 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProVG: Progressive Visual Grounding via Language Decoupling for Remote Sensing Imagery
Apr 02, 2026Remote sensing visual grounding (RSVG) aims to localize objects in remote sensing imagery according to natural language expressions. Previous methods typically rely on sentence-level vision-language alignment, which struggles to exploit fine-grained linguistic cues, such as \textit{spatial relations} and \textit{object attributes}, that are crucial for distinguishing objects with similar characteristics. Importantly, these cues play distinct roles across different grounding stages and should be leveraged accordingly to provide more explicit guidance. In this work, we propose \textbf{ProVG}, a novel RSVG framework that improves localization accuracy by decoupling language expressions into global context, spatial relations, and object attributes. To integrate these linguistic cues, ProVG employs a simple yet effective progressive cross-modal modulator, which dynamically modulates visual attention through a \textit{survey-locate-verify} scheme, enabling coarse-to-fine vision-language alignment. In addition, ProVG incorporates a cross-scale fusion module to mitigate the large-scale variations in remote sensing imagery, along with a language-guided calibration decoder to refine cross-modal alignment during prediction. A unified multi-task head further enables ProVG to support both referring expression comprehension and segmentation tasks. Extensive experiments on two benchmarks, \textit{i.e.}, RRSIS-D and RISBench, demonstrate that ProVG consistently outperforms existing methods, achieving new state-of-the-art performance.
SPEGC: Continual Test-Time Adaptation via Semantic-Prompt-Enhanced Graph Clustering for Medical Image Segmentation
Mar 12, 2026In medical image segmentation tasks, the domain gap caused by the difference in data collection between training and testing data seriously hinders the deployment of pre-trained models in clinical practice. Continual Test-Time Adaptation (CTTA) aims to enable pre-trained models to adapt to continuously changing unlabeled domains, providing an effective approach to solving this problem. However, existing CTTA methods often rely on unreliable supervisory signals, igniting a self-reinforcing cycle of error accumulation that culminates in catastrophic performance degradation. To overcome these challenges, we propose a CTTA via Semantic-Prompt-Enhanced Graph Clustering (SPEGC) for medical image segmentation. First, we design a semantic prompt feature enhancement mechanism that utilizes decoupled commonality and heterogeneity prompt pools to inject global contextual information into local features, alleviating their susceptibility to noise interference under domain shift. Second, based on these enhanced features, we design a differentiable graph clustering solver. This solver reframes global edge sparsification as an optimal transport problem, allowing it to distill a raw similarity matrix into a refined and high-order structural representation in an end-to-end manner. Finally, this robust structural representation is used to guide model adaptation, ensuring predictions are consistent at a cluster-level and dynamically adjusting decision boundaries. Extensive experiments demonstrate that SPEGC outperforms other state-of-the-art CTTA methods on two medical image segmentation benchmarks. The source code is available at https://github.com/Jwei-Z/SPEGC-for-MIS.
Parallel Track Transformers: Enabling Fast GPU Inference with Reduced Synchronization
Feb 07, 2026Efficient large-scale inference of transformer-based large language models (LLMs) remains a fundamental systems challenge, frequently requiring multi-GPU parallelism to meet stringent latency and throughput targets. Conventional tensor parallelism decomposes matrix operations across devices but introduces substantial inter-GPU synchronization, leading to communication bottlenecks and degraded scalability. We propose the Parallel Track (PT) Transformer, a novel architectural paradigm that restructures computation to minimize cross-device dependencies. PT achieves up to a 16x reduction in synchronization operations relative to standard tensor parallelism, while maintaining competitive model quality in our experiments. We integrate PT into two widely adopted LLM serving stacks-Tensor-RT-LLM and vLLM-and report consistent improvements in serving efficiency, including up to 15-30% reduced time to first token, 2-12% reduced time per output token, and up to 31.90% increased throughput in both settings.
SPLA: Block Sparse Plus Linear Attention for Long Context Modeling
Jan 29, 2026Block-wise sparse attention offers significant efficiency gains for long-context modeling, yet existing methods often suffer from low selection fidelity and cumulative contextual loss by completely discarding unselected blocks. To address these limitations, we introduce Sparse Plus Linear Attention (SPLA), a framework that utilizes a selection metric derived from second-order Taylor expansions to accurately identify relevant blocks for exact attention. Instead of discarding the remaining "long tail," SPLA compresses unselected blocks into a compact recurrent state via a residual linear attention (RLA) module. Crucially, to avoid IO overhead, we derive an optimized subtraction-based formulation for RLA -- calculating the residual as the difference between global and selected linear attention -- ensuring that unselected blocks are never explicitly accessed during inference. Our experiments demonstrate that SPLA closes the performance gap in continual pretraining, surpassing dense attention models on long-context benchmarks like RULER while maintaining competitive general knowledge and reasoning capabilities.
RTS-Mono: A Real-Time Self-Supervised Monocular Depth Estimation Method for Real-World Deployment
Nov 18, 2025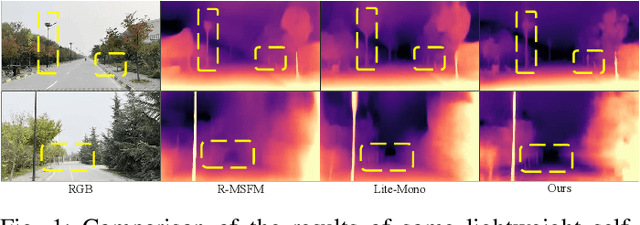

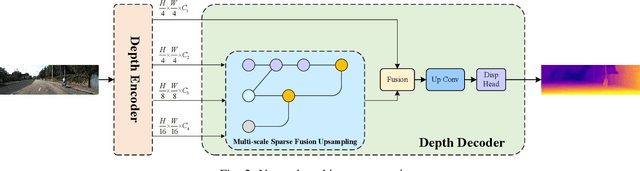
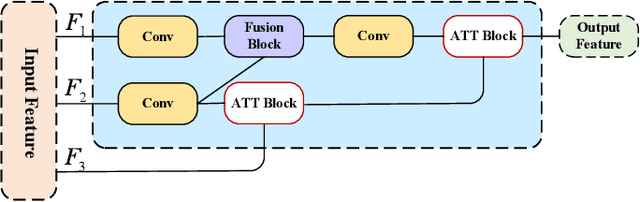
Depth information is crucial for autonomous driving and intelligent robot navigation. The simplicity and flexibility of self-supervised monocular depth estimation are conducive to its role in these fields. However, most existing monocular depth estimation models consume many computing resources. Although some methods have reduced the model's size and improved computing efficiency, the performance deteriorates, seriously hindering the real-world deployment of self-supervised monocular depth estimation models in the real world. To address this problem, we proposed a real-time self-supervised monocular depth estimation method and implemented it in the real world. It is called RTS-Mono, which is a lightweight and efficient encoder-decoder architecture. The encoder is based on Lite-Encoder, and the decoder is designed with a multi-scale sparse fusion framework to minimize redundancy, ensure performance, and improve inference speed. RTS-Mono achieved state-of-the-art (SoTA) performance in high and low resolutions with extremely low parameter counts (3 M) in experiments based on the KITTI dataset. Compared with lightweight methods, RTS-Mono improved Abs Rel and Sq Rel by 5.6% and 9.8% at low resolution and improved Sq Rel and RMSE by 6.1% and 1.9% at high resolution. In real-world deployment experiments, RTS-Mono has extremely high accuracy and can perform real-time inference on Nvidia Jetson Orin at a speed of 49 FPS. Source code is available at https://github.com/ZYCheng777/RTS-Mono.
Representation Discrepancy Bridging Method for Remote Sensing Image-Text Retrieval
May 22, 2025Remote Sensing Image-Text Retrieval (RSITR) plays a critical role in geographic information interpretation, disaster monitoring, and urban planning by establishing semantic associations between image and textual descriptions. Existing Parameter-Efficient Fine-Tuning (PEFT) methods for Vision-and-Language Pre-training (VLP) models typically adopt symmetric adapter structures for exploring cross-modal correlations. However, the strong discriminative nature of text modality may dominate the optimization process and inhibits image representation learning. The nonnegligible imbalanced cross-modal optimization remains a bottleneck to enhancing the model performance. To address this issue, this study proposes a Representation Discrepancy Bridging (RDB) method for the RSITR task. On the one hand, a Cross-Modal Asymmetric Adapter (CMAA) is designed to enable modality-specific optimization and improve feature alignment. The CMAA comprises a Visual Enhancement Adapter (VEA) and a Text Semantic Adapter (TSA). VEA mines fine-grained image features by Differential Attention (DA) mechanism, while TSA identifies key textual semantics through Hierarchical Attention (HA) mechanism. On the other hand, this study extends the traditional single-task retrieval framework to a dual-task optimization framework and develops a Dual-Task Consistency Loss (DTCL). The DTCL improves cross-modal alignment robustness through an adaptive weighted combination of cross-modal, classification, and exponential moving average consistency constraints. Experiments on RSICD and RSITMD datasets show that the proposed RDB method achieves a 6%-11% improvement in mR metrics compared to state-of-the-art PEFT methods and a 1.15%-2% improvement over the full fine-tuned GeoRSCLIP model.
IDEA Prune: An Integrated Enlarge-and-Prune Pipeline in Generative Language Model Pretraining
Mar 07, 2025Recent advancements in large language models have intensified the need for efficient and deployable models within limited inference budgets. Structured pruning pipelines have shown promise in token efficiency compared to training target-size models from scratch. In this paper, we advocate incorporating enlarged model pretraining, which is often ignored in previous works, into pruning. We study the enlarge-and-prune pipeline as an integrated system to address two critical questions: whether it is worth pretraining an enlarged model even when the model is never deployed, and how to optimize the entire pipeline for better pruned models. We propose an integrated enlarge-and-prune pipeline, which combines enlarge model training, pruning, and recovery under a single cosine annealing learning rate schedule. This approach is further complemented by a novel iterative structured pruning method for gradual parameter removal. The proposed method helps to mitigate the knowledge loss caused by the rising learning rate in naive enlarge-and-prune pipelines and enable effective redistribution of model capacity among surviving neurons, facilitating smooth compression and enhanced performance. We conduct comprehensive experiments on compressing 2.8B models to 1.3B with up to 2T tokens in pretraining. It demonstrates the integrated approach not only provides insights into the token efficiency of enlarged model pretraining but also achieves superior performance of pruned models.
Instruction-Following Pruning for Large Language Models
Jan 07, 2025



With the rapid scaling of large language models (LLMs), structured pruning has become a widely used technique to learn efficient, smaller models from larger ones, delivering superior performance compared to training similarly sized models from scratch. In this paper, we move beyond the traditional static pruning approach of determining a fixed pruning mask for a model, and propose a dynamic approach to structured pruning. In our method, the pruning mask is input-dependent and adapts dynamically based on the information described in a user instruction. Our approach, termed "instruction-following pruning", introduces a sparse mask predictor that takes the user instruction as input and dynamically selects the most relevant model parameters for the given task. To identify and activate effective parameters, we jointly optimize the sparse mask predictor and the LLM, leveraging both instruction-following data and the pre-training corpus. Experimental results demonstrate the effectiveness of our approach on a wide range of evaluation benchmarks. For example, our 3B activated model improves over the 3B dense model by 5-8 points of absolute margin on domains such as math and coding, and rivals the performance of a 9B model.
Distribution alignment based transfer fusion frameworks on quantum devices for seeking quantum advantages
Nov 04, 2024



The scarcity of labelled data is specifically an urgent challenge in the field of quantum machine learning (QML). Two transfer fusion frameworks are proposed in this paper to predict the labels of a target domain data by aligning its distribution to a different but related labelled source domain on quantum devices. The frameworks fuses the quantum data from two different, but related domains through a quantum information infusion channel. The predicting tasks in the target domain can be achieved with quantum advantages by post-processing quantum measurement results. One framework, the quantum basic linear algebra subroutines (QBLAS) based implementation, can theoretically achieve the procedure of transfer fusion with quadratic speedup on a universal quantum computer. In addition, the other framework, a hardware-scalable architecture, is implemented on the noisy intermediate-scale quantum (NISQ) devices through a variational hybrid quantum-classical procedure. Numerical experiments on the synthetic and handwritten digits datasets demonstrate that the variatioinal transfer fusion (TF) framework can reach state-of-the-art (SOTA) quantum DA method performance.
EC-DIT: Scaling Diffusion Transformers with Adaptive Expert-Choice Routing
Oct 02, 2024



Diffusion transformers have been widely adopted for text-to-image synthesis. While scaling these models up to billions of parameters shows promise, the effectiveness of scaling beyond current sizes remains underexplored and challenging. By explicitly exploiting the computational heterogeneity of image generations, we develop a new family of Mixture-of-Experts (MoE) models (EC-DIT) for diffusion transformers with expert-choice routing. EC-DIT learns to adaptively optimize the compute allocated to understand the input texts and generate the respective image patches, enabling heterogeneous computation aligned with varying text-image complexities. This heterogeneity provides an efficient way of scaling EC-DIT up to 97 billion parameters and achieving significant improvements in training convergence, text-to-image alignment, and overall generation quality over dense models and conventional MoE models. Through extensive ablations, we show that EC-DIT demonstrates superior scalability and adaptive compute allocation by recognizing varying textual importance through end-to-end training. Notably, in text-to-image alignment evaluation, our largest models achieve a state-of-the-art GenEval score of 71.68% and still maintain competitive inference speed with intuitive interpretability.