 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConvergence of a Human-in-the-Loop Policy-Gradient Algorithm With Eligibility Trace Under Reward, Policy, and Advantage Feedback
Sep 15, 2021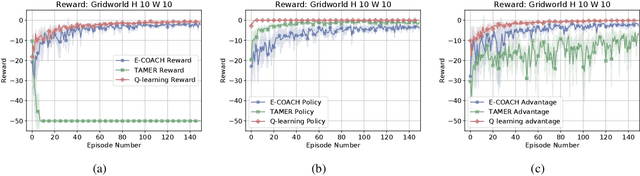

Fluid human-agent communication is essential for the future of human-in-the-loop reinforcement learning. An agent must respond appropriately to feedback from its human trainer even before they have significant experience working together. Therefore, it is important that learning agents respond well to various feedback schemes human trainers are likely to provide. This work analyzes the COnvergent Actor-Critic by Humans (COACH) algorithm under three different types of feedback-policy feedback, reward feedback, and advantage feedback. For these three feedback types, we find that COACH can behave sub-optimally. We propose a variant of COACH, episodic COACH (E-COACH), which we prove converges for all three types. We compare our COACH variant with two other reinforcement-learning algorithms: Q-learning and TAMER.