 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSLM: Bridge the thin gap between speech and text foundation models
Sep 30, 2023



We present a joint Speech and Language Model (SLM), a multitask, multilingual, and dual-modal model that takes advantage of pretrained foundational speech and language models. SLM freezes the pretrained foundation models to maximally preserves their capabilities, and only trains a simple adapter with just 1\% (156M) of the foundation models' parameters. This adaptation not only leads SLM to achieve strong performance on conventional tasks such as speech recognition (ASR) and speech translation (AST), but also introduces the novel capability of zero-shot instruction-following for more diverse tasks: given a speech input and a text instruction, SLM is able to perform unseen generation tasks including contextual biasing ASR using real-time context, dialog generation, speech continuation, and question answering, etc. Our approach demonstrates that the representational gap between pretrained speech and language models might be narrower than one would expect, and can be bridged by a simple adaptation mechanism. As a result, SLM is not only efficient to train, but also inherits strong capabilities already acquired in foundation models of different modalities.
Joint Unsupervised and Supervised Training for Multilingual ASR
Nov 15, 2021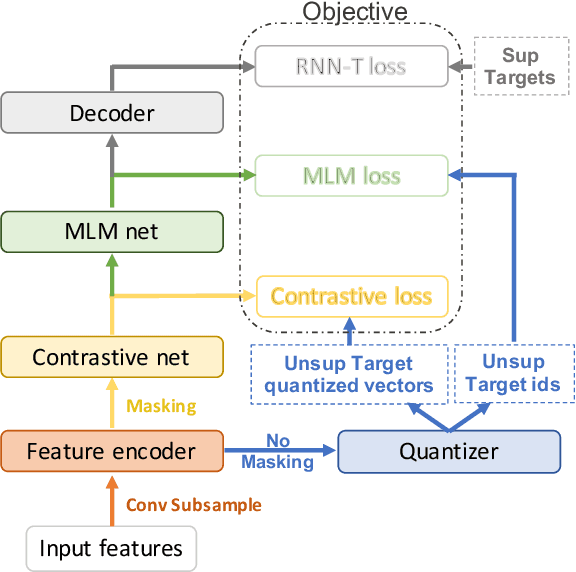
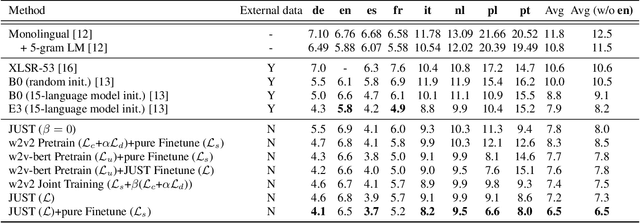
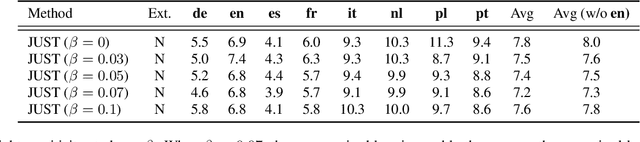
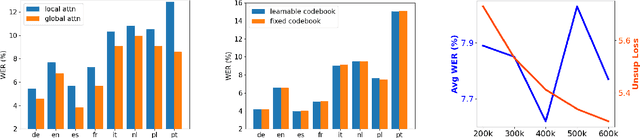
Self-supervised training has shown promising gains in pretraining models and facilitating the downstream finetuning for speech recognition, like multilingual ASR. Most existing methods adopt a 2-stage scheme where the self-supervised loss is optimized in the first pretraining stage, and the standard supervised finetuning resumes in the second stage. In this paper, we propose an end-to-end (E2E) Joint Unsupervised and Supervised Training (JUST) method to combine the supervised RNN-T loss and the self-supervised contrastive and masked language modeling (MLM) losses. We validate its performance on the public dataset Multilingual LibriSpeech (MLS), which includes 8 languages and is extremely imbalanced. On MLS, we explore (1) JUST trained from scratch, and (2) JUST finetuned from a pretrained checkpoint. Experiments show that JUST can consistently outperform other existing state-of-the-art methods, and beat the monolingual baseline by a significant margin, demonstrating JUST's capability of handling low-resource languages in multilingual ASR. Our average WER of all languages outperforms average monolingual baseline by 33.3%, and the state-of-the-art 2-stage XLSR by 32%. On low-resource languages like Polish, our WER is less than half of the monolingual baseline and even beats the supervised transfer learning method which uses external supervision.
Large-scale ASR Domain Adaptation using Self- and Semi-supervised Learning
Oct 13, 2021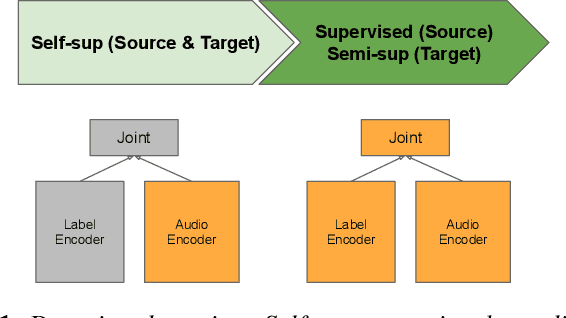

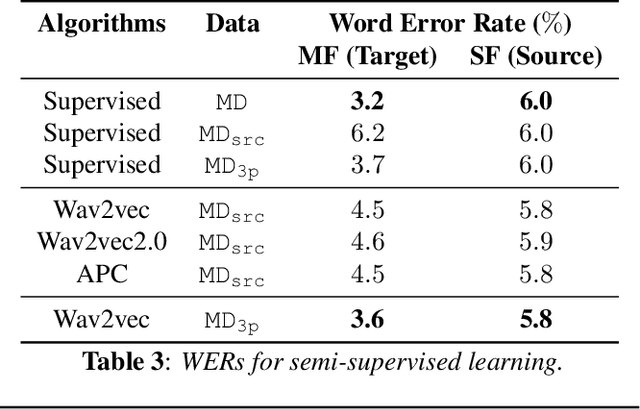
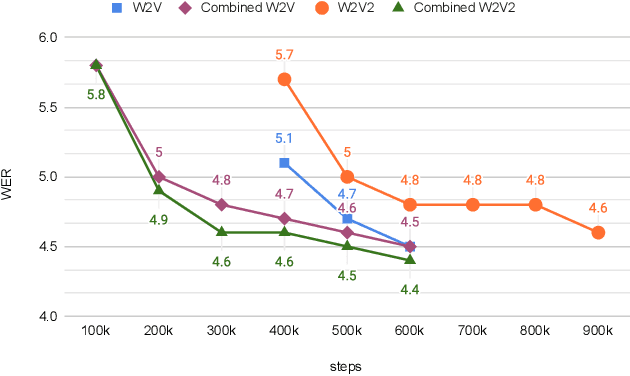
Self- and semi-supervised learning methods have been actively investigated to reduce labeled training data or enhance the model performance. However, the approach mostly focus on in-domain performance for public datasets. In this study, we utilize the combination of self- and semi-supervised learning methods to solve unseen domain adaptation problem in a large-scale production setting for online ASR model. This approach demonstrates that using the source domain data with a small fraction of the target domain data (3%) can recover the performance gap compared to a full data baseline: relative 13.5% WER improvement for target domain data.
Incremental Layer-wise Self-Supervised Learning for Efficient Speech Domain Adaptation On Device
Oct 01, 2021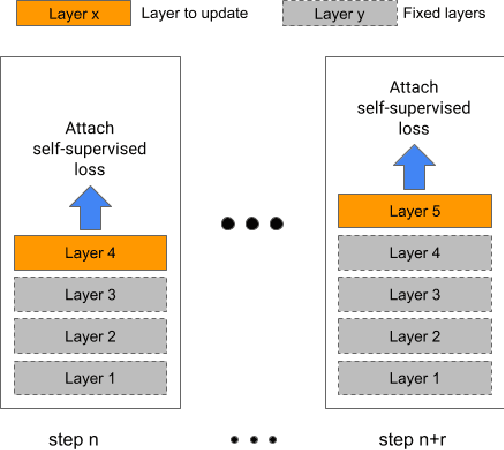
Streaming end-to-end speech recognition models have been widely applied to mobile devices and show significant improvement in efficiency. These models are typically trained on the server using transcribed speech data. However, the server data distribution can be very different from the data distribution on user devices, which could affect the model performance. There are two main challenges for on device training, limited reliable labels and limited training memory. While self-supervised learning algorithms can mitigate the mismatch between domains using unlabeled data, they are not applicable on mobile devices directly because of the memory constraint. In this paper, we propose an incremental layer-wise self-supervised learning algorithm for efficient speech domain adaptation on mobile devices, in which only one layer is updated at a time. Extensive experimental results demonstrate that the proposed algorithm obtains a Word Error Rate (WER) on the target domain $24.2\%$ better than supervised baseline and costs $89.7\%$ less training memory than the end-to-end self-supervised learning algorithm.