 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDoes AI-Assisted Coding Deliver? A Difference-in-Differences Study of Cursor's Impact on Software Projects
Nov 13, 2025Large language models (LLMs) have demonstrated the promise to revolutionize the field of software engineering. Among other things, LLM agents are rapidly gaining momentum in their application to software development, with practitioners claiming a multifold productivity increase after adoption. Yet, empirical evidence is lacking around these claims. In this paper, we estimate the causal effect of adopting a widely popular LLM agent assistant, namely Cursor, on development velocity and software quality. The estimation is enabled by a state-of-the-art difference-in-differences design comparing Cursor-adopting GitHub projects with a matched control group of similar GitHub projects that do not use Cursor. We find that the adoption of Cursor leads to a significant, large, but transient increase in project-level development velocity, along with a significant and persistent increase in static analysis warnings and code complexity. Further panel generalized method of moments estimation reveals that the increase in static analysis warnings and code complexity acts as a major factor causing long-term velocity slowdown. Our study carries implications for software engineering practitioners, LLM agent assistant designers, and researchers.
Speed at the Cost of Quality? The Impact of LLM Agent Assistance on Software Development
Nov 06, 2025Large language models (LLMs) have demonstrated the promise to revolutionize the field of software engineering. Among other things, LLM agents are rapidly gaining momentum in their application to software development, with practitioners claiming a multifold productivity increase after adoption. Yet, empirical evidence is lacking around these claims. In this paper, we estimate the causal effect of adopting a widely popular LLM agent assistant, namely Cursor, on development velocity and software quality. The estimation is enabled by a state-of-the-art difference-in-differences design comparing Cursor-adopting GitHub projects with a matched control group of similar GitHub projects that do not use Cursor. We find that the adoption of Cursor leads to a significant, large, but transient increase in project-level development velocity, along with a significant and persistent increase in static analysis warnings and code complexity. Further panel generalized method of moments estimation reveals that the increase in static analysis warnings and code complexity acts as a major factor causing long-term velocity slowdown. Our study carries implications for software engineering practitioners, LLM agent assistant designers, and researchers.
In-IDE Generation-based Information Support with a Large Language Model
Jul 17, 2023Developers often face challenges in code understanding, which is crucial for building and maintaining high-quality software systems. Code comments and documentation can provide some context for the code, but are often scarce or missing. This challenge has become even more pressing with the rise of large language model (LLM) based code generation tools. To understand unfamiliar code, most software developers rely on general-purpose search engines to search through various programming information resources, which often requires multiple iterations of query rewriting and information foraging. More recently, developers have turned to online chatbots powered by LLMs, such as ChatGPT, which can provide more customized responses but also incur more overhead as developers need to communicate a significant amount of context to the LLM via a textual interface. In this study, we provide the investigation of an LLM-based conversational UI in the IDE. We aim to understand the promises and obstacles for tools powered by LLMs that are contextually aware, in that they automatically leverage the developer's programming context to answer queries. To this end, we develop an IDE Plugin that allows users to query back-ends such as OpenAI's GPT-3.5 and GPT-4 with high-level requests, like: explaining a highlighted section of code, explaining key domain-specific terms, or providing usage examples for an API. We conduct an exploratory user study with 32 participants to understand the usefulness and effectiveness, as well as individual preferences in the usage of, this LLM-powered information support tool. The study confirms that this approach can aid code understanding more effectively than web search, but the degree of the benefit differed by participants' experience levels.
VarCLR: Variable Semantic Representation Pre-training via Contrastive Learning
Dec 05, 2021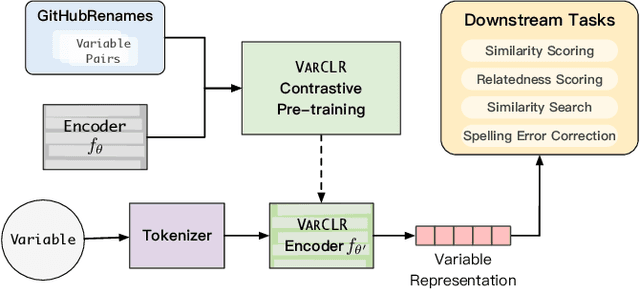
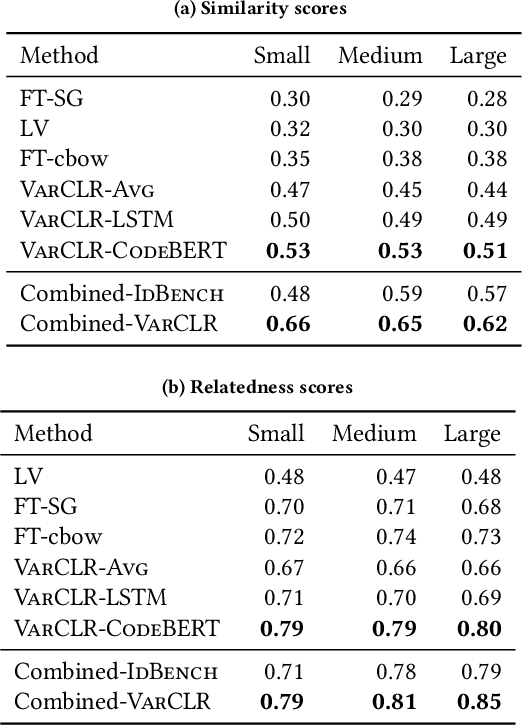
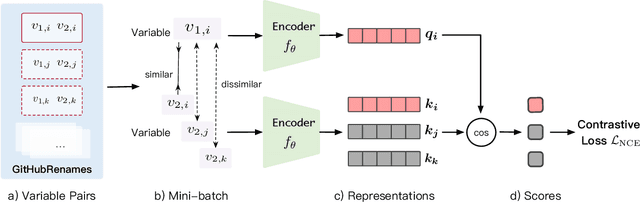
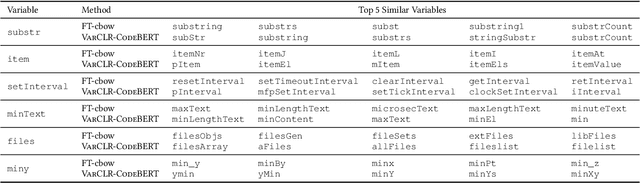
Variable names are critical for conveying intended program behavior. Machine learning-based program analysis methods use variable name representations for a wide range of tasks, such as suggesting new variable names and bug detection. Ideally, such methods could capture semantic relationships between names beyond syntactic similarity, e.g., the fact that the names average and mean are similar. Unfortunately, previous work has found that even the best of previous representation approaches primarily capture relatedness (whether two variables are linked at all), rather than similarity (whether they actually have the same meaning). We propose VarCLR, a new approach for learning semantic representations of variable names that effectively captures variable similarity in this stricter sense. We observe that this problem is an excellent fit for contrastive learning, which aims to minimize the distance between explicitly similar inputs, while maximizing the distance between dissimilar inputs. This requires labeled training data, and thus we construct a novel, weakly-supervised variable renaming dataset mined from GitHub edits. We show that VarCLR enables the effective application of sophisticated, general-purpose language models like BERT, to variable name representation and thus also to related downstream tasks like variable name similarity search or spelling correction. VarCLR produces models that significantly outperform the state-of-the-art on IdBench, an existing benchmark that explicitly captures variable similarity (as distinct from relatedness). Finally, we contribute a release of all data, code, and pre-trained models, aiming to provide a drop-in replacement for variable representations used in either existing or future program analyses that rely on variable names.
Incorporating External Knowledge through Pre-training for Natural Language to Code Generation
Apr 20, 2020
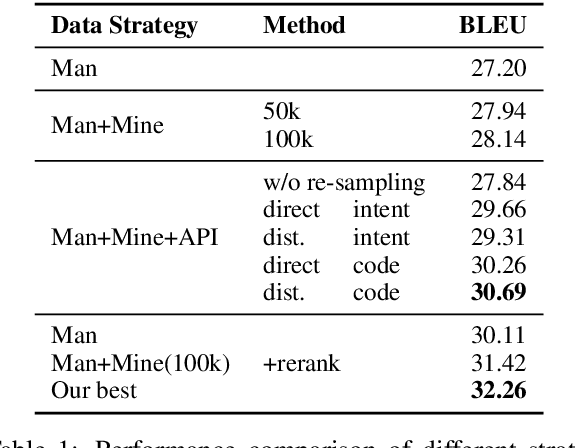


Open-domain code generation aims to generate code in a general-purpose programming language (such as Python) from natural language (NL) intents. Motivated by the intuition that developers usually retrieve resources on the web when writing code, we explore the effectiveness of incorporating two varieties of external knowledge into NL-to-code generation: automatically mined NL-code pairs from the online programming QA forum StackOverflow and programming language API documentation. Our evaluations show that combining the two sources with data augmentation and retrieval-based data re-sampling improves the current state-of-the-art by up to 2.2% absolute BLEU score on the code generation testbed CoNaLa. The code and resources are available at https://github.com/neulab/external-knowledge-codegen.
Detecting and Characterizing Bots that Commit Code
Mar 27, 2020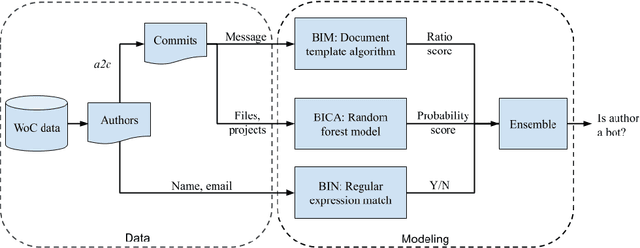

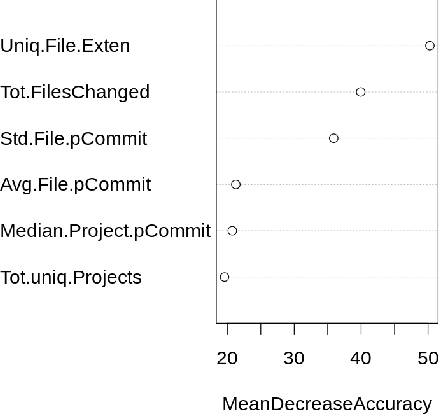
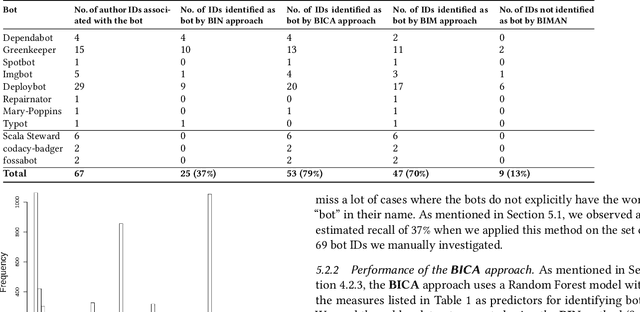
Background: Some developer activity traditionally performed manually, such as making code commits, opening, managing, or closing issues is increasingly subject to automation in many OSS projects. Specifically, such activity is often performed by tools that react to events or run at specific times. We refer to such automation tools as bots and, in many software mining scenarios related to developer productivity or code quality it is desirable to identify bots in order to separate their actions from actions of individuals. Aim: Find an automated way of identifying bots and code committed by these bots, and to characterize the types of bots based on their activity patterns. Method and Result: We propose BIMAN, a systematic approach to detect bots using author names, commit messages, files modified by the commit, and projects associated with the ommits. For our test data, the value for AUC-ROC was 0.9. We also characterized these bots based on the time patterns of their code commits and the types of files modified, and found that they primarily work with documentation files and web pages, and these files are most prevalent in HTML and JavaScript ecosystems. We have compiled a shareable dataset containing detailed information about 461 bots we found (all of whom have more than 1000 commits) and 13,762,430 commits they created.
Learning to Mine Aligned Code and Natural Language Pairs from Stack Overflow
May 23, 2018

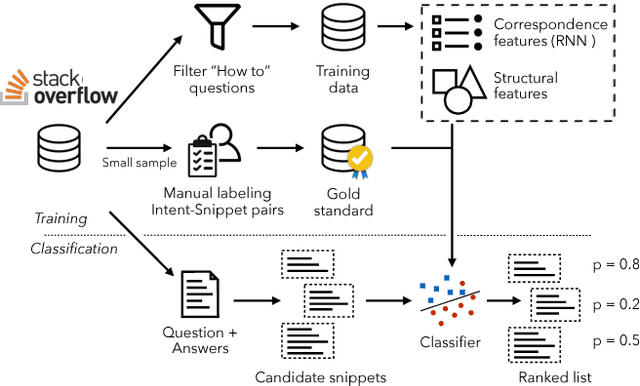
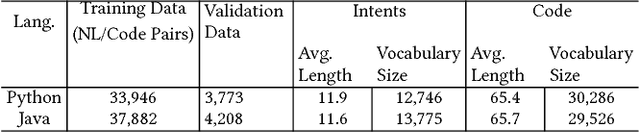
For tasks like code synthesis from natural language, code retrieval, and code summarization, data-driven models have shown great promise. However, creating these models require parallel data between natural language (NL) and code with fine-grained alignments. Stack Overflow (SO) is a promising source to create such a data set: the questions are diverse and most of them have corresponding answers with high-quality code snippets. However, existing heuristic methods (e.g., pairing the title of a post with the code in the accepted answer) are limited both in their coverage and the correctness of the NL-code pairs obtained. In this paper, we propose a novel method to mine high-quality aligned data from SO using two sets of features: hand-crafted features considering the structure of the extracted snippets, and correspondence features obtained by training a probabilistic model to capture the correlation between NL and code using neural networks. These features are fed into a classifier that determines the quality of mined NL-code pairs. Experiments using Python and Java as test beds show that the proposed method greatly expands coverage and accuracy over existing mining methods, even when using only a small number of labeled examples. Further, we find that reasonable results are achieved even when training the classifier on one language and testing on another, showing promise for scaling NL-code mining to a wide variety of programming languages beyond those for which we are able to annotate data.