 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTrialGraph: Machine Intelligence Enabled Insight from Graph Modelling of Clinical Trials
Dec 15, 2021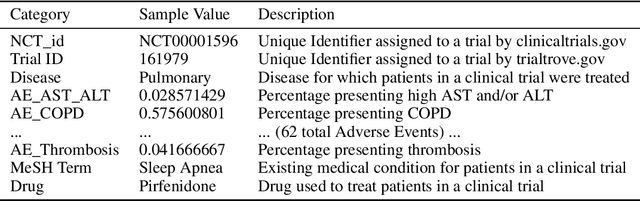
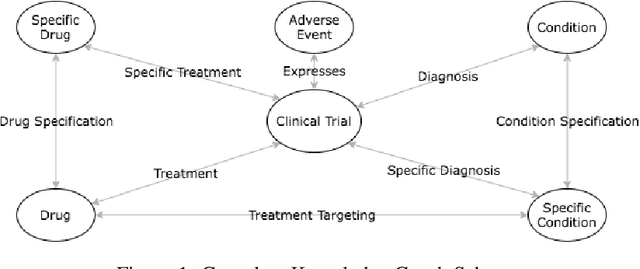
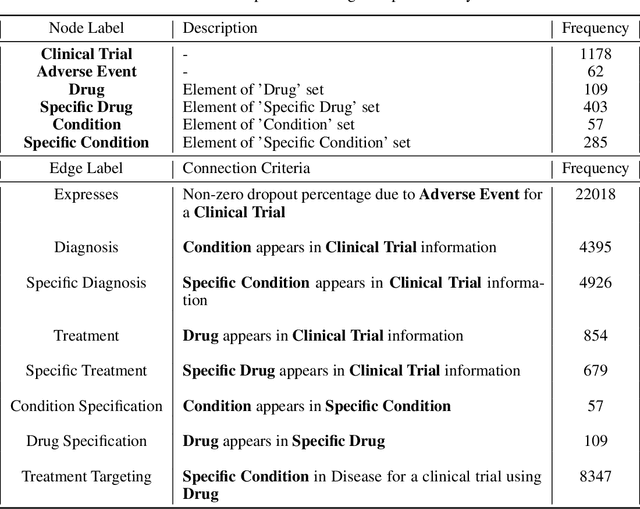

A major impediment to successful drug development is the complexity, cost, and scale of clinical trials. The detailed internal structure of clinical trial data can make conventional optimization difficult to achieve. Recent advances in machine learning, specifically graph-structured data analysis, have the potential to enable significant progress in improving the clinical trial design. TrialGraph seeks to apply these methodologies to produce a proof-of-concept framework for developing models which can aid drug development and benefit patients. In this work, we first introduce a curated clinical trial data set compiled from the CT.gov, AACT and TrialTrove databases (n=1191 trials; representing one million patients) and describe the conversion of this data to graph-structured formats. We then detail the mathematical basis and implementation of a selection of graph machine learning algorithms, which typically use standard machine classifiers on graph data embedded in a low-dimensional feature space. We trained these models to predict side effect information for a clinical trial given information on the disease, existing medical conditions, and treatment. The MetaPath2Vec algorithm performed exceptionally well, with standard Logistic Regression, Decision Tree, Random Forest, Support Vector, and Neural Network classifiers exhibiting typical ROC-AUC scores of 0.85, 0.68, 0.86, 0.80, and 0.77, respectively. Remarkably, the best performing classifiers could only produce typical ROC-AUC scores of 0.70 when trained on equivalent array-structured data. Our work demonstrates that graph modelling can significantly improve prediction accuracy on appropriate datasets. Successive versions of the project that refine modelling assumptions and incorporate more data types can produce excellent predictors with real-world applications in drug development.
A Scalable Hybrid Research Paper Recommender System for Microsoft Academic
May 21, 2019
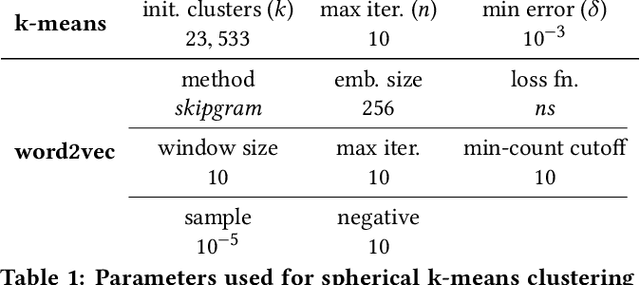
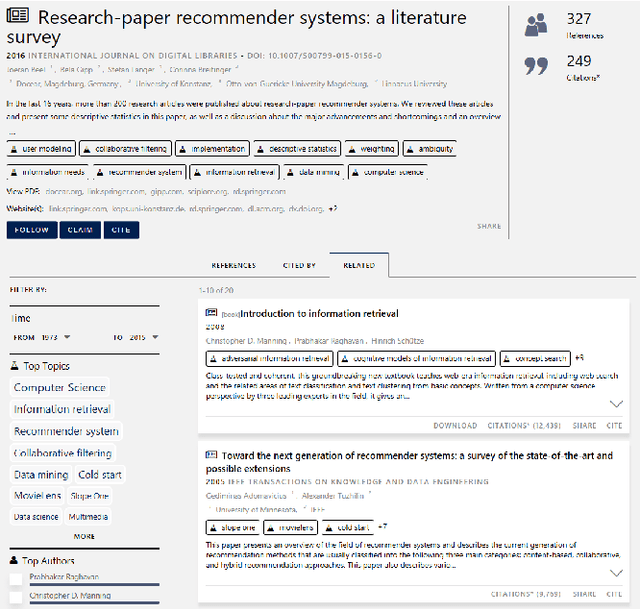
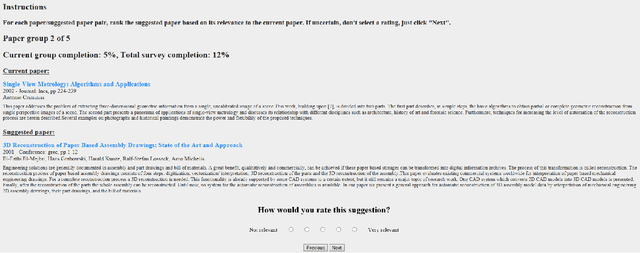
We present the design and methodology for the large scale hybrid paper recommender system used by Microsoft Academic. The system provides recommendations for approximately 160 million English research papers and patents. Our approach handles incomplete citation information while also alleviating the cold-start problem that often affects other recommender systems. We use the Microsoft Academic Graph (MAG), titles, and available abstracts of research papers to build a recommendation list for all documents, thereby combining co-citation and content based approaches. Tuning system parameters also allows for blending and prioritization of each approach which, in turn, allows us to balance paper novelty versus authority in recommendation results. We evaluate the generated recommendations via a user study of 40 participants, with over 2400 recommendation pairs graded and discuss the quality of the results using P@10 and nDCG scores. We see that there is a strong correlation between participant scores and the similarity rankings produced by our system but that additional focus needs to be put towards improving recommender precision, particularly for content based recommendations. The results of the user survey and associated analysis scripts are made available via GitHub and the recommendations produced by our system are available as part of the MAG on Azure to facilitate further research and light up novel research paper recommendation applications.
* 7 pages, 7 figures. Short paper at The Web Conference 2019, San Francisco, USA