 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning to Skip for Language Modeling
Paper and Code
Nov 26, 2023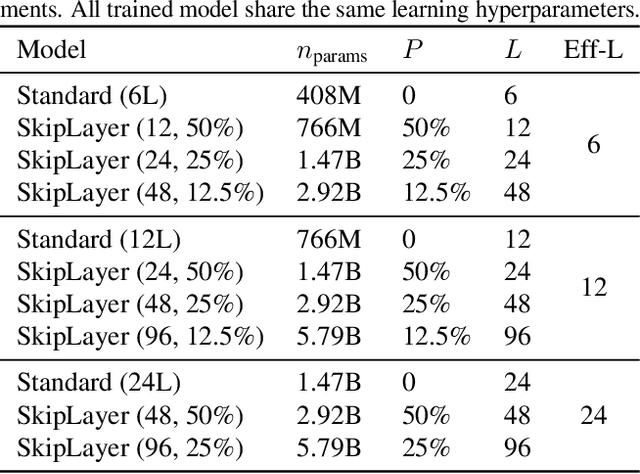
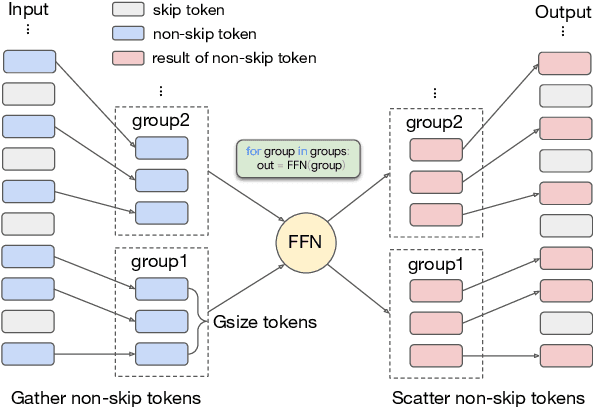
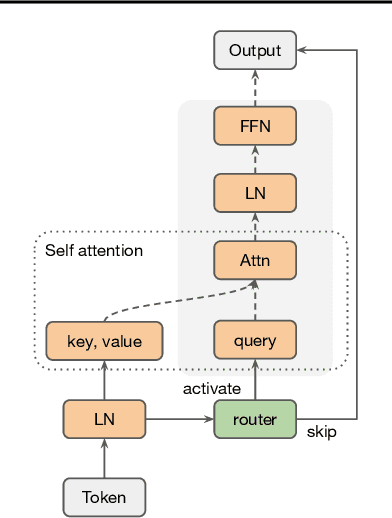
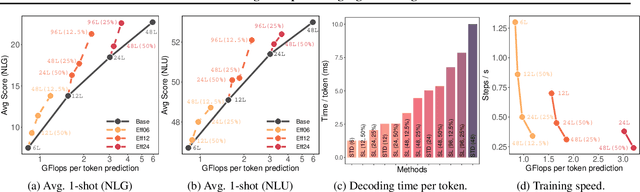
Overparameterized large-scale language models have impressive generalization performance of in-context few-shot learning. However, most language models allocate the same amount of parameters or computation to each token, disregarding the complexity or importance of the input data. We argue that in language model pretraining, a variable amount of computation should be assigned to different tokens, and this can be efficiently achieved via a simple routing mechanism. Different from conventional early stopping techniques where tokens can early exit at only early layers, we propose a more general method that dynamically skips the execution of a layer (or module) for any input token with a binary router. In our extensive evaluation across 24 NLP tasks, we demonstrate that the proposed method can significantly improve the 1-shot performance compared to other competitive baselines only at mild extra cost for inference.