 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOpen Grounded Planning: Challenges and Benchmark Construction
Jun 05, 2024The emergence of large language models (LLMs) has increasingly drawn attention to the use of LLMs for human-like planning. Existing work on LLM-based planning either focuses on leveraging the inherent language generation capabilities of LLMs to produce free-style plans, or employs reinforcement learning approaches to learn decision-making for a limited set of actions within restricted environments. However, both approaches exhibit significant discrepancies from the open and executable requirements in real-world planning. In this paper, we propose a new planning task--open grounded planning. The primary objective of open grounded planning is to ask the model to generate an executable plan based on a variable action set, thereby ensuring the executability of the produced plan. To this end, we establishes a benchmark for open grounded planning spanning a wide range of domains. Then we test current state-of-the-art LLMs along with five planning approaches, revealing that existing LLMs and methods still struggle to address the challenges posed by grounded planning in open domains. The outcomes of this paper define and establish a foundational dataset for open grounded planning, and shed light on the potential challenges and future directions of LLM-based planning.
MMLU-Pro: A More Robust and Challenging Multi-Task Language Understanding Benchmark
Jun 04, 2024



In the age of large-scale language models, benchmarks like the Massive Multitask Language Understanding (MMLU) have been pivotal in pushing the boundaries of what AI can achieve in language comprehension and reasoning across diverse domains. However, as models continue to improve, their performance on these benchmarks has begun to plateau, making it increasingly difficult to discern differences in model capabilities. This paper introduces MMLU-Pro, an enhanced dataset designed to extend the mostly knowledge-driven MMLU benchmark by integrating more challenging, reasoning-focused questions and expanding the choice set from four to ten options. Additionally, MMLU-Pro eliminates the trivial and noisy questions in MMLU. Our experimental results show that MMLU-Pro not only raises the challenge, causing a significant drop in accuracy by 16% to 33% compared to MMLU but also demonstrates greater stability under varying prompts. With 24 different prompt styles tested, the sensitivity of model scores to prompt variations decreased from 4-5% in MMLU to just 2% in MMLU-Pro. Additionally, we found that models utilizing Chain of Thought (CoT) reasoning achieved better performance on MMLU-Pro compared to direct answering, which is in stark contrast to the findings on the original MMLU, indicating that MMLU-Pro includes more complex reasoning questions. Our assessments confirm that MMLU-Pro is a more discriminative benchmark to better track progress in the field.
AI for social science and social science of AI: A Survey
Jan 22, 2024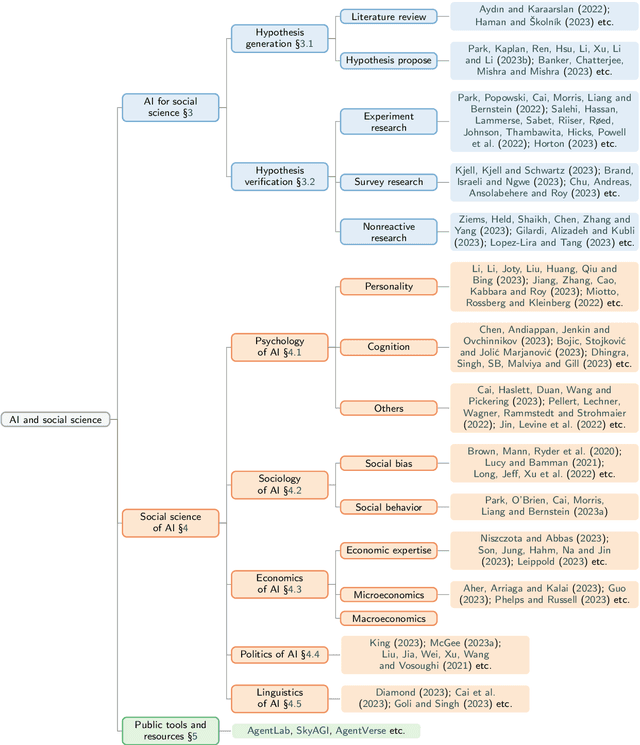
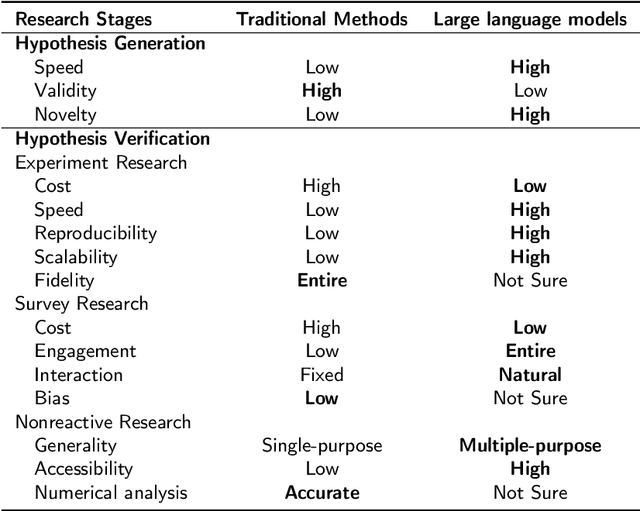
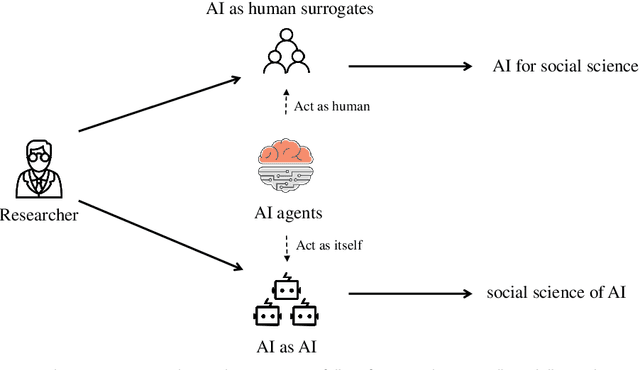
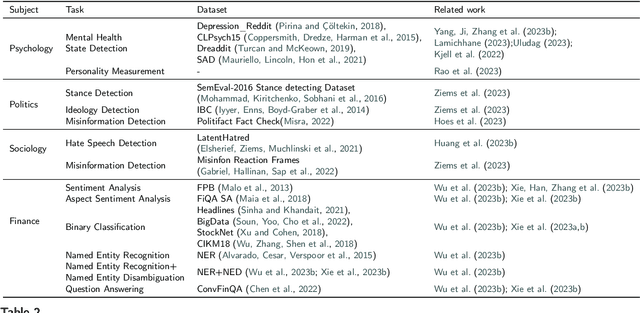
Recent advancements in artificial intelligence, particularly with the emergence of large language models (LLMs), have sparked a rethinking of artificial general intelligence possibilities. The increasing human-like capabilities of AI are also attracting attention in social science research, leading to various studies exploring the combination of these two fields. In this survey, we systematically categorize previous explorations in the combination of AI and social science into two directions that share common technical approaches but differ in their research objectives. The first direction is focused on AI for social science, where AI is utilized as a powerful tool to enhance various stages of social science research. While the second direction is the social science of AI, which examines AI agents as social entities with their human-like cognitive and linguistic capabilities. By conducting a thorough review, particularly on the substantial progress facilitated by recent advancements in large language models, this paper introduces a fresh perspective to reassess the relationship between AI and social science, provides a cohesive framework that allows researchers to understand the distinctions and connections between AI for social science and social science of AI, and also summarized state-of-art experiment simulation platforms to facilitate research in these two directions. We believe that as AI technology continues to advance and intelligent agents find increasing applications in our daily lives, the significance of the combination of AI and social science will become even more prominent.
CogDL: An Extensive Toolkit for Deep Learning on Graphs
Mar 01, 2021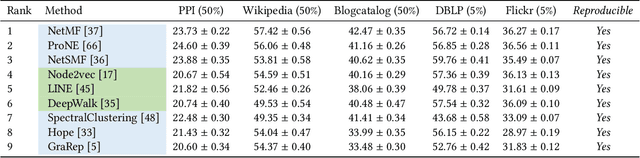
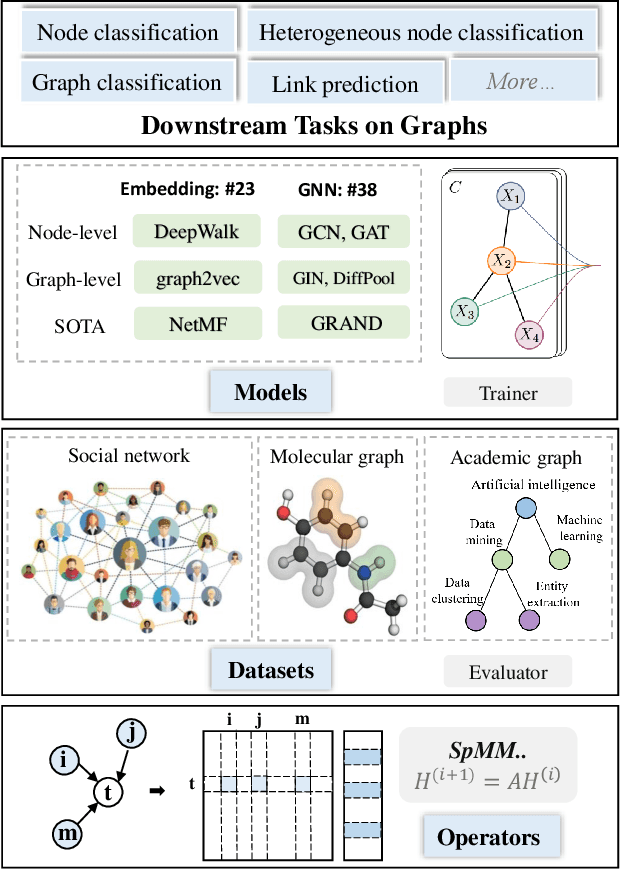
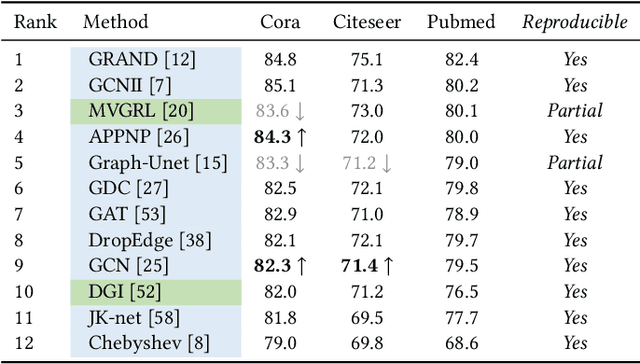
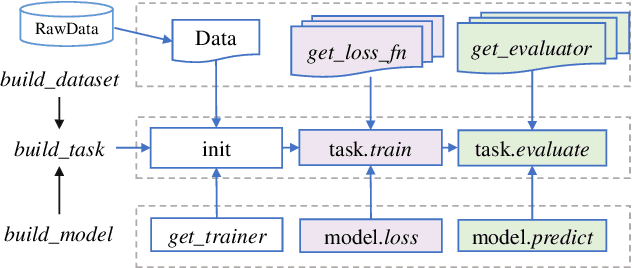
Graph representation learning aims to learn low-dimensional node embeddings for graphs. It is used in several real-world applications such as social network analysis and large-scale recommender systems. In this paper, we introduce CogDL, an extensive research toolkit for deep learning on graphs that allows researchers and developers to easily conduct experiments and build applications. It provides standard training and evaluation for the most important tasks in the graph domain, including node classification, link prediction, graph classification, and other graph tasks. For each task, it offers implementations of state-of-the-art models. The models in our toolkit are divided into two major parts, graph embedding methods and graph neural networks. Most of the graph embedding methods learn node-level or graph-level representations in an unsupervised way and preserves the graph properties such as structural information, while graph neural networks capture node features and work in semi-supervised or self-supervised settings. All models implemented in our toolkit can be easily reproducible for leaderboard results. Most models in CogDL are developed on top of PyTorch, and users can leverage the advantages of PyTorch to implement their own models. Furthermore, we demonstrate the effectiveness of CogDL for real-world applications in AMiner, which is a large academic database and system.