 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEssential-Web v1.0: 24T tokens of organized web data
Jun 17, 2025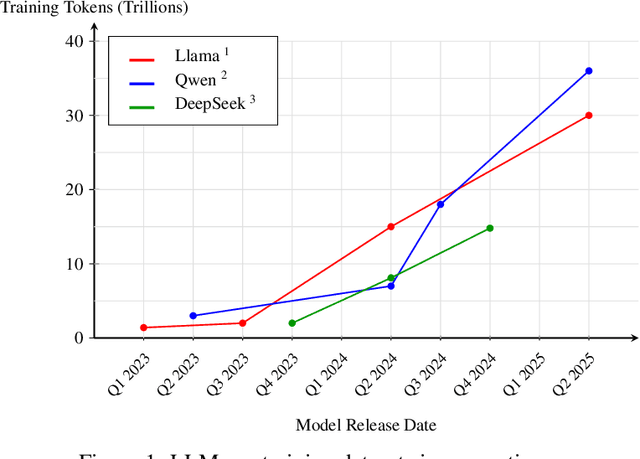
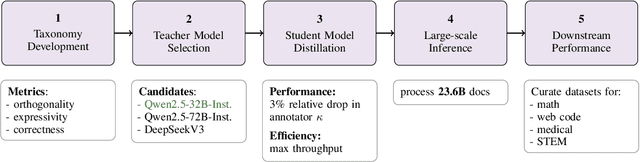

Data plays the most prominent role in how language models acquire skills and knowledge. The lack of massive, well-organized pre-training datasets results in costly and inaccessible data pipelines. We present Essential-Web v1.0, a 24-trillion-token dataset in which every document is annotated with a twelve-category taxonomy covering topic, format, content complexity, and quality. Taxonomy labels are produced by EAI-Distill-0.5b, a fine-tuned 0.5b-parameter model that achieves an annotator agreement within 3% of Qwen2.5-32B-Instruct. With nothing more than SQL-style filters, we obtain competitive web-curated datasets in math (-8.0% relative to SOTA), web code (+14.3%), STEM (+24.5%) and medical (+8.6%). Essential-Web v1.0 is available on HuggingFace: https://huggingface.co/datasets/EssentialAI/essential-web-v1.0
On-the-fly Reconstruction for Large-Scale Novel View Synthesis from Unposed Images
Jun 05, 2025
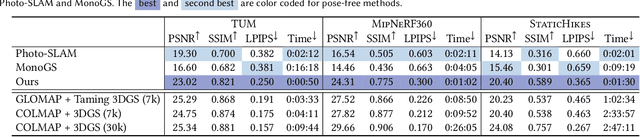


Radiance field methods such as 3D Gaussian Splatting (3DGS) allow easy reconstruction from photos, enabling free-viewpoint navigation. Nonetheless, pose estimation using Structure from Motion and 3DGS optimization can still each take between minutes and hours of computation after capture is complete. SLAM methods combined with 3DGS are fast but struggle with wide camera baselines and large scenes. We present an on-the-fly method to produce camera poses and a trained 3DGS immediately after capture. Our method can handle dense and wide-baseline captures of ordered photo sequences and large-scale scenes. To do this, we first introduce fast initial pose estimation, exploiting learned features and a GPU-friendly mini bundle adjustment. We then introduce direct sampling of Gaussian primitive positions and shapes, incrementally spawning primitives where required, significantly accelerating training. These two efficient steps allow fast and robust joint optimization of poses and Gaussian primitives. Our incremental approach handles large-scale scenes by introducing scalable radiance field construction, progressively clustering 3DGS primitives, storing them in anchors, and offloading them from the GPU. Clustered primitives are progressively merged, keeping the required scale of 3DGS at any viewpoint. We evaluate our solution on a variety of datasets and show that our solution can provide on-the-fly processing of all the capture scenarios and scene sizes we target while remaining competitive with other methods that only handle specific capture styles or scene sizes in speed, image quality, or both.
Practical Efficiency of Muon for Pretraining
May 04, 2025We demonstrate that Muon, the simplest instantiation of a second-order optimizer, explicitly expands the Pareto frontier over AdamW on the compute-time tradeoff. We find that Muon is more effective than AdamW in retaining data efficiency at large batch sizes, far beyond the so-called critical batch size, while remaining computationally efficient, thus enabling more economical training. We study the combination of Muon and the maximal update parameterization (muP) for efficient hyperparameter transfer and present a simple telescoping algorithm that accounts for all sources of error in muP while introducing only a modest overhead in resources. We validate our findings through extensive experiments with model sizes up to four billion parameters and ablations on the data distribution and architecture.
Rethinking Reflection in Pre-Training
Apr 05, 2025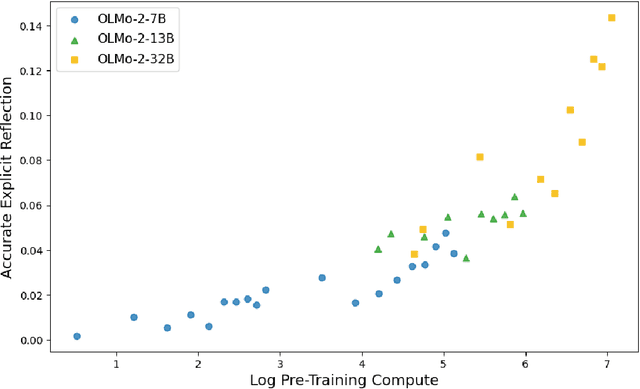
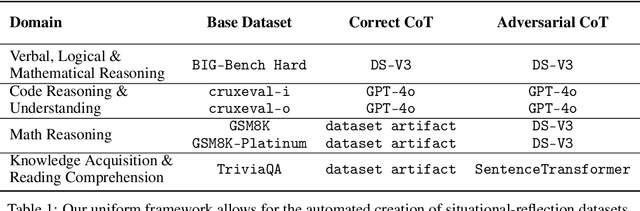
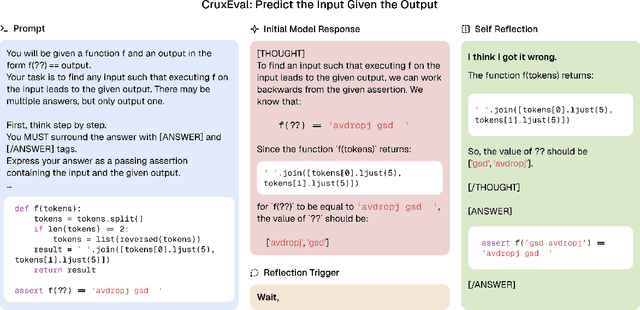
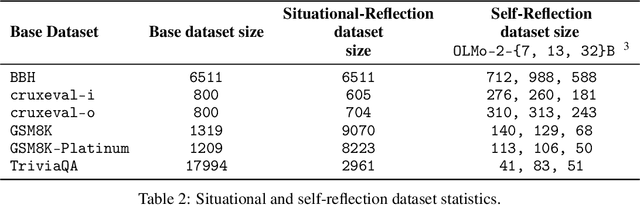
A language model's ability to reflect on its own reasoning provides a key advantage for solving complex problems. While most recent research has focused on how this ability develops during reinforcement learning, we show that it actually begins to emerge much earlier - during the model's pre-training. To study this, we introduce deliberate errors into chains-of-thought and test whether the model can still arrive at the correct answer by recognizing and correcting these mistakes. By tracking performance across different stages of pre-training, we observe that this self-correcting ability appears early and improves steadily over time. For instance, an OLMo2-7B model pre-trained on 4 trillion tokens displays self-correction on our six self-reflection tasks.
DiVA-360: The Dynamic Visuo-Audio Dataset for Immersive Neural Fields
Jul 31, 2023
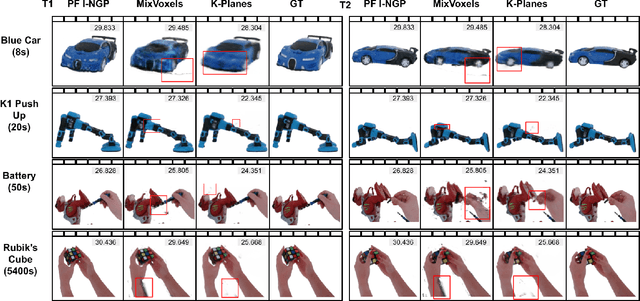
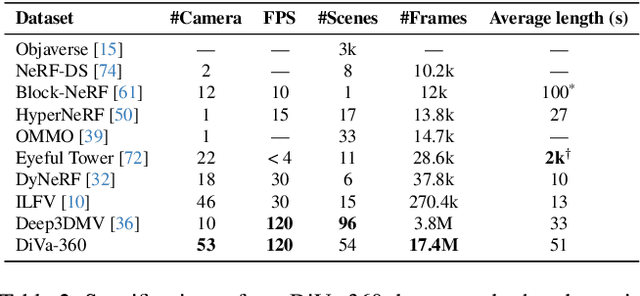

Advances in neural fields are enabling high-fidelity capture of the shape and appearance of static and dynamic scenes. However, their capabilities lag behind those offered by representations such as pixels or meshes due to algorithmic challenges and the lack of large-scale real-world datasets. We address the dataset limitation with DiVA-360, a real-world 360 dynamic visual-audio dataset with synchronized multimodal visual, audio, and textual information about table-scale scenes. It contains 46 dynamic scenes, 30 static scenes, and 95 static objects spanning 11 categories captured using a new hardware system using 53 RGB cameras at 120 FPS and 6 microphones for a total of 8.6M image frames and 1360 s of dynamic data. We provide detailed text descriptions for all scenes, foreground-background segmentation masks, category-specific 3D pose alignment for static objects, as well as metrics for comparison. Our data, hardware and software, and code are available at https://diva360.github.io/.
Convergence of a Human-in-the-Loop Policy-Gradient Algorithm With Eligibility Trace Under Reward, Policy, and Advantage Feedback
Sep 15, 2021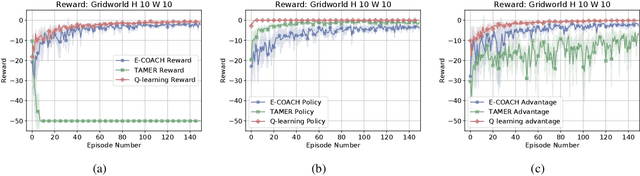

Fluid human-agent communication is essential for the future of human-in-the-loop reinforcement learning. An agent must respond appropriately to feedback from its human trainer even before they have significant experience working together. Therefore, it is important that learning agents respond well to various feedback schemes human trainers are likely to provide. This work analyzes the COnvergent Actor-Critic by Humans (COACH) algorithm under three different types of feedback-policy feedback, reward feedback, and advantage feedback. For these three feedback types, we find that COACH can behave sub-optimally. We propose a variant of COACH, episodic COACH (E-COACH), which we prove converges for all three types. We compare our COACH variant with two other reinforcement-learning algorithms: Q-learning and TAMER.