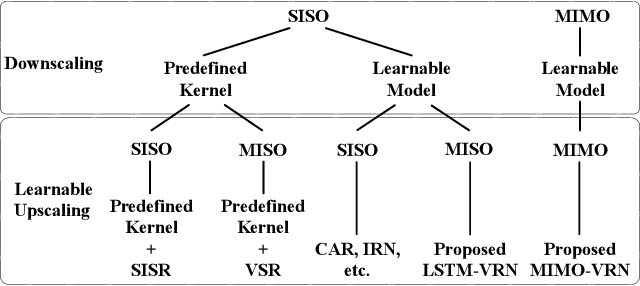
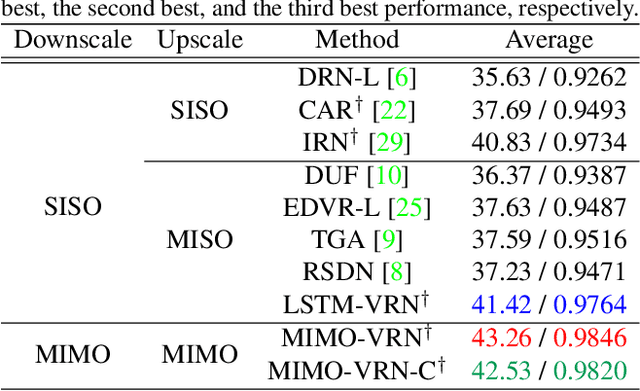
This paper addresses the video rescaling task, which arises from the needs of adapting the video spatial resolution to suit individual viewing devices. We aim to jointly optimize video downscaling and upscaling as a combined task. Most recent studies focus on image-based solutions, which do not consider temporal information. We present two joint optimization approaches based on invertible neural networks with coupling layers. Our Long Short-Term Memory Video Rescaling Network (LSTM-VRN) leverages temporal information in the low-resolution video to form an explicit prediction of the missing high-frequency information for upscaling. Our Multi-input Multi-output Video Rescaling Network (MIMO-VRN) proposes a new strategy for downscaling and upscaling a group of video frames simultaneously. Not only do they outperform the image-based invertible model in terms of quantitative and qualitative results, but also show much improved upscaling quality than the video rescaling methods without joint optimization. To our best knowledge, this work is the first attempt at the joint optimization of video downscaling and upscaling.