 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRepresentation of Developer Expertise in Open Source Software
May 20, 2020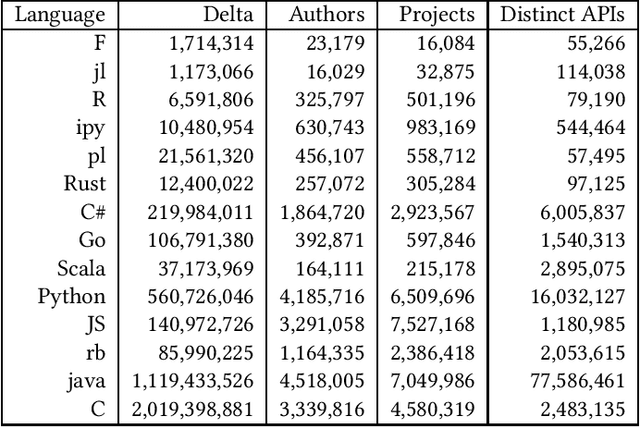



With tens of millions of projects and developers, the OSS ecosystem is both vibrant and intimidating. On one hand, it hosts the source code for the most critical infrastructures and has the most brilliant developers as contributors, while on the other hand, poor quality or even malicious software, and novice developers abound. External contributions are critical to OSS projects, but the chances their contributions are accepted or even considered depend on the trust between maintainers and contributors. Such trust is built over repeated interactions and coding platforms provide signals of project or developer quality via measures of activity (commits), and social relationships (followers/stars) to facilitate trust. These signals, however, do not represent the specific expertise of a developer. We, therefore, aim to address this gap by defining the skill space for APIs, developers, and projects that reflects what developers know (and projects need) more precisely than could be obtained via aggregate activity counts, and more generally than pointing to individual files developers have changed in the past. Specifically, we use the World of Code infrastructure to extract the complete set of APIs in the files changed by all open source developers. We use that data to represent APIs, developers, and projects in the skill space, and evaluate if the alignment measures in the skill space can predict whether or not the developers use new APIs, join new projects, or get their pull requests accepted. We also check if the developers' representation in the skill space aligns with their self-reported expertise. Our results suggest that the proposed embedding in the skill space achieves our aims and may serve not only as a signal to increase trust (and efficiency) of open source ecosystems, but may also allow more detailed investigations of other phenomena related to developer proficiency and learning.
Detecting and Characterizing Bots that Commit Code
Mar 27, 2020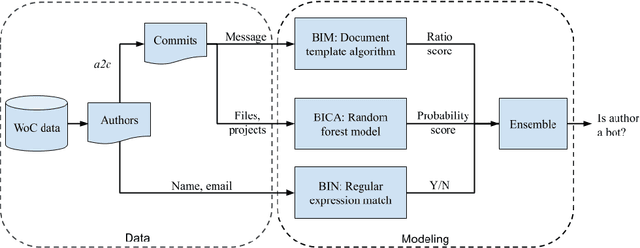

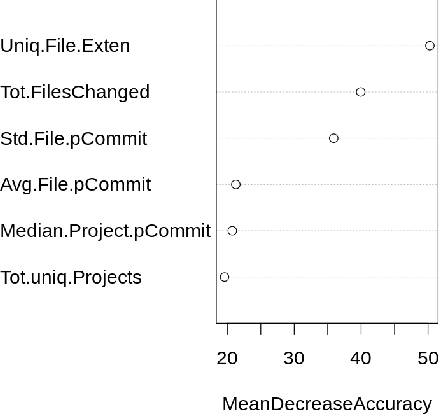
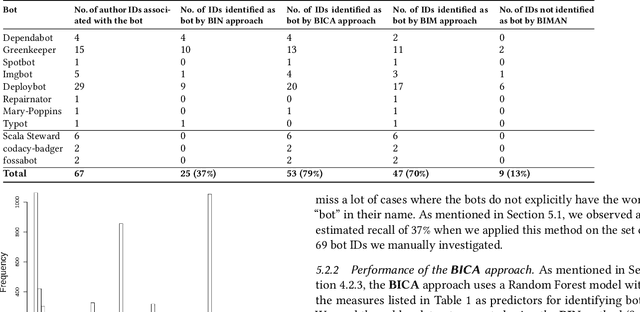
Background: Some developer activity traditionally performed manually, such as making code commits, opening, managing, or closing issues is increasingly subject to automation in many OSS projects. Specifically, such activity is often performed by tools that react to events or run at specific times. We refer to such automation tools as bots and, in many software mining scenarios related to developer productivity or code quality it is desirable to identify bots in order to separate their actions from actions of individuals. Aim: Find an automated way of identifying bots and code committed by these bots, and to characterize the types of bots based on their activity patterns. Method and Result: We propose BIMAN, a systematic approach to detect bots using author names, commit messages, files modified by the commit, and projects associated with the ommits. For our test data, the value for AUC-ROC was 0.9. We also characterized these bots based on the time patterns of their code commits and the types of files modified, and found that they primarily work with documentation files and web pages, and these files are most prevalent in HTML and JavaScript ecosystems. We have compiled a shareable dataset containing detailed information about 461 bots we found (all of whom have more than 1000 commits) and 13,762,430 commits they created.