 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEssential-Web v1.0: 24T tokens of organized web data
Jun 17, 2025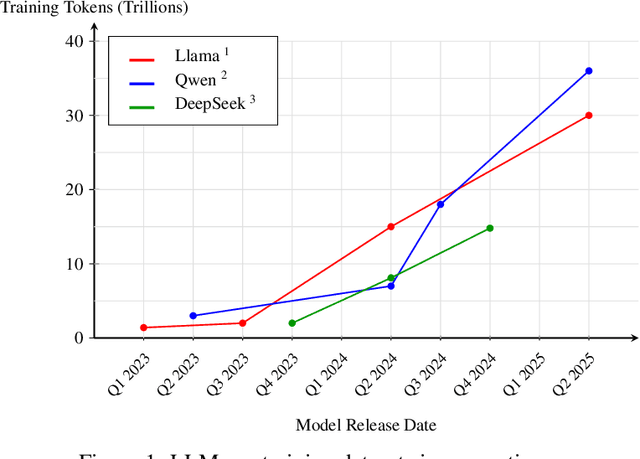
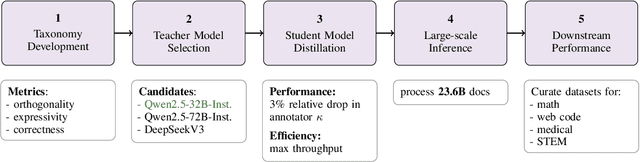

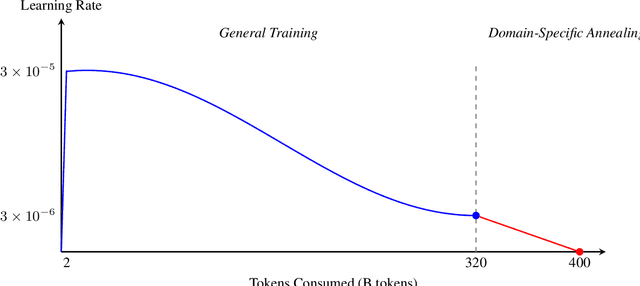
Data plays the most prominent role in how language models acquire skills and knowledge. The lack of massive, well-organized pre-training datasets results in costly and inaccessible data pipelines. We present Essential-Web v1.0, a 24-trillion-token dataset in which every document is annotated with a twelve-category taxonomy covering topic, format, content complexity, and quality. Taxonomy labels are produced by EAI-Distill-0.5b, a fine-tuned 0.5b-parameter model that achieves an annotator agreement within 3% of Qwen2.5-32B-Instruct. With nothing more than SQL-style filters, we obtain competitive web-curated datasets in math (-8.0% relative to SOTA), web code (+14.3%), STEM (+24.5%) and medical (+8.6%). Essential-Web v1.0 is available on HuggingFace: https://huggingface.co/datasets/EssentialAI/essential-web-v1.0
Practical Efficiency of Muon for Pretraining
May 04, 2025We demonstrate that Muon, the simplest instantiation of a second-order optimizer, explicitly expands the Pareto frontier over AdamW on the compute-time tradeoff. We find that Muon is more effective than AdamW in retaining data efficiency at large batch sizes, far beyond the so-called critical batch size, while remaining computationally efficient, thus enabling more economical training. We study the combination of Muon and the maximal update parameterization (muP) for efficient hyperparameter transfer and present a simple telescoping algorithm that accounts for all sources of error in muP while introducing only a modest overhead in resources. We validate our findings through extensive experiments with model sizes up to four billion parameters and ablations on the data distribution and architecture.
Rethinking Reflection in Pre-Training
Apr 05, 2025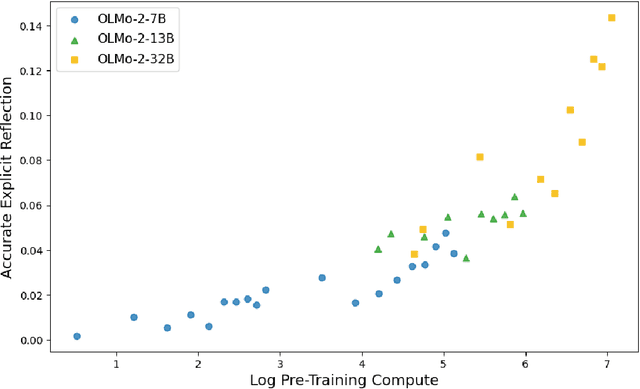
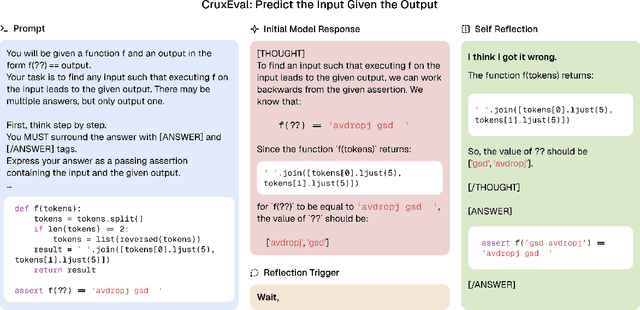
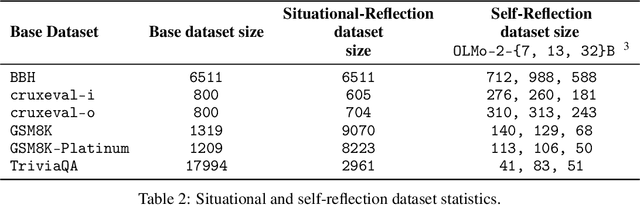
A language model's ability to reflect on its own reasoning provides a key advantage for solving complex problems. While most recent research has focused on how this ability develops during reinforcement learning, we show that it actually begins to emerge much earlier - during the model's pre-training. To study this, we introduce deliberate errors into chains-of-thought and test whether the model can still arrive at the correct answer by recognizing and correcting these mistakes. By tracking performance across different stages of pre-training, we observe that this self-correcting ability appears early and improves steadily over time. For instance, an OLMo2-7B model pre-trained on 4 trillion tokens displays self-correction on our six self-reflection tasks.
Reducing Target Group Bias in Hate Speech Detectors
Dec 07, 2021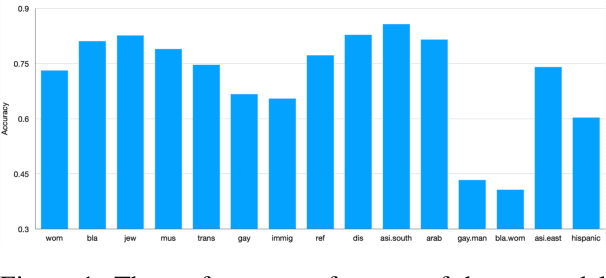
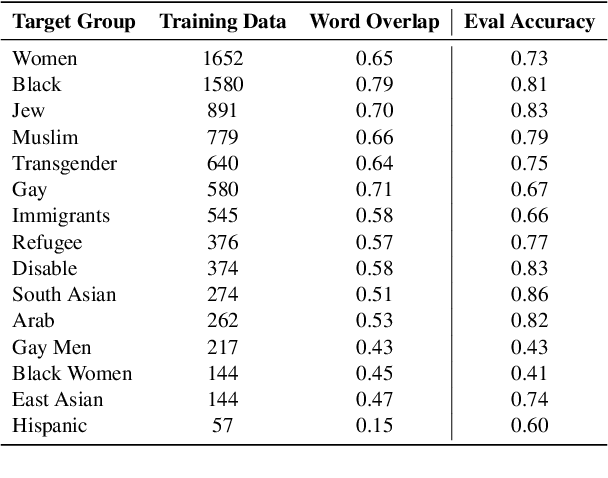
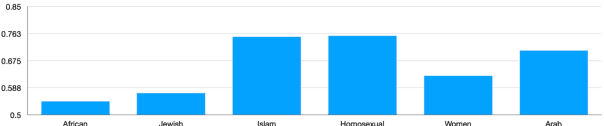
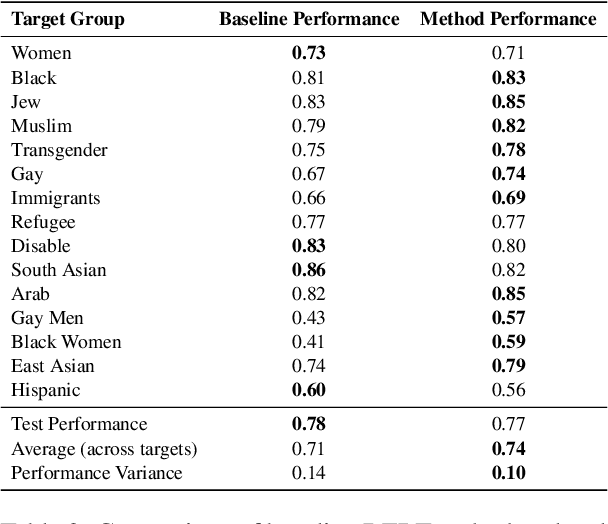
The ubiquity of offensive and hateful content on online fora necessitates the need for automatic solutions that detect such content competently across target groups. In this paper we show that text classification models trained on large publicly available datasets despite having a high overall performance, may significantly under-perform on several protected groups. On the \citet{vidgen2020learning} dataset, we find the accuracy to be 37\% lower on an under annotated Black Women target group and 12\% lower on Immigrants, where hate speech involves a distinct style. To address this, we propose to perform token-level hate sense disambiguation, and utilize tokens' hate sense representations for detection, modeling more general signals. On two publicly available datasets, we observe that the variance in model accuracy across target groups drops by at least 30\%, improving the average target group performance by 4\% and worst case performance by 13\%.
Generating Related Work
Apr 18, 2021


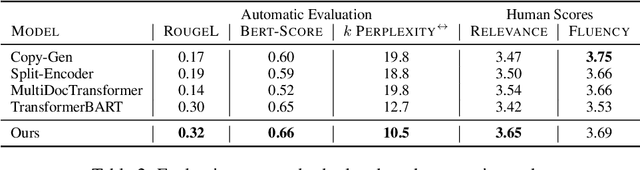
Communicating new research ideas involves highlighting similarities and differences with past work. Authors write fluent, often long sections to survey the distinction of a new paper with related work. In this work we model generating related work sections while being cognisant of the motivation behind citing papers. Our content planning model generates a tree of cited papers before a surface realization model lexicalizes this skeleton. Our model outperforms several strong state-of-the-art summarization and multi-document summarization models on generating related work on an ACL Anthology (AA) based dataset which we contribute.
Nutribullets Hybrid: Multi-document Health Summarization
Apr 08, 2021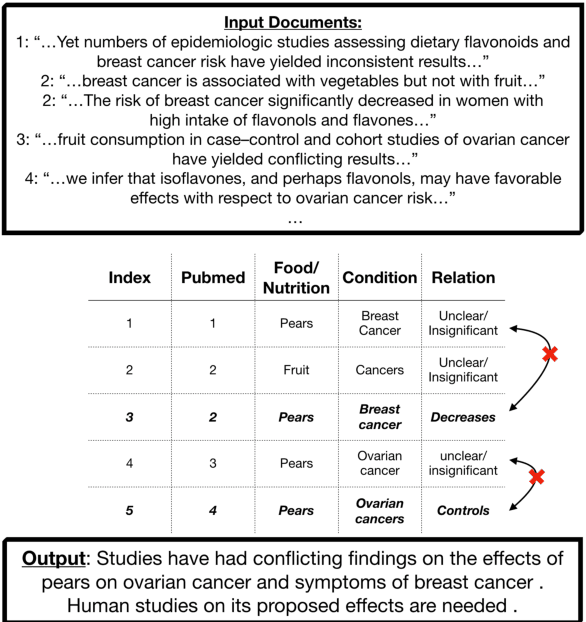

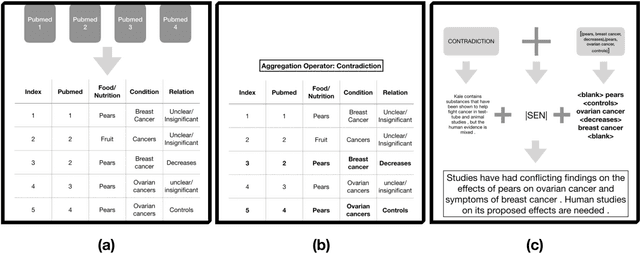

We present a method for generating comparative summaries that highlights similarities and contradictions in input documents. The key challenge in creating such summaries is the lack of large parallel training data required for training typical summarization systems. To this end, we introduce a hybrid generation approach inspired by traditional concept-to-text systems. To enable accurate comparison between different sources, the model first learns to extract pertinent relations from input documents. The content planning component uses deterministic operators to aggregate these relations after identifying a subset for inclusion into a summary. The surface realization component lexicalizes this information using a text-infilling language model. By separately modeling content selection and realization, we can effectively train them with limited annotations. We implemented and tested the model in the domain of nutrition and health -- rife with inconsistencies. Compared to conventional methods, our framework leads to more faithful, relevant and aggregation-sensitive summarization -- while being equally fluent.
Nutri-bullets: Summarizing Health Studies by Composing Segments
Mar 22, 2021


We introduce \emph{Nutri-bullets}, a multi-document summarization task for health and nutrition. First, we present two datasets of food and health summaries from multiple scientific studies. Furthermore, we propose a novel \emph{extract-compose} model to solve the problem in the regime of limited parallel data. We explicitly select key spans from several abstracts using a policy network, followed by composing the selected spans to present a summary via a task specific language model. Compared to state-of-the-art methods, our approach leads to more faithful, relevant and diverse summarization -- properties imperative to this application. For instance, on the BreastCancer dataset our approach gets a more than 50\% improvement on relevance and faithfulness.\footnote{Our code and data is available at \url{https://github.com/darsh10/Nutribullets.}}
* 12 pages
Capturing Greater Context for Question Generation
Oct 22, 2019
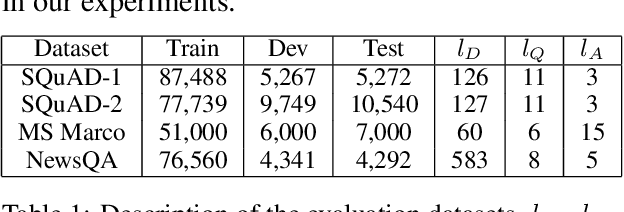
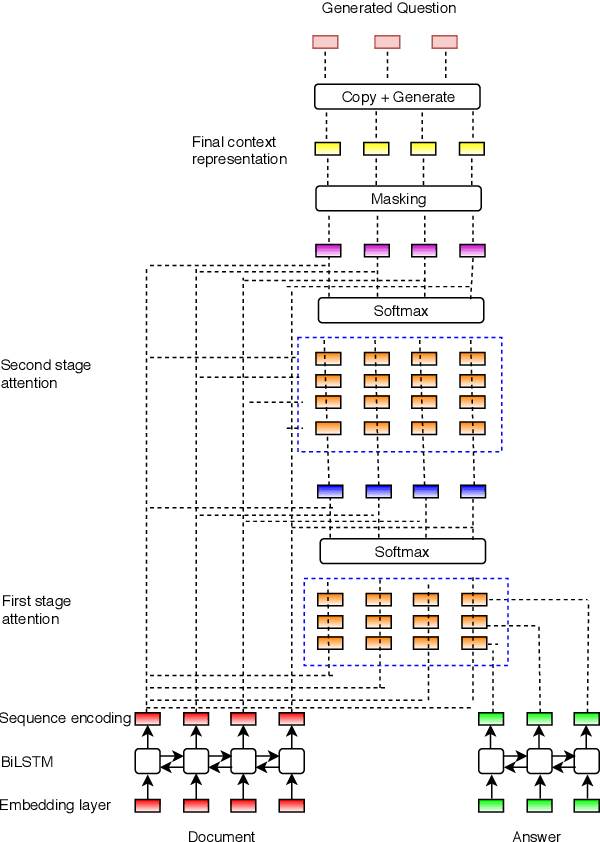
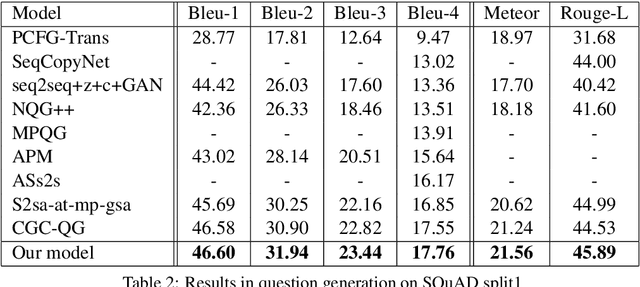
Automatic question generation can benefit many applications ranging from dialogue systems to reading comprehension. While questions are often asked with respect to long documents, there are many challenges with modeling such long documents. Many existing techniques generate questions by effectively looking at one sentence at a time, leading to questions that are easy and not reflective of the human process of question generation. Our goal is to incorporate interactions across multiple sentences to generate realistic questions for long documents. In order to link a broad document context to the target answer, we represent the relevant context via a multi-stage attention mechanism, which forms the foundation of a sequence to sequence model. We outperform state-of-the-art methods on question generation on three question-answering datasets -- SQuAD, MS MARCO and NewsQA.
Automatic Fact-guided Sentence Modification
Sep 30, 2019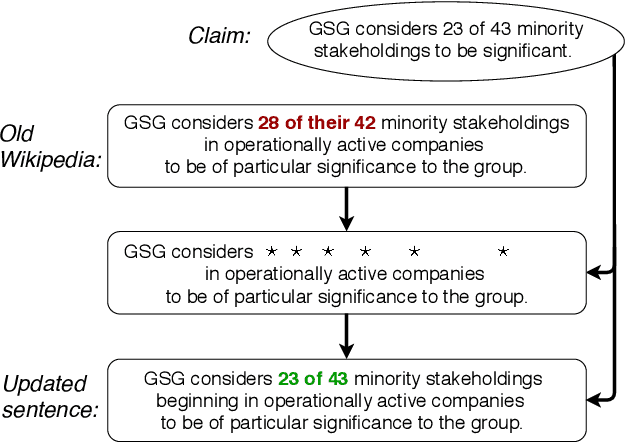
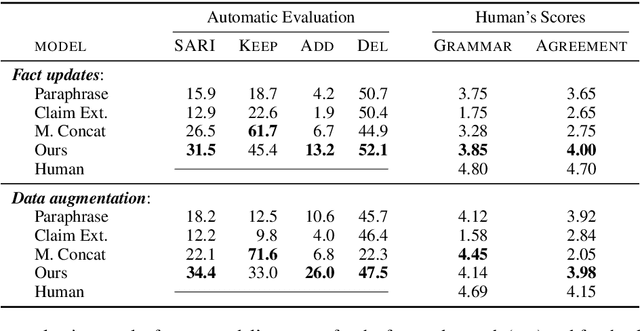
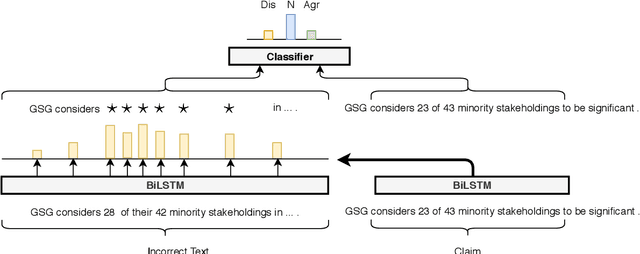
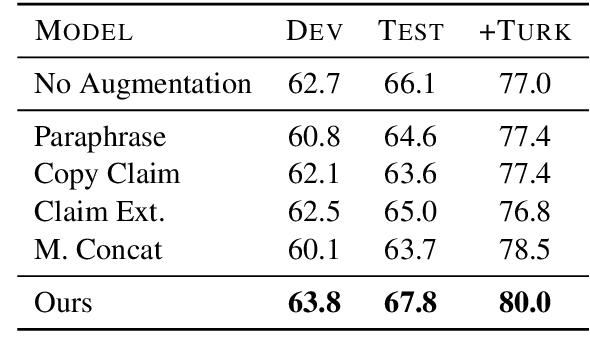
Online encyclopediae like Wikipedia contain large amounts of text that need frequent corrections and updates. The new information may contradict existing content in encyclopediae. In this paper, we focus on rewriting such dynamically changing articles. This is a challenging constrained generation task, as the output must be consistent with the new information and fit into the rest of the existing document. To this end, we propose a two-step solution: (1) We identify and remove the contradicting components in a target text for a given claim, using a neutralizing stance model; (2) We expand the remaining text to be consistent with the given claim, using a novel two-encoder sequence-to-sequence model with copy attention. Applied to a Wikipedia fact update dataset, our method successfully generates updated sentences for new claims, achieving the highest SARI score. Furthermore, we demonstrate that generating synthetic data through such rewritten sentences can successfully augment the FEVER fact-checking training dataset, leading to a relative error reduction of 13%.
Towards Debiasing Fact Verification Models
Aug 31, 2019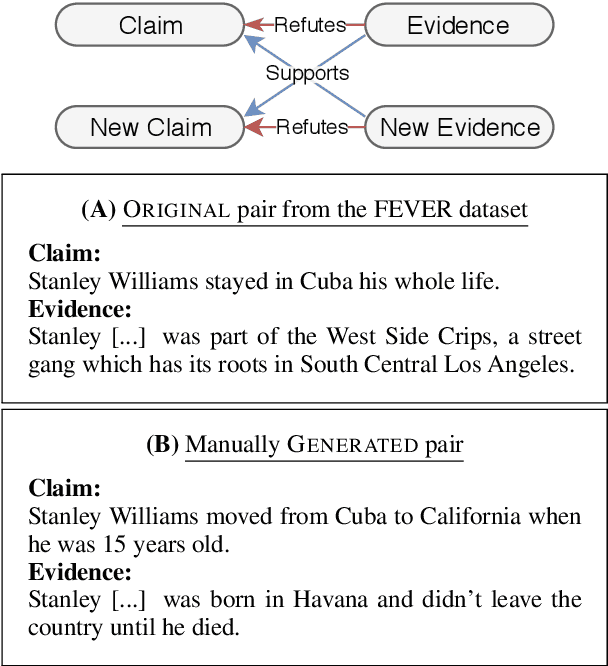
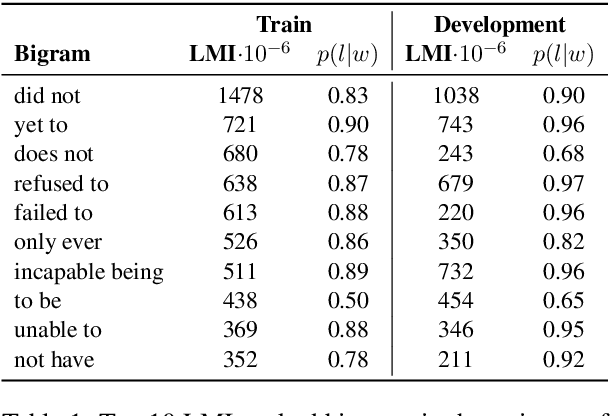

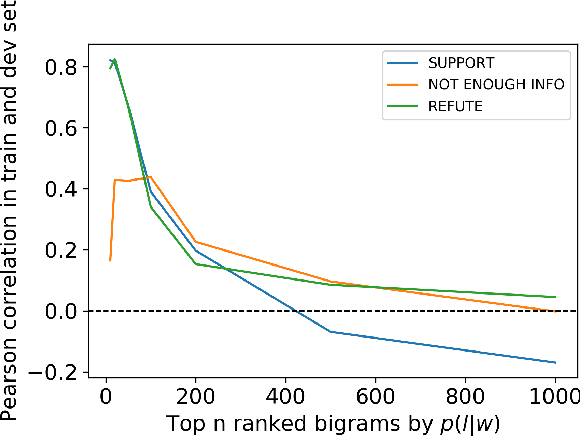
Fact verification requires validating a claim in the context of evidence. We show, however, that in the popular FEVER dataset this might not necessarily be the case. Claim-only classifiers perform competitively with top evidence-aware models. In this paper, we investigate the cause of this phenomenon, identifying strong cues for predicting labels solely based on the claim, without considering any evidence. We create an evaluation set that avoids those idiosyncrasies. The performance of FEVER-trained models significantly drops when evaluated on this test set. Therefore, we introduce a regularization method which alleviates the effect of bias in the training data, obtaining improvements on the newly created test set. This work is a step towards a more sound evaluation of reasoning capabilities in fact verification models.