 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMetadata-Induced Contrastive Learning for Zero-Shot Multi-Label Text Classification
Feb 11, 2022
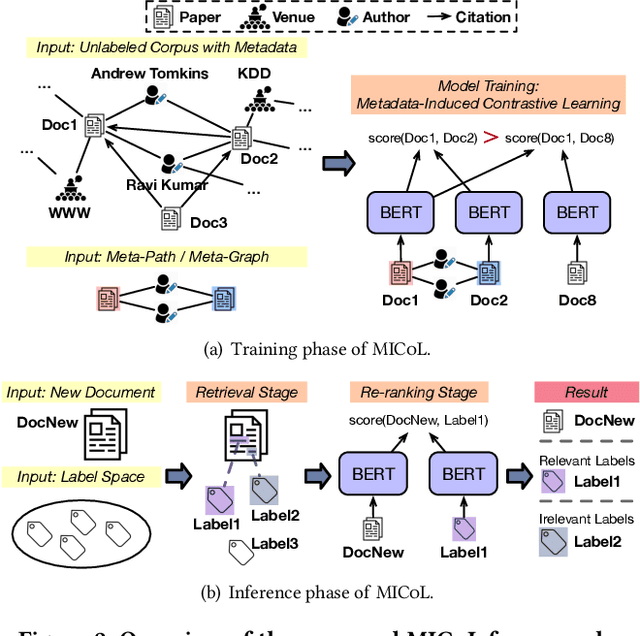
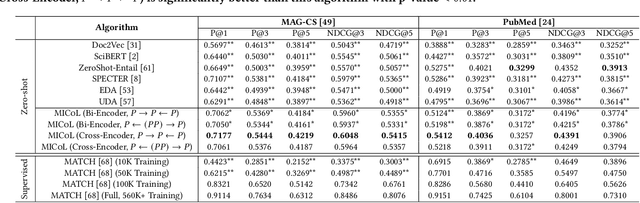
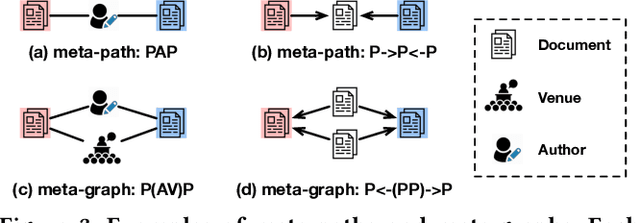
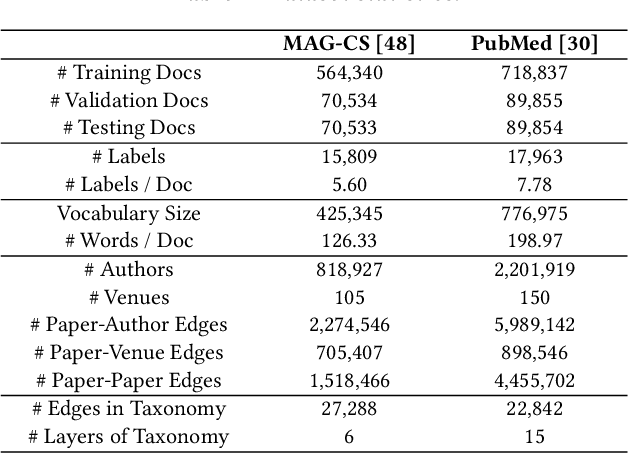
Large-scale multi-label text classification (LMTC) aims to associate a document with its relevant labels from a large candidate set. Most existing LMTC approaches rely on massive human-annotated training data, which are often costly to obtain and suffer from a long-tailed label distribution (i.e., many labels occur only a few times in the training set). In this paper, we study LMTC under the zero-shot setting, which does not require any annotated documents with labels and only relies on label surface names and descriptions. To train a classifier that calculates the similarity score between a document and a label, we propose a novel metadata-induced contrastive learning (MICoL) method. Different from previous text-based contrastive learning techniques, MICoL exploits document metadata (e.g., authors, venues, and references of research papers), which are widely available on the Web, to derive similar document-document pairs. Experimental results on two large-scale datasets show that: (1) MICoL significantly outperforms strong zero-shot text classification and contrastive learning baselines; (2) MICoL is on par with the state-of-the-art supervised metadata-aware LMTC method trained on 10K-200K labeled documents; and (3) MICoL tends to predict more infrequent labels than supervised methods, thus alleviates the deteriorated performance on long-tailed labels.
MATCH: Metadata-Aware Text Classification in A Large Hierarchy
Feb 15, 2021
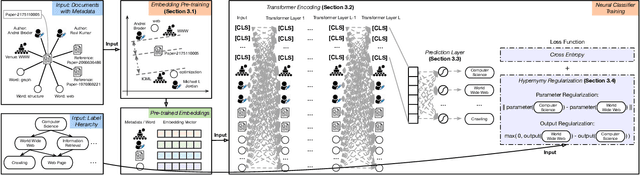
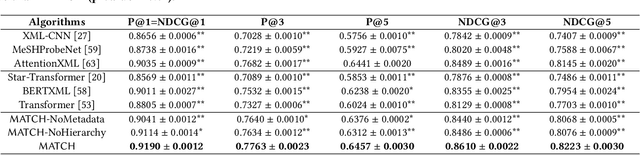
Multi-label text classification refers to the problem of assigning each given document its most relevant labels from the label set. Commonly, the metadata of the given documents and the hierarchy of the labels are available in real-world applications. However, most existing studies focus on only modeling the text information, with a few attempts to utilize either metadata or hierarchy signals, but not both of them. In this paper, we bridge the gap by formalizing the problem of metadata-aware text classification in a large label hierarchy (e.g., with tens of thousands of labels). To address this problem, we present the MATCH solution -- an end-to-end framework that leverages both metadata and hierarchy information. To incorporate metadata, we pre-train the embeddings of text and metadata in the same space and also leverage the fully-connected attentions to capture the interrelations between them. To leverage the label hierarchy, we propose different ways to regularize the parameters and output probability of each child label by its parents. Extensive experiments on two massive text datasets with large-scale label hierarchies demonstrate the effectiveness of MATCH over state-of-the-art deep learning baselines.
GCC: Graph Contrastive Coding for Graph Neural Network Pre-Training
Jul 02, 2020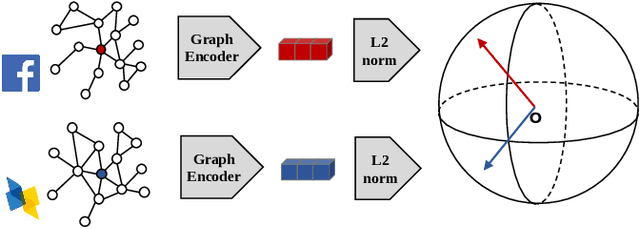
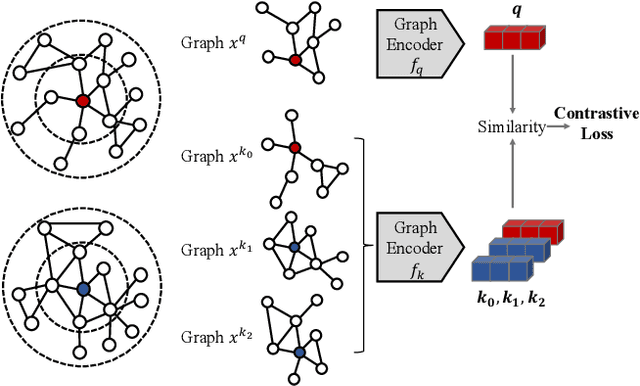
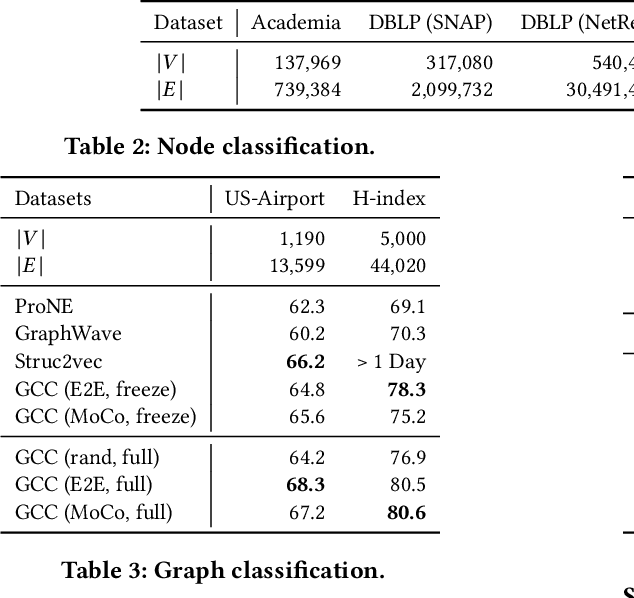
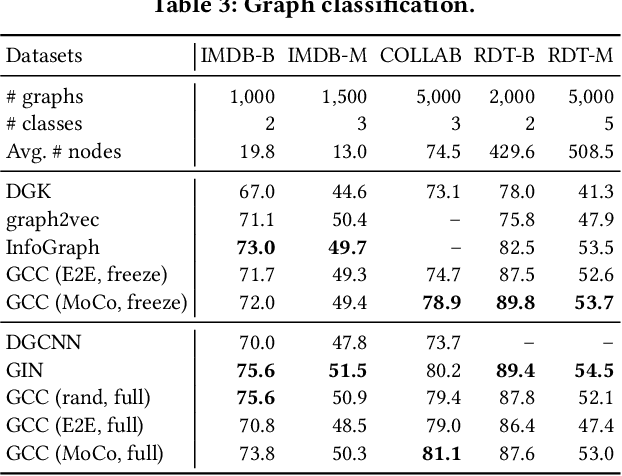
Graph representation learning has emerged as a powerful technique for addressing real-world problems. Various downstream graph learning tasks have benefited from its recent developments, such as node classification, similarity search, and graph classification. However, prior arts on graph representation learning focus on domain specific problems and train a dedicated model for each graph dataset, which is usually non-transferable to out-of-domain data. Inspired by the recent advances in pre-training from natural language processing and computer vision, we design Graph Contrastive Coding (GCC) -- a self-supervised graph neural network pre-training framework -- to capture the universal network topological properties across multiple networks. We design GCC's pre-training task as subgraph instance discrimination in and across networks and leverage contrastive learning to empower graph neural networks to learn the intrinsic and transferable structural representations. We conduct extensive experiments on three graph learning tasks and ten graph datasets. The results show that GCC pre-trained on a collection of diverse datasets can achieve competitive or better performance to its task-specific and trained-from-scratch counterparts. This suggests that the pre-training and fine-tuning paradigm presents great potential for graph representation learning.
GPT-GNN: Generative Pre-Training of Graph Neural Networks
Jun 27, 2020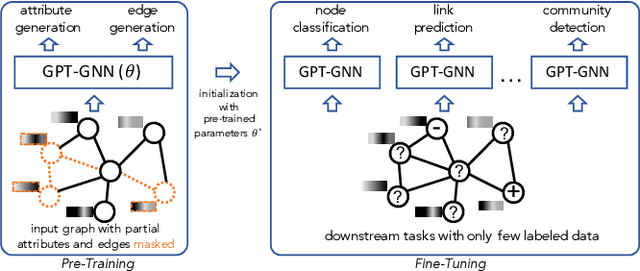
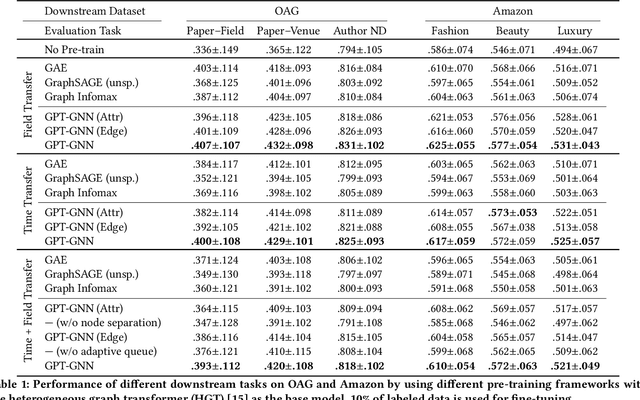
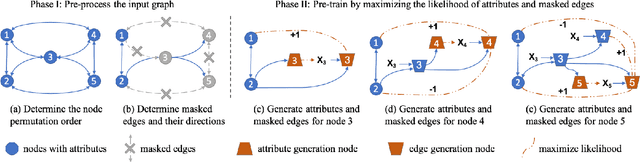
Graph neural networks (GNNs) have been demonstrated to be powerful in modeling graph-structured data. However, training GNNs usually requires abundant task-specific labeled data, which is often arduously expensive to obtain. One effective way to reduce the labeling effort is to pre-train an expressive GNN model on unlabeled data with self-supervision and then transfer the learned model to downstream tasks with only a few labels. In this paper, we present the GPT-GNN framework to initialize GNNs by generative pre-training. GPT-GNN introduces a self-supervised attributed graph generation task to pre-train a GNN so that it can capture the structural and semantic properties of the graph. We factorize the likelihood of the graph generation into two components: 1) Attribute Generation and 2) Edge Generation. By modeling both components, GPT-GNN captures the inherent dependency between node attributes and graph structure during the generative process. Comprehensive experiments on the billion-scale Open Academic Graph and Amazon recommendation data demonstrate that GPT-GNN significantly outperforms state-of-the-art GNN models without pre-training by up to 9.1% across various downstream tasks.
CORD-19: The Covid-19 Open Research Dataset
Apr 25, 2020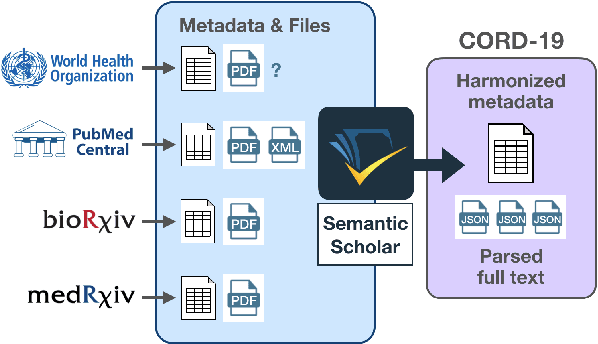
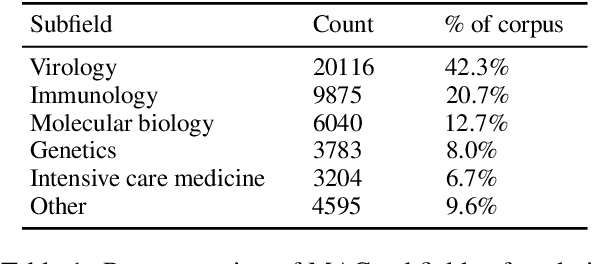
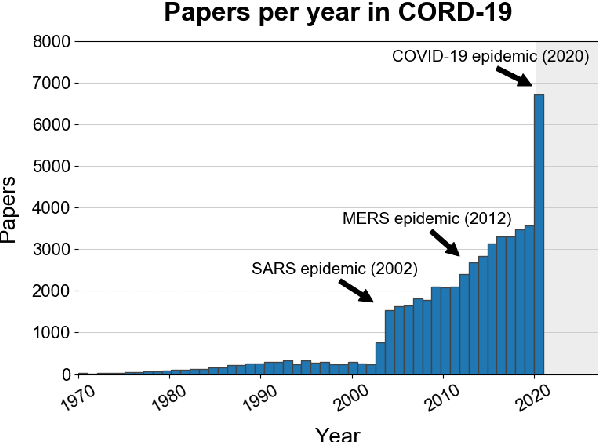

The Covid-19 Open Research Dataset (CORD-19) is a growing resource of scientific papers on Covid-19 and related historical coronavirus research. CORD-19 is designed to facilitate the development of text mining and information retrieval systems over its rich collection of metadata and structured full text papers. Since its release, CORD-19 has been downloaded over 75K times and has served as the basis of many Covid-19 text mining and discovery systems. In this article, we describe the mechanics of dataset construction, highlighting challenges and key design decisions, provide an overview of how CORD-19 has been used, and preview tools and upcoming shared tasks built around the dataset. We hope this resource will continue to bring together the computing community, biomedical experts, and policy makers in the search for effective treatments and management policies for Covid-19.
Heterogeneous Graph Transformer
Mar 03, 2020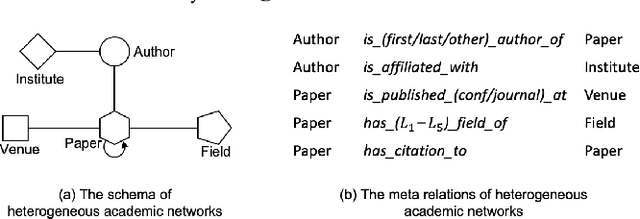

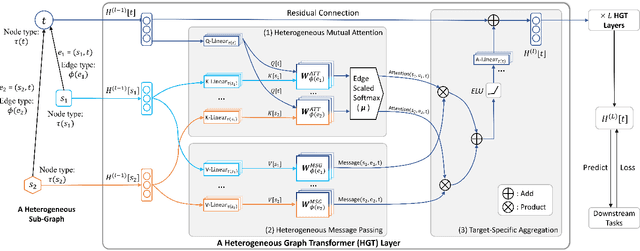

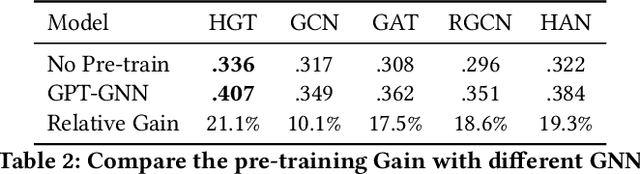
Recent years have witnessed the emerging success of graph neural networks (GNNs) for modeling structured data. However, most GNNs are designed for homogeneous graphs, in which all nodes and edges belong to the same types, making them infeasible to represent heterogeneous structures. In this paper, we present the Heterogeneous Graph Transformer (HGT) architecture for modeling Web-scale heterogeneous graphs. To model heterogeneity, we design node- and edge-type dependent parameters to characterize the heterogeneous attention over each edge, empowering HGT to maintain dedicated representations for different types of nodes and edges. To handle dynamic heterogeneous graphs, we introduce the relative temporal encoding technique into HGT, which is able to capture the dynamic structural dependency with arbitrary durations. To handle Web-scale graph data, we design the heterogeneous mini-batch graph sampling algorithm---HGSampling---for efficient and scalable training. Extensive experiments on the Open Academic Graph of 179 million nodes and 2 billion edges show that the proposed HGT model consistently outperforms all the state-of-the-art GNN baselines by 9%--21% on various downstream tasks.
TaxoExpan: Self-supervised Taxonomy Expansion with Position-Enhanced Graph Neural Network
Jan 26, 2020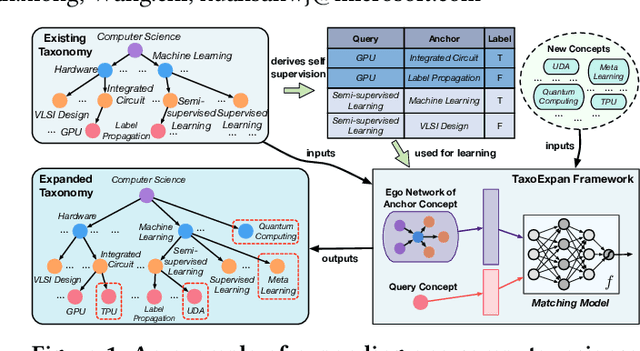
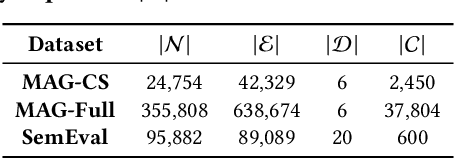
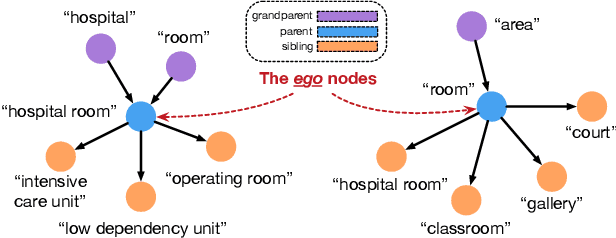

Taxonomies consist of machine-interpretable semantics and provide valuable knowledge for many web applications. For example, online retailers (e.g., Amazon and eBay) use taxonomies for product recommendation, and web search engines (e.g., Google and Bing) leverage taxonomies to enhance query understanding. Enormous efforts have been made on constructing taxonomies either manually or semi-automatically. However, with the fast-growing volume of web content, existing taxonomies will become outdated and fail to capture emerging knowledge. Therefore, in many applications, dynamic expansions of an existing taxonomy are in great demand. In this paper, we study how to expand an existing taxonomy by adding a set of new concepts. We propose a novel self-supervised framework, named TaxoExpan, which automatically generates a set of <query concept, anchor concept> pairs from the existing taxonomy as training data. Using such self-supervision data, TaxoExpan learns a model to predict whether a query concept is the direct hyponym of an anchor concept. We develop two innovative techniques in TaxoExpan: (1) a position-enhanced graph neural network that encodes the local structure of an anchor concept in the existing taxonomy, and (2) a noise-robust training objective that enables the learned model to be insensitive to the label noise in the self-supervision data. Extensive experiments on three large-scale datasets from different domains demonstrate both the effectiveness and the efficiency of TaxoExpan for taxonomy expansion.
NetSMF: Large-Scale Network Embedding as Sparse Matrix Factorization
Jun 26, 2019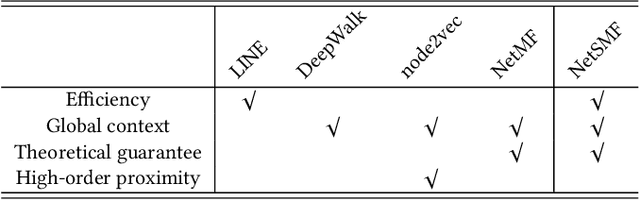
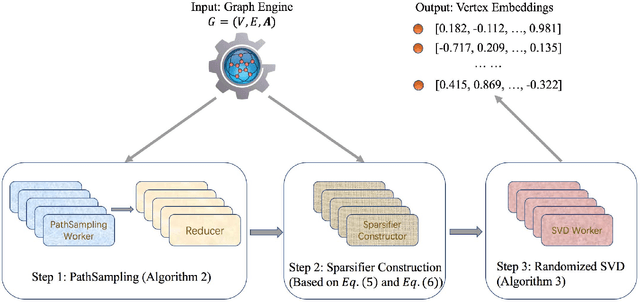
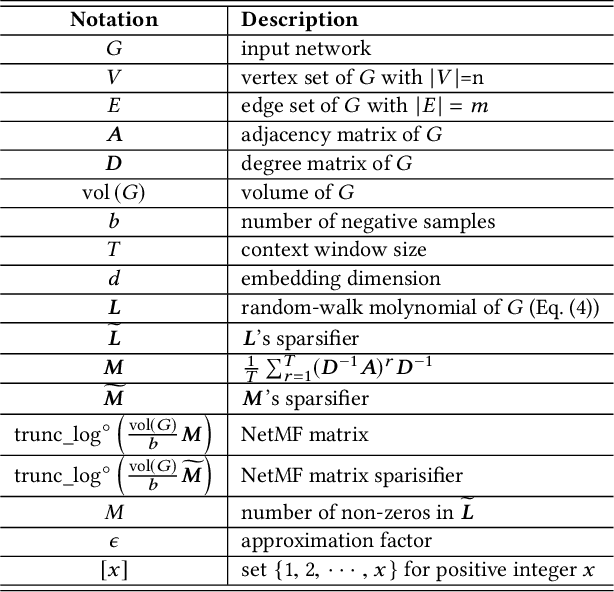
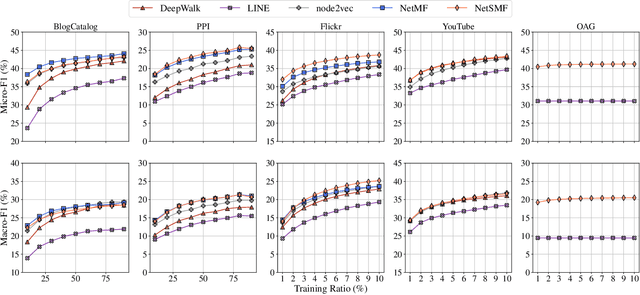
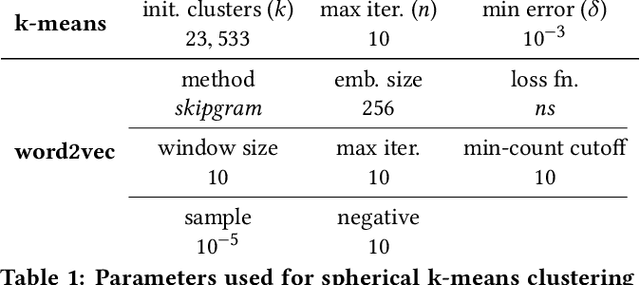
We study the problem of large-scale network embedding, which aims to learn latent representations for network mining applications. Previous research shows that 1) popular network embedding benchmarks, such as DeepWalk, are in essence implicitly factorizing a matrix with a closed form, and 2)the explicit factorization of such matrix generates more powerful embeddings than existing methods. However, directly constructing and factorizing this matrix---which is dense---is prohibitively expensive in terms of both time and space, making it not scalable for large networks. In this work, we present the algorithm of large-scale network embedding as sparse matrix factorization (NetSMF). NetSMF leverages theories from spectral sparsification to efficiently sparsify the aforementioned dense matrix, enabling significantly improved efficiency in embedding learning. The sparsified matrix is spectrally close to the original dense one with a theoretically bounded approximation error, which helps maintain the representation power of the learned embeddings. We conduct experiments on networks of various scales and types. Results show that among both popular benchmarks and factorization based methods, NetSMF is the only method that achieves both high efficiency and effectiveness. We show that NetSMF requires only 24 hours to generate effective embeddings for a large-scale academic collaboration network with tens of millions of nodes, while it would cost DeepWalk months and is computationally infeasible for the dense matrix factorization solution. The source code of NetSMF is publicly available (https://github.com/xptree/NetSMF).
A Scalable Hybrid Research Paper Recommender System for Microsoft Academic
May 21, 2019
We present the design and methodology for the large scale hybrid paper recommender system used by Microsoft Academic. The system provides recommendations for approximately 160 million English research papers and patents. Our approach handles incomplete citation information while also alleviating the cold-start problem that often affects other recommender systems. We use the Microsoft Academic Graph (MAG), titles, and available abstracts of research papers to build a recommendation list for all documents, thereby combining co-citation and content based approaches. Tuning system parameters also allows for blending and prioritization of each approach which, in turn, allows us to balance paper novelty versus authority in recommendation results. We evaluate the generated recommendations via a user study of 40 participants, with over 2400 recommendation pairs graded and discuss the quality of the results using P@10 and nDCG scores. We see that there is a strong correlation between participant scores and the similarity rankings produced by our system but that additional focus needs to be put towards improving recommender precision, particularly for content based recommendations. The results of the user survey and associated analysis scripts are made available via GitHub and the recommendations produced by our system are available as part of the MAG on Azure to facilitate further research and light up novel research paper recommendation applications.
* 7 pages, 7 figures. Short paper at The Web Conference 2019, San Francisco, USA
DeepInf: Social Influence Prediction with Deep Learning
Jul 15, 2018
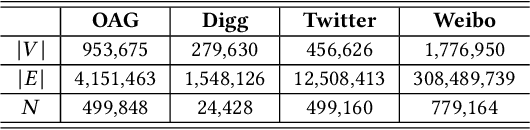


Social and information networking activities such as on Facebook, Twitter, WeChat, and Weibo have become an indispensable part of our everyday life, where we can easily access friends' behaviors and are in turn influenced by them. Consequently, an effective social influence prediction for each user is critical for a variety of applications such as online recommendation and advertising. Conventional social influence prediction approaches typically design various hand-crafted rules to extract user- and network-specific features. However, their effectiveness heavily relies on the knowledge of domain experts. As a result, it is usually difficult to generalize them into different domains. Inspired by the recent success of deep neural networks in a wide range of computing applications, we design an end-to-end framework, DeepInf, to learn users' latent feature representation for predicting social influence. In general, DeepInf takes a user's local network as the input to a graph neural network for learning her latent social representation. We design strategies to incorporate both network structures and user-specific features into convolutional neural and attention networks. Extensive experiments on Open Academic Graph, Twitter, Weibo, and Digg, representing different types of social and information networks, demonstrate that the proposed end-to-end model, DeepInf, significantly outperforms traditional feature engineering-based approaches, suggesting the effectiveness of representation learning for social applications.