 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInterleaved Reasoning for Large Language Models via Reinforcement Learning
May 26, 2025Long chain-of-thought (CoT) significantly enhances large language models' (LLM) reasoning capabilities. However, the extensive reasoning traces lead to inefficiencies and an increased time-to-first-token (TTFT). We propose a novel training paradigm that uses reinforcement learning (RL) to guide reasoning LLMs to interleave thinking and answering for multi-hop questions. We observe that models inherently possess the ability to perform interleaved reasoning, which can be further enhanced through RL. We introduce a simple yet effective rule-based reward to incentivize correct intermediate steps, which guides the policy model toward correct reasoning paths by leveraging intermediate signals generated during interleaved reasoning. Extensive experiments conducted across five diverse datasets and three RL algorithms (PPO, GRPO, and REINFORCE++) demonstrate consistent improvements over traditional think-answer reasoning, without requiring external tools. Specifically, our approach reduces TTFT by over 80% on average and improves up to 19.3% in Pass@1 accuracy. Furthermore, our method, trained solely on question answering and logical reasoning datasets, exhibits strong generalization ability to complex reasoning datasets such as MATH, GPQA, and MMLU. Additionally, we conduct in-depth analysis to reveal several valuable insights into conditional reward modeling.
Apple Intelligence Foundation Language Models
Jul 29, 2024



We present foundation language models developed to power Apple Intelligence features, including a ~3 billion parameter model designed to run efficiently on devices and a large server-based language model designed for Private Cloud Compute. These models are designed to perform a wide range of tasks efficiently, accurately, and responsibly. This report describes the model architecture, the data used to train the model, the training process, how the models are optimized for inference, and the evaluation results. We highlight our focus on Responsible AI and how the principles are applied throughout the model development.
USM-Lite: Quantization and Sparsity Aware Fine-tuning for Speech Recognition with Universal Speech Models
Jan 03, 2024End-to-end automatic speech recognition (ASR) models have seen revolutionary quality gains with the recent development of large-scale universal speech models (USM). However, deploying these massive USMs is extremely expensive due to the enormous memory usage and computational cost. Therefore, model compression is an important research topic to fit USM-based ASR under budget in real-world scenarios. In this study, we propose a USM fine-tuning approach for ASR, with a low-bit quantization and N:M structured sparsity aware paradigm on the model weights, reducing the model complexity from parameter precision and matrix topology perspectives. We conducted extensive experiments with a 2-billion parameter USM on a large-scale voice search dataset to evaluate our proposed method. A series of ablation studies validate the effectiveness of up to int4 quantization and 2:4 sparsity. However, a single compression technique fails to recover the performance well under extreme setups including int2 quantization and 1:4 sparsity. By contrast, our proposed method can compress the model to have 9.4% of the size, at the cost of only 7.3% relative word error rate (WER) regressions. We also provided in-depth analyses on the results and discussions on the limitations and potential solutions, which would be valuable for future studies.
Partial Rewriting for Multi-Stage ASR
Dec 08, 2023For many streaming automatic speech recognition tasks, it is important to provide timely intermediate streaming results, while refining a high quality final result. This can be done using a multi-stage architecture, where a small left-context only model creates streaming results and a larger left- and right-context model produces a final result at the end. While this significantly improves the quality of the final results without compromising the streaming emission latency of the system, streaming results do not benefit from the quality improvements. Here, we propose using a text manipulation algorithm that merges the streaming outputs of both models. We improve the quality of streaming results by around 10%, without altering the final results. Our approach introduces no additional latency and reduces flickering. It is also lightweight, does not require retraining the model, and it can be applied to a wide variety of multi-stage architectures.
2-bit Conformer quantization for automatic speech recognition
May 26, 2023Large speech models are rapidly gaining traction in research community. As a result, model compression has become an important topic, so that these models can fit in memory and be served with reduced cost. Practical approaches for compressing automatic speech recognition (ASR) model use int8 or int4 weight quantization. In this study, we propose to develop 2-bit ASR models. We explore the impact of symmetric and asymmetric quantization combined with sub-channel quantization and clipping on both LibriSpeech dataset and large-scale training data. We obtain a lossless 2-bit Conformer model with 32% model size reduction when compared to state of the art 4-bit Conformer model for LibriSpeech. With the large-scale training data, we obtain a 2-bit Conformer model with over 40% model size reduction against the 4-bit version at the cost of 17% relative word error rate degradation
RAND: Robustness Aware Norm Decay For Quantized Seq2seq Models
May 24, 2023



With the rapid increase in the size of neural networks, model compression has become an important area of research. Quantization is an effective technique at decreasing the model size, memory access, and compute load of large models. Despite recent advances in quantization aware training (QAT) technique, most papers present evaluations that are focused on computer vision tasks, which have different training dynamics compared to sequence tasks. In this paper, we first benchmark the impact of popular techniques such as straight through estimator, pseudo-quantization noise, learnable scale parameter, clipping, etc. on 4-bit seq2seq models across a suite of speech recognition datasets ranging from 1,000 hours to 1 million hours, as well as one machine translation dataset to illustrate its applicability outside of speech. Through the experiments, we report that noise based QAT suffers when there is insufficient regularization signal flowing back to the quantization scale. We propose low complexity changes to the QAT process to improve model accuracy (outperforming popular learnable scale and clipping methods). With the improved accuracy, it opens up the possibility to exploit some of the other benefits of noise based QAT: 1) training a single model that performs well in mixed precision mode and 2) improved generalization on long form speech recognition.
Large-scale ASR Domain Adaptation using Self- and Semi-supervised Learning
Oct 13, 2021

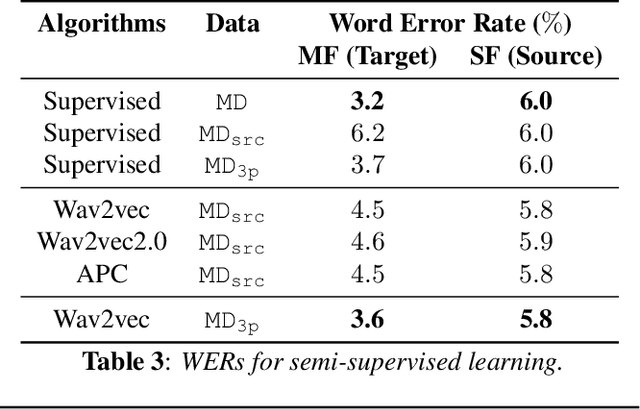
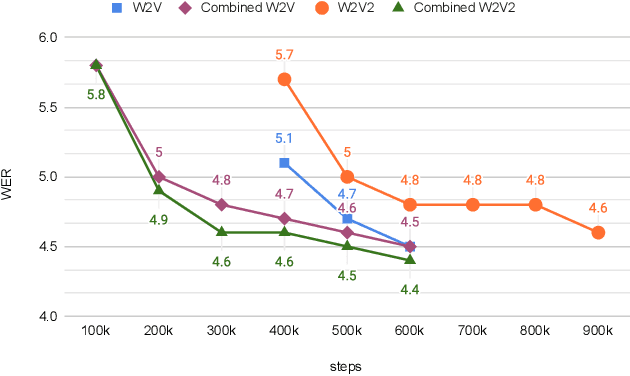
Self- and semi-supervised learning methods have been actively investigated to reduce labeled training data or enhance the model performance. However, the approach mostly focus on in-domain performance for public datasets. In this study, we utilize the combination of self- and semi-supervised learning methods to solve unseen domain adaptation problem in a large-scale production setting for online ASR model. This approach demonstrates that using the source domain data with a small fraction of the target domain data (3%) can recover the performance gap compared to a full data baseline: relative 13.5% WER improvement for target domain data.
Improving Confidence Estimation on Out-of-Domain Data for End-to-End Speech Recognition
Oct 07, 2021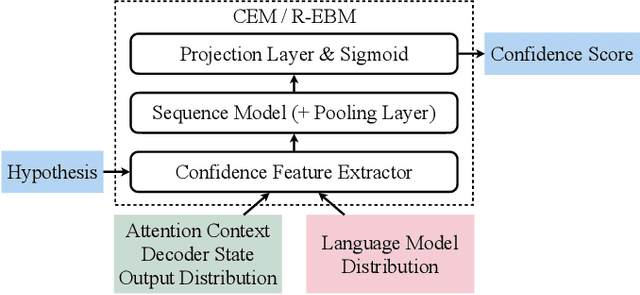
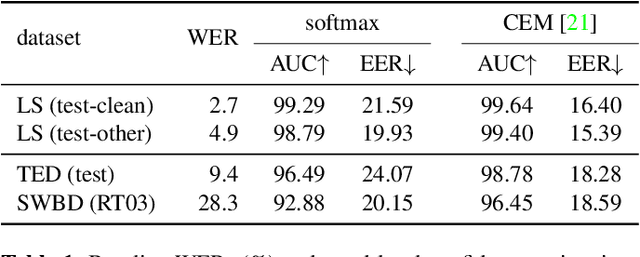
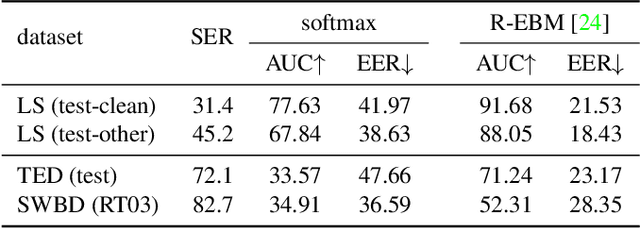
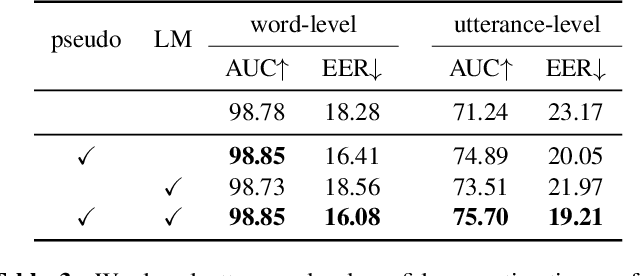
As end-to-end automatic speech recognition (ASR) models reach promising performance, various downstream tasks rely on good confidence estimators for these systems. Recent research has shown that model-based confidence estimators have a significant advantage over using the output softmax probabilities. If the input data to the speech recogniser is from mismatched acoustic and linguistic conditions, the ASR performance and the corresponding confidence estimators may exhibit severe degradation. Since confidence models are often trained on the same in-domain data as the ASR, generalising to out-of-domain (OOD) scenarios is challenging. By keeping the ASR model untouched, this paper proposes two approaches to improve the model-based confidence estimators on OOD data: using pseudo transcriptions and an additional OOD language model. With an ASR model trained on LibriSpeech, experiments show that the proposed methods can significantly improve the confidence metrics on TED-LIUM and Switchboard datasets while preserving in-domain performance. Furthermore, the improved confidence estimators are better calibrated on OOD data and can provide a much more reliable criterion for data selection.
Multi-Task Learning for End-to-End ASR Word and Utterance Confidence with Deletion Prediction
Apr 26, 2021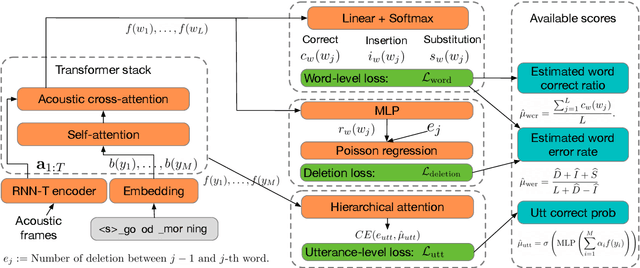
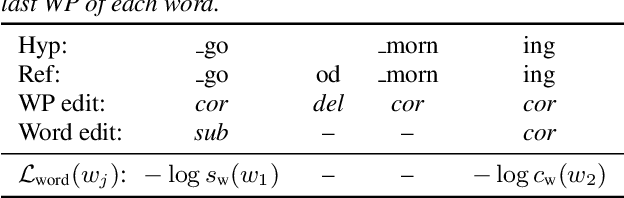
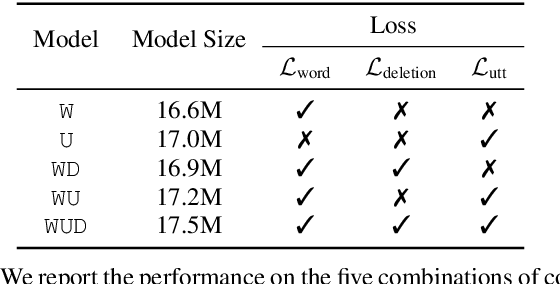
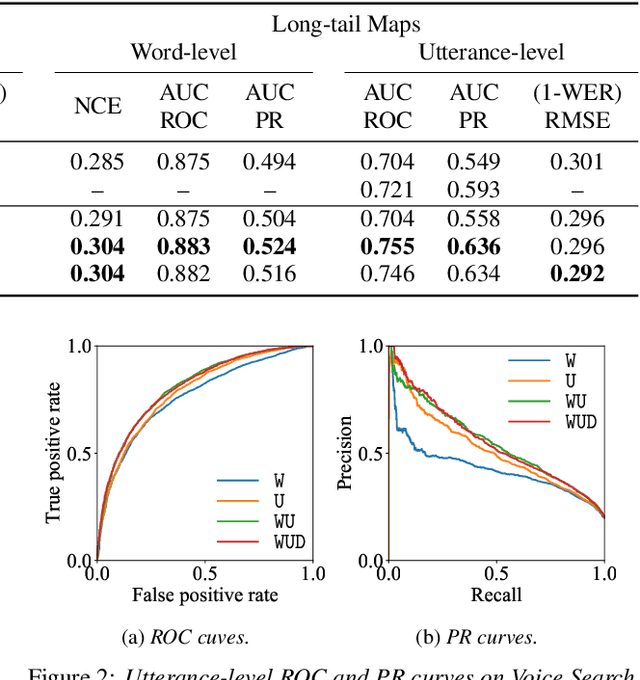
Confidence scores are very useful for downstream applications of automatic speech recognition (ASR) systems. Recent works have proposed using neural networks to learn word or utterance confidence scores for end-to-end ASR. In those studies, word confidence by itself does not model deletions, and utterance confidence does not take advantage of word-level training signals. This paper proposes to jointly learn word confidence, word deletion, and utterance confidence. Empirical results show that multi-task learning with all three objectives improves confidence metrics (NCE, AUC, RMSE) without the need for increasing the model size of the confidence estimation module. Using the utterance-level confidence for rescoring also decreases the word error rates on Google's Voice Search and Long-tail Maps datasets by 3-5% relative, without needing a dedicated neural rescorer.
Learning Word-Level Confidence For Subword End-to-End ASR
Mar 11, 2021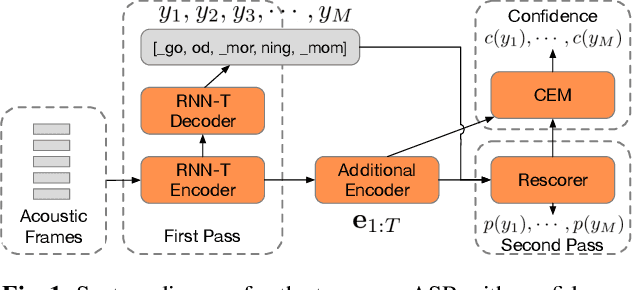

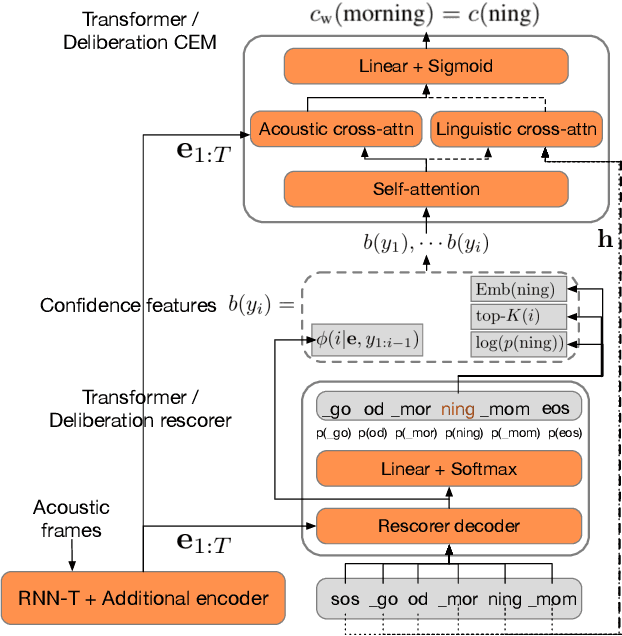
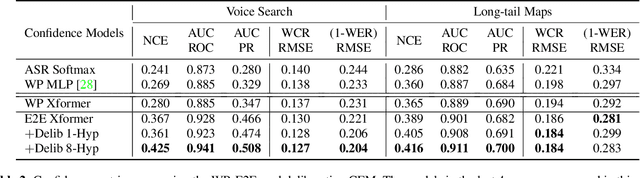
We study the problem of word-level confidence estimation in subword-based end-to-end (E2E) models for automatic speech recognition (ASR). Although prior works have proposed training auxiliary confidence models for ASR systems, they do not extend naturally to systems that operate on word-pieces (WP) as their vocabulary. In particular, ground truth WP correctness labels are needed for training confidence models, but the non-unique tokenization from word to WP causes inaccurate labels to be generated. This paper proposes and studies two confidence models of increasing complexity to solve this problem. The final model uses self-attention to directly learn word-level confidence without needing subword tokenization, and exploits full context features from multiple hypotheses to improve confidence accuracy. Experiments on Voice Search and long-tail test sets show standard metrics (e.g., NCE, AUC, RMSE) improving substantially. The proposed confidence module also enables a model selection approach to combine an on-device E2E model with a hybrid model on the server to address the rare word recognition problem for the E2E model.