 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMR. Judge: Multimodal Reasoner as a Judge
May 19, 2025The paradigm of using Large Language Models (LLMs) and Multimodal Large Language Models (MLLMs) as evaluative judges has emerged as an effective approach in RLHF and inference-time scaling. In this work, we propose Multimodal Reasoner as a Judge (MR. Judge), a paradigm for empowering general-purpose MLLMs judges with strong reasoning capabilities. Instead of directly assigning scores for each response, we formulate the judgement process as a reasoning-inspired multiple-choice problem. Specifically, the judge model first conducts deliberate reasoning covering different aspects of the responses and eventually selects the best response from them. This reasoning process not only improves the interpretibility of the judgement, but also greatly enhances the performance of MLLM judges. To cope with the lack of questions with scored responses, we propose the following strategy to achieve automatic annotation: 1) Reverse Response Candidates Synthesis: starting from a supervised fine-tuning (SFT) dataset, we treat the original response as the best candidate and prompt the MLLM to generate plausible but flawed negative candidates. 2) Text-based reasoning extraction: we carefully design a data synthesis pipeline for distilling the reasoning capability from a text-based reasoning model, which is adopted to enable the MLLM judges to regain complex reasoning ability via warm up supervised fine-tuning. Experiments demonstrate that our MR. Judge is effective across a wide range of tasks. Specifically, our MR. Judge-7B surpasses GPT-4o by 9.9% on VL-RewardBench, and improves performance on MM-Vet during inference-time scaling by up to 7.7%.
Instruction-Following Pruning for Large Language Models
Jan 07, 2025



With the rapid scaling of large language models (LLMs), structured pruning has become a widely used technique to learn efficient, smaller models from larger ones, delivering superior performance compared to training similarly sized models from scratch. In this paper, we move beyond the traditional static pruning approach of determining a fixed pruning mask for a model, and propose a dynamic approach to structured pruning. In our method, the pruning mask is input-dependent and adapts dynamically based on the information described in a user instruction. Our approach, termed "instruction-following pruning", introduces a sparse mask predictor that takes the user instruction as input and dynamically selects the most relevant model parameters for the given task. To identify and activate effective parameters, we jointly optimize the sparse mask predictor and the LLM, leveraging both instruction-following data and the pre-training corpus. Experimental results demonstrate the effectiveness of our approach on a wide range of evaluation benchmarks. For example, our 3B activated model improves over the 3B dense model by 5-8 points of absolute margin on domains such as math and coding, and rivals the performance of a 9B model.
Apple Intelligence Foundation Language Models
Jul 29, 2024



We present foundation language models developed to power Apple Intelligence features, including a ~3 billion parameter model designed to run efficiently on devices and a large server-based language model designed for Private Cloud Compute. These models are designed to perform a wide range of tasks efficiently, accurately, and responsibly. This report describes the model architecture, the data used to train the model, the training process, how the models are optimized for inference, and the evaluation results. We highlight our focus on Responsible AI and how the principles are applied throughout the model development.
Human Preferences and Robot Constraints Aware Shared Control for Smooth Follower Motion Execution
Jul 31, 2023With the continuous advancement of robot teleoperation technology, shared control is used to reduce the physical and mental load of the operator in teleoperation system. This paper proposes an alternating shared control framework for object grasping that considers both operator's preferences through their manual manipulation and the constraints of the follower robot. The switching between manual mode and automatic mode enables the operator to intervene the task according to their wishes. The generation of the grasping pose takes into account the current state of the operator's hand pose, as well as the manipulability of the robot. The object grasping experiment indicates that the use of the proposed grasping pose selection strategy leads to smoother follower movements when switching from manual mode to automatic mode.
VarCLR: Variable Semantic Representation Pre-training via Contrastive Learning
Dec 05, 2021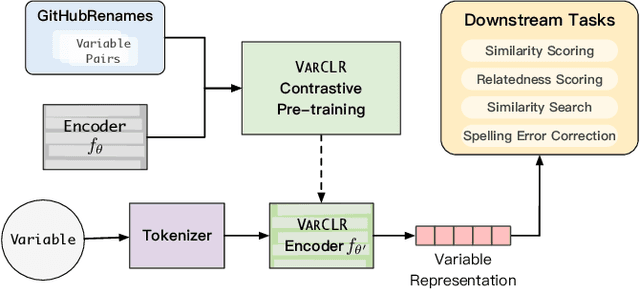
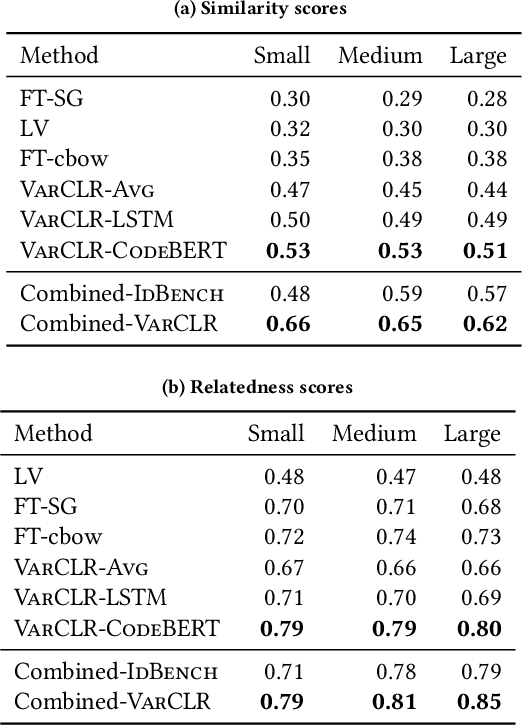
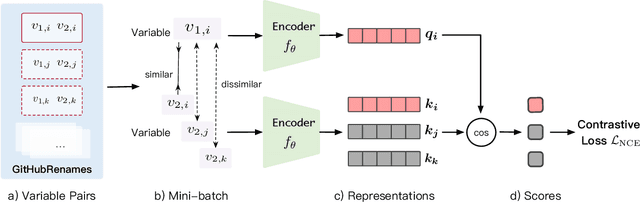
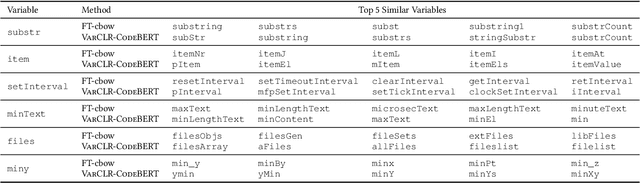
Variable names are critical for conveying intended program behavior. Machine learning-based program analysis methods use variable name representations for a wide range of tasks, such as suggesting new variable names and bug detection. Ideally, such methods could capture semantic relationships between names beyond syntactic similarity, e.g., the fact that the names average and mean are similar. Unfortunately, previous work has found that even the best of previous representation approaches primarily capture relatedness (whether two variables are linked at all), rather than similarity (whether they actually have the same meaning). We propose VarCLR, a new approach for learning semantic representations of variable names that effectively captures variable similarity in this stricter sense. We observe that this problem is an excellent fit for contrastive learning, which aims to minimize the distance between explicitly similar inputs, while maximizing the distance between dissimilar inputs. This requires labeled training data, and thus we construct a novel, weakly-supervised variable renaming dataset mined from GitHub edits. We show that VarCLR enables the effective application of sophisticated, general-purpose language models like BERT, to variable name representation and thus also to related downstream tasks like variable name similarity search or spelling correction. VarCLR produces models that significantly outperform the state-of-the-art on IdBench, an existing benchmark that explicitly captures variable similarity (as distinct from relatedness). Finally, we contribute a release of all data, code, and pre-trained models, aiming to provide a drop-in replacement for variable representations used in either existing or future program analyses that rely on variable names.
CogDL: An Extensive Toolkit for Deep Learning on Graphs
Mar 01, 2021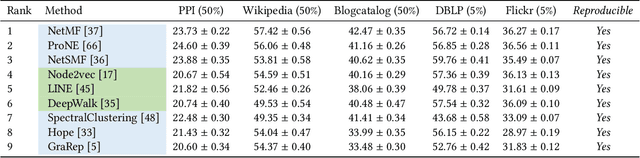
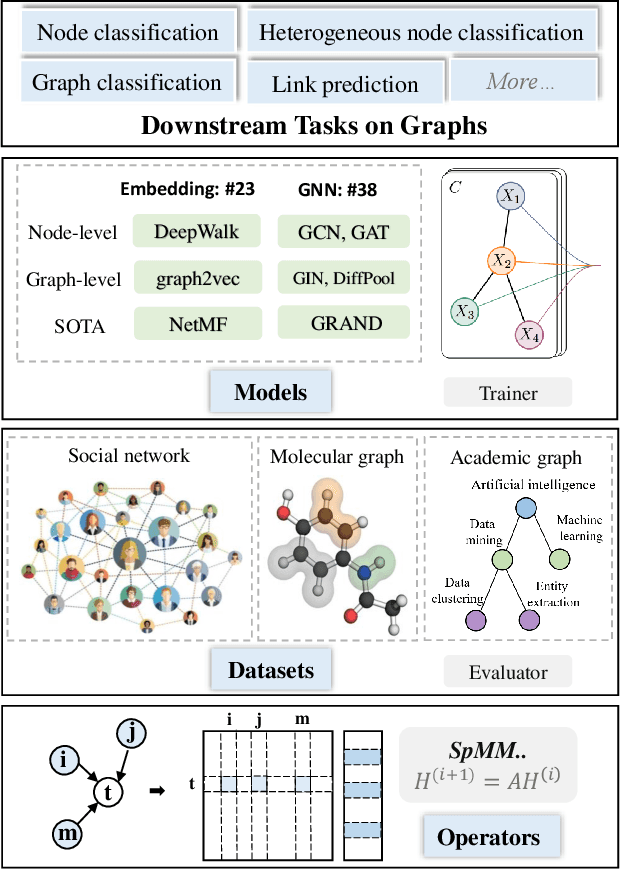
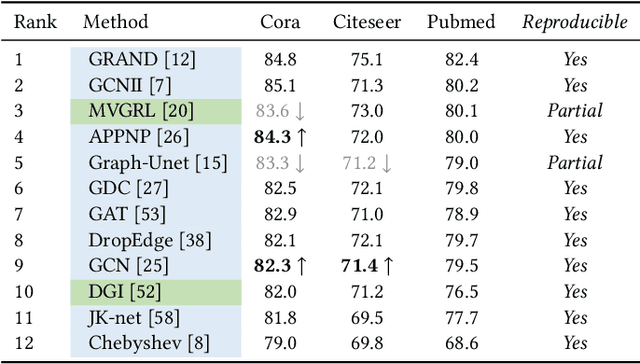
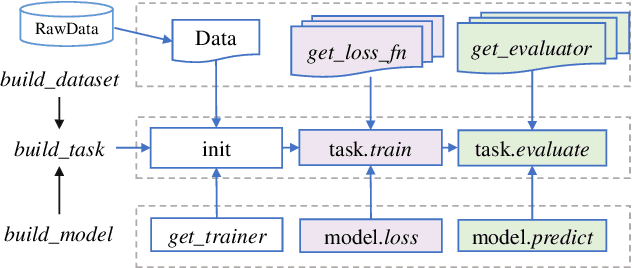
Graph representation learning aims to learn low-dimensional node embeddings for graphs. It is used in several real-world applications such as social network analysis and large-scale recommender systems. In this paper, we introduce CogDL, an extensive research toolkit for deep learning on graphs that allows researchers and developers to easily conduct experiments and build applications. It provides standard training and evaluation for the most important tasks in the graph domain, including node classification, link prediction, graph classification, and other graph tasks. For each task, it offers implementations of state-of-the-art models. The models in our toolkit are divided into two major parts, graph embedding methods and graph neural networks. Most of the graph embedding methods learn node-level or graph-level representations in an unsupervised way and preserves the graph properties such as structural information, while graph neural networks capture node features and work in semi-supervised or self-supervised settings. All models implemented in our toolkit can be easily reproducible for leaderboard results. Most models in CogDL are developed on top of PyTorch, and users can leverage the advantages of PyTorch to implement their own models. Furthermore, we demonstrate the effectiveness of CogDL for real-world applications in AMiner, which is a large academic database and system.
GCC: Graph Contrastive Coding for Graph Neural Network Pre-Training
Jul 02, 2020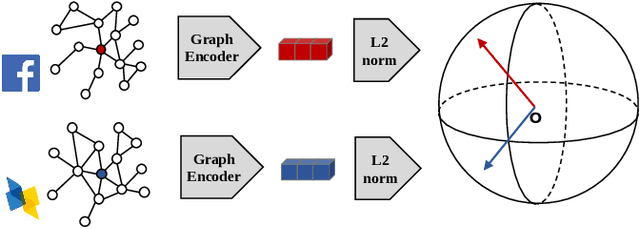
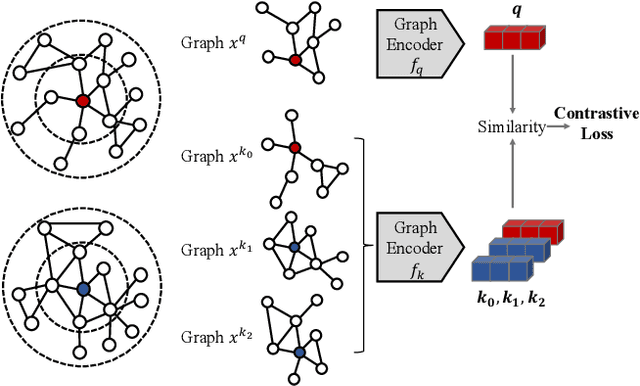
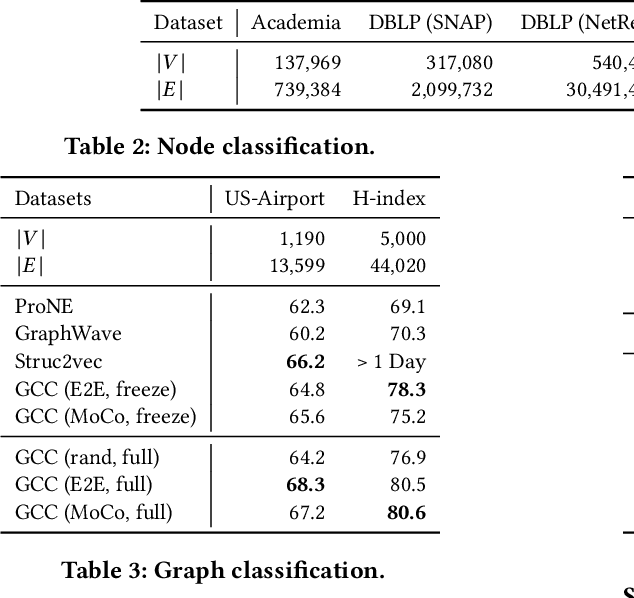
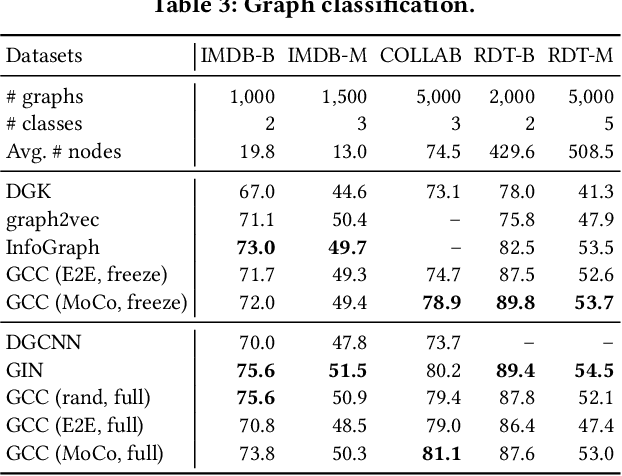
Graph representation learning has emerged as a powerful technique for addressing real-world problems. Various downstream graph learning tasks have benefited from its recent developments, such as node classification, similarity search, and graph classification. However, prior arts on graph representation learning focus on domain specific problems and train a dedicated model for each graph dataset, which is usually non-transferable to out-of-domain data. Inspired by the recent advances in pre-training from natural language processing and computer vision, we design Graph Contrastive Coding (GCC) -- a self-supervised graph neural network pre-training framework -- to capture the universal network topological properties across multiple networks. We design GCC's pre-training task as subgraph instance discrimination in and across networks and leverage contrastive learning to empower graph neural networks to learn the intrinsic and transferable structural representations. We conduct extensive experiments on three graph learning tasks and ten graph datasets. The results show that GCC pre-trained on a collection of diverse datasets can achieve competitive or better performance to its task-specific and trained-from-scratch counterparts. This suggests that the pre-training and fine-tuning paradigm presents great potential for graph representation learning.
Towards Knowledge-Based Recommender Dialog System
Sep 03, 2019
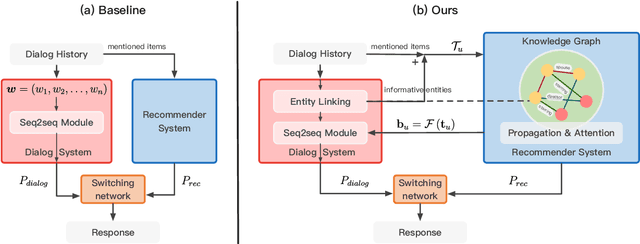

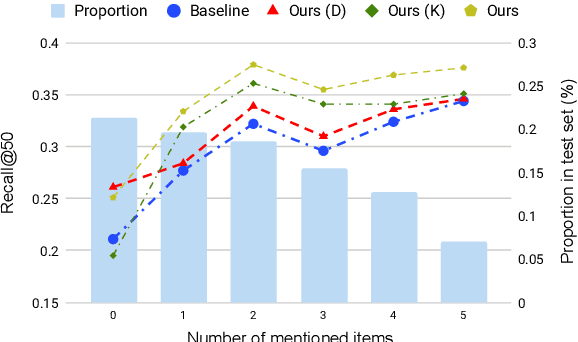
In this paper, we propose a novel end-to-end framework called KBRD, which stands for Knowledge-Based Recommender Dialog System. It integrates the recommender system and the dialog generation system. The dialog system can enhance the performance of the recommendation system by introducing knowledge-grounded information about users' preferences, and the recommender system can improve that of the dialog generation system by providing recommendation-aware vocabulary bias. Experimental results demonstrate that our proposed model has significant advantages over the baselines in both the evaluation of dialog generation and recommendation. A series of analyses show that the two systems can bring mutual benefits to each other, and the introduced knowledge contributes to both their performances.
Cognitive Graph for Multi-Hop Reading Comprehension at Scale
Jun 04, 2019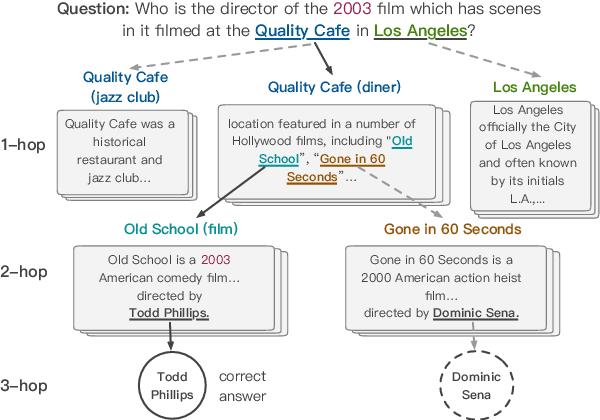
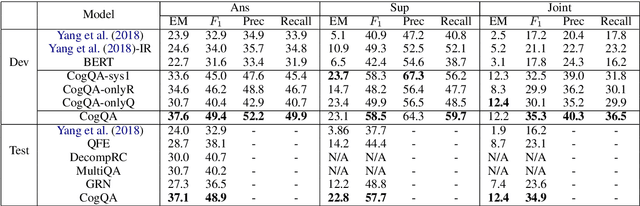
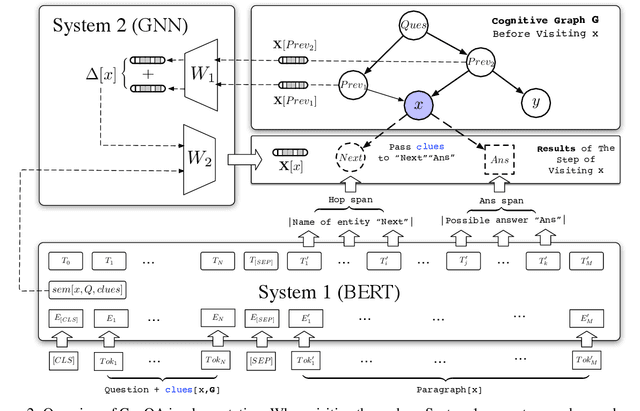
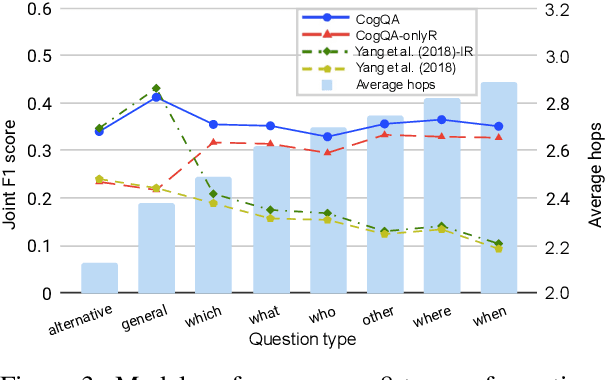
We propose a new CogQA framework for multi-hop question answering in web-scale documents. Inspired by the dual process theory in cognitive science, the framework gradually builds a \textit{cognitive graph} in an iterative process by coordinating an implicit extraction module (System 1) and an explicit reasoning module (System 2). While giving accurate answers, our framework further provides explainable reasoning paths. Specifically, our implementation based on BERT and graph neural network efficiently handles millions of documents for multi-hop reasoning questions in the HotpotQA fullwiki dataset, achieving a winning joint $F_1$ score of 34.9 on the leaderboard, compared to 23.6 of the best competitor.
Towards Knowledge-Based Personalized Product Description Generation in E-commerce
Apr 30, 2019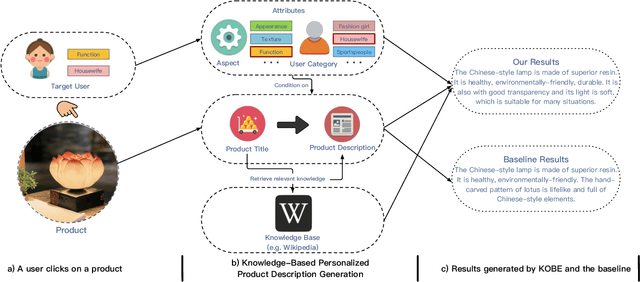
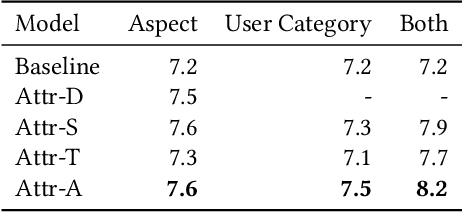
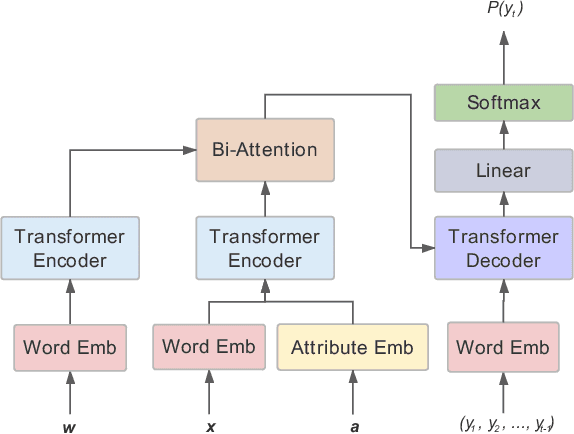
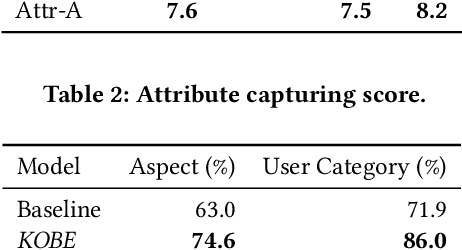
Quality product descriptions are critical for providing competitive customer experience in an E-commerce platform. An accurate and attractive description not only helps customers make an informed decision but also improves the likelihood of purchase. However, crafting a successful product description is tedious and highly time-consuming. Due to its importance, automating the product description generation has attracted considerable interests from both research and industrial communities. Existing methods mainly use templates or statistical methods, and their performance could be rather limited. In this paper, we explore a new way to generate the personalized product description by combining the power of neural networks and knowledge base. Specifically, we propose a KnOwledge Based pErsonalized (or KOBE) product description generation model in the context of E-commerce. In KOBE, we extend the encoder-decoder framework, the Transformer, to a sequence modeling formulation using self-attention. In order to make the description both informative and personalized, KOBE considers a variety of important factors during text generation, including product aspects, user categories, and knowledge base, etc. Experiments on real-world datasets demonstrate that the proposed method out-performs the baseline on various metrics. KOBE can achieve an improvement of 9.7% over state-of-the-arts in terms of BLEU. We also present several case studies as the anecdotal evidence to further prove the effectiveness of the proposed approach. The framework has been deployed in Taobao, the largest online E-commerce platform in China.