 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFast, Fine-Grained Equivalence Checking for Neural Decompilers
Jan 08, 2025
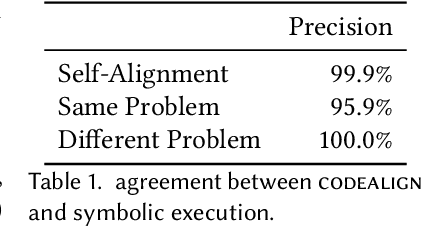
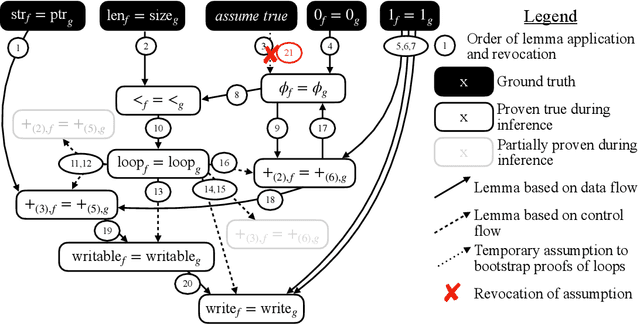
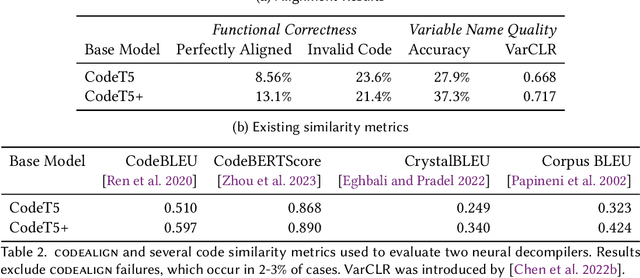
Neural decompilers are machine learning models that reconstruct the source code from an executable program. Critical to the lifecycle of any machine learning model is an evaluation of its effectiveness. However, existing techniques for evaluating neural decompilation models have substantial weaknesses, especially when it comes to showing the correctness of the neural decompiler's predictions. To address this, we introduce codealign, a novel instruction-level code equivalence technique designed for neural decompilers. We provide a formal definition of a relation between equivalent instructions, which we term an equivalence alignment. We show how codealign generates equivalence alignments, then evaluate codealign by comparing it with symbolic execution. Finally, we show how the information codealign provides-which parts of the functions are equivalent and how well the variable names match-is substantially more detailed than existing state-of-the-art evaluation metrics, which report unitless numbers measuring similarity.
VarCLR: Variable Semantic Representation Pre-training via Contrastive Learning
Dec 05, 2021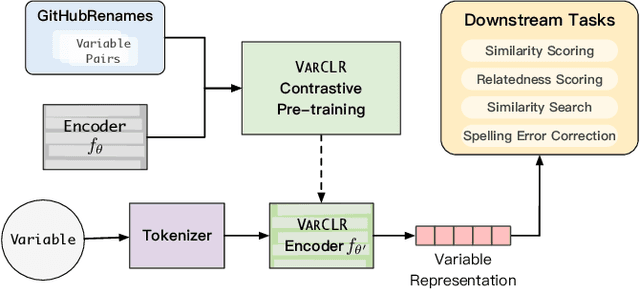
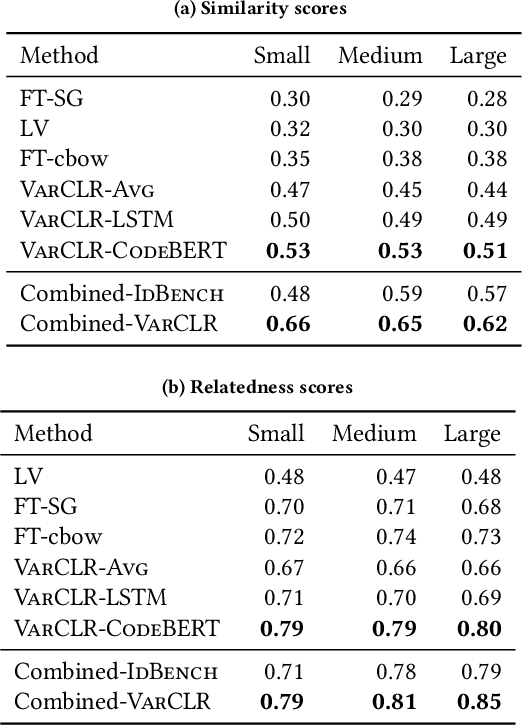
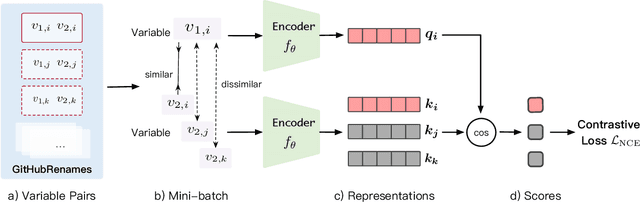
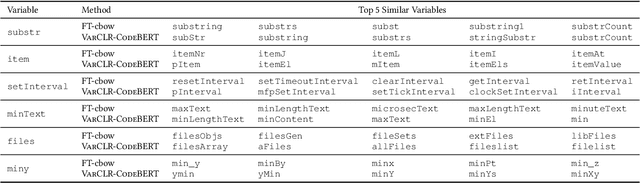
Variable names are critical for conveying intended program behavior. Machine learning-based program analysis methods use variable name representations for a wide range of tasks, such as suggesting new variable names and bug detection. Ideally, such methods could capture semantic relationships between names beyond syntactic similarity, e.g., the fact that the names average and mean are similar. Unfortunately, previous work has found that even the best of previous representation approaches primarily capture relatedness (whether two variables are linked at all), rather than similarity (whether they actually have the same meaning). We propose VarCLR, a new approach for learning semantic representations of variable names that effectively captures variable similarity in this stricter sense. We observe that this problem is an excellent fit for contrastive learning, which aims to minimize the distance between explicitly similar inputs, while maximizing the distance between dissimilar inputs. This requires labeled training data, and thus we construct a novel, weakly-supervised variable renaming dataset mined from GitHub edits. We show that VarCLR enables the effective application of sophisticated, general-purpose language models like BERT, to variable name representation and thus also to related downstream tasks like variable name similarity search or spelling correction. VarCLR produces models that significantly outperform the state-of-the-art on IdBench, an existing benchmark that explicitly captures variable similarity (as distinct from relatedness). Finally, we contribute a release of all data, code, and pre-trained models, aiming to provide a drop-in replacement for variable representations used in either existing or future program analyses that rely on variable names.