 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLarge-scale ASR Domain Adaptation using Self- and Semi-supervised Learning
Oct 13, 2021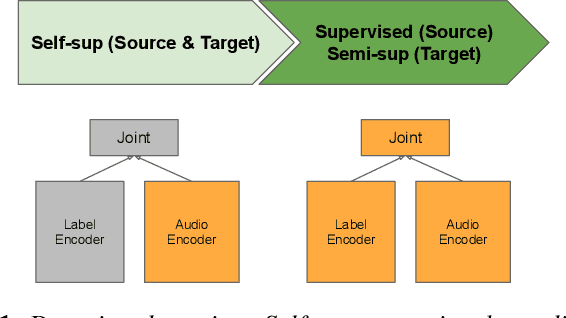

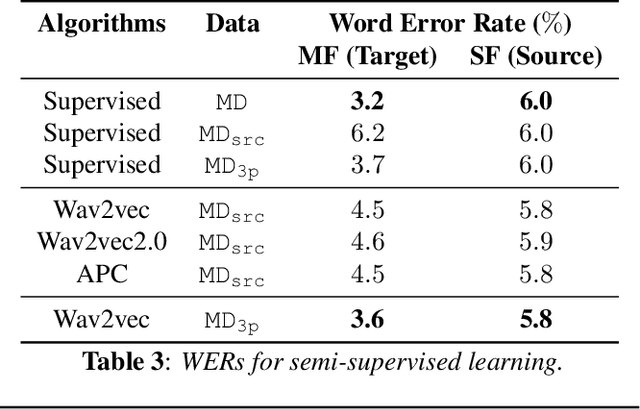
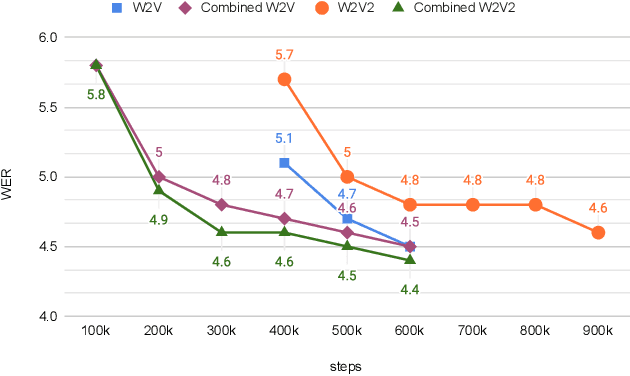
Self- and semi-supervised learning methods have been actively investigated to reduce labeled training data or enhance the model performance. However, the approach mostly focus on in-domain performance for public datasets. In this study, we utilize the combination of self- and semi-supervised learning methods to solve unseen domain adaptation problem in a large-scale production setting for online ASR model. This approach demonstrates that using the source domain data with a small fraction of the target domain data (3%) can recover the performance gap compared to a full data baseline: relative 13.5% WER improvement for target domain data.
Incremental Layer-wise Self-Supervised Learning for Efficient Speech Domain Adaptation On Device
Oct 01, 2021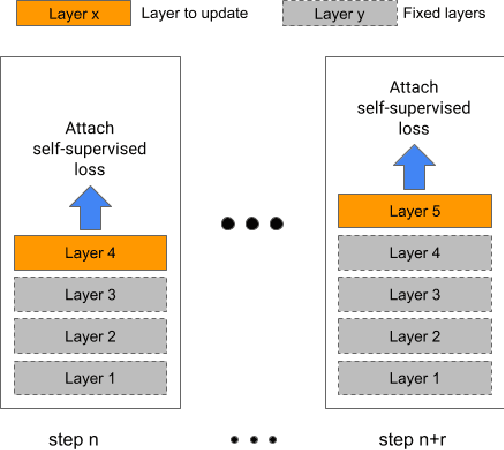
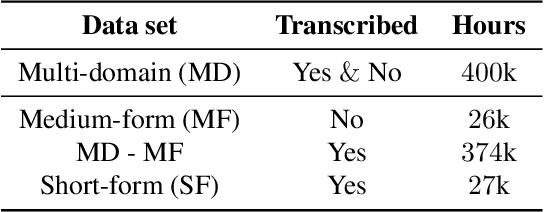
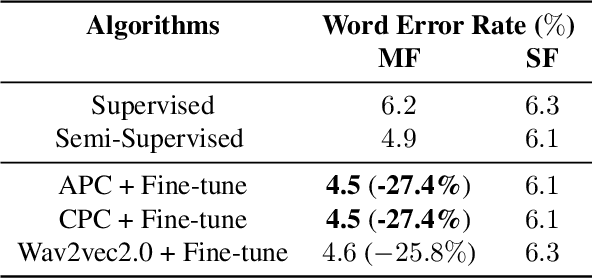
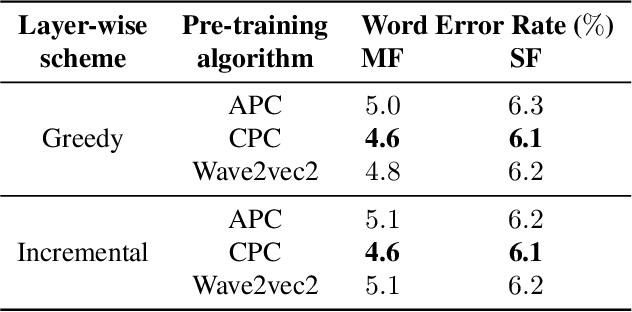
Streaming end-to-end speech recognition models have been widely applied to mobile devices and show significant improvement in efficiency. These models are typically trained on the server using transcribed speech data. However, the server data distribution can be very different from the data distribution on user devices, which could affect the model performance. There are two main challenges for on device training, limited reliable labels and limited training memory. While self-supervised learning algorithms can mitigate the mismatch between domains using unlabeled data, they are not applicable on mobile devices directly because of the memory constraint. In this paper, we propose an incremental layer-wise self-supervised learning algorithm for efficient speech domain adaptation on mobile devices, in which only one layer is updated at a time. Extensive experimental results demonstrate that the proposed algorithm obtains a Word Error Rate (WER) on the target domain $24.2\%$ better than supervised baseline and costs $89.7\%$ less training memory than the end-to-end self-supervised learning algorithm.
Improving Streaming Automatic Speech Recognition With Non-Streaming Model Distillation On Unsupervised Data
Oct 22, 2020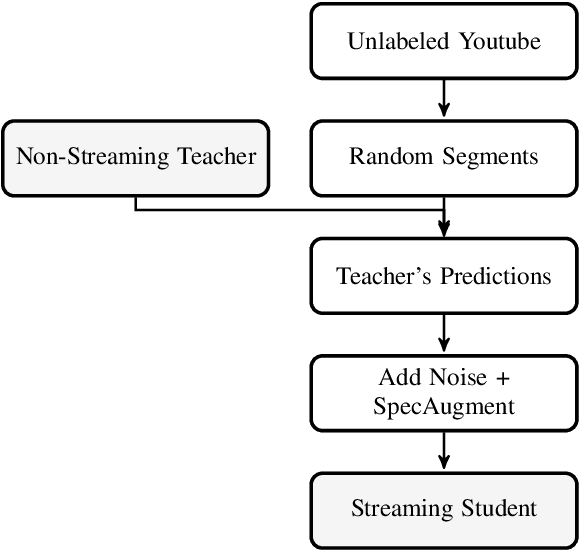
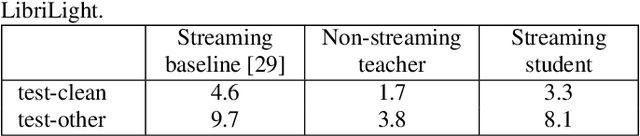
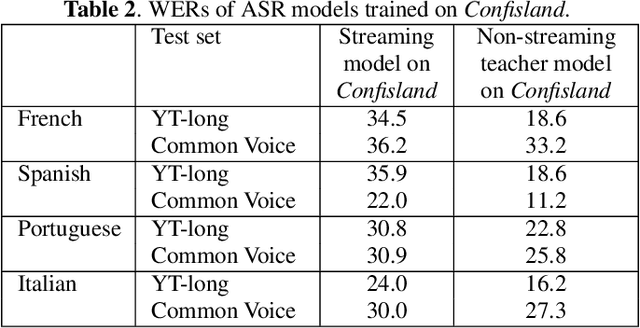
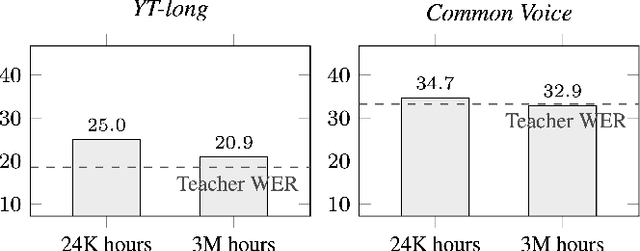
Streaming end-to-end automatic speech recognition (ASR) models are widely used on smart speakers and on-device applications. Since these models are expected to transcribe speech with minimal latency, they are constrained to be causal with no future context, compared to their non-streaming counterparts. Consequently, streaming models usually perform worse than non-streaming models. We propose a novel and effective learning method by leveraging a non-streaming ASR model as a teacher to generate transcripts on an arbitrarily large data set, which is then used to distill knowledge into streaming ASR models. This way, we scale the training of streaming models to up to 3 million hours of YouTube audio. Experiments show that our approach can significantly reduce the word error rate (WER) of RNNT models not only on LibriSpeech but also on YouTube data in four languages. For example, in French, we are able to reduce the WER by 16.4% relatively to a baseline streaming model by leveraging a non-streaming teacher model trained on the same amount of labeled data as the baseline.
Toward domain-invariant speech recognition via large scale training
Aug 16, 2018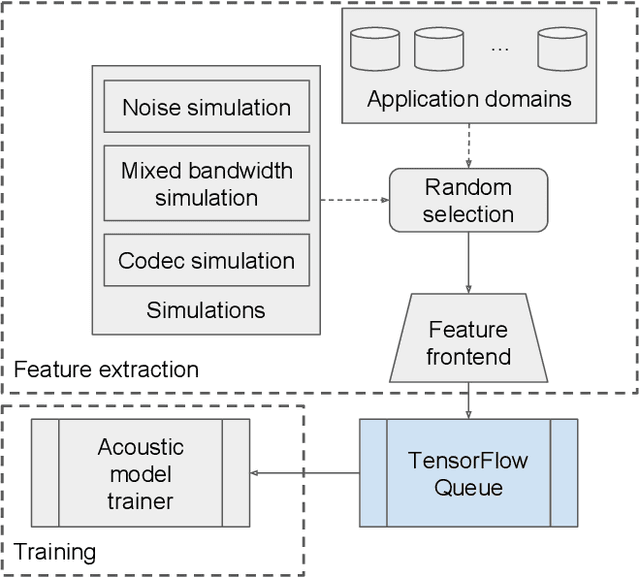
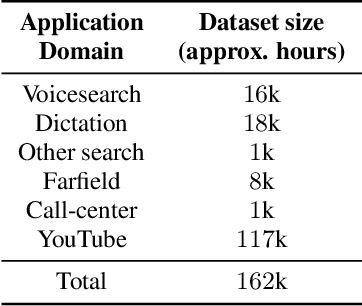
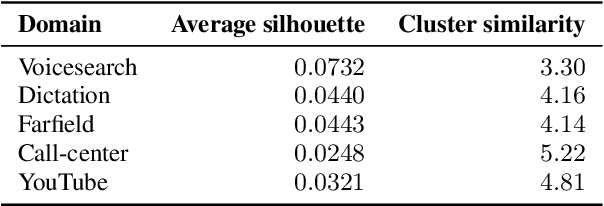
Current state-of-the-art automatic speech recognition systems are trained to work in specific `domains', defined based on factors like application, sampling rate and codec. When such recognizers are used in conditions that do not match the training domain, performance significantly drops. This work explores the idea of building a single domain-invariant model for varied use-cases by combining large scale training data from multiple application domains. Our final system is trained using 162,000 hours of speech. Additionally, each utterance is artificially distorted during training to simulate effects like background noise, codec distortion, and sampling rates. Our results show that, even at such a scale, a model thus trained works almost as well as those fine-tuned to specific subsets: A single model can be robust to multiple application domains, and variations like codecs and noise. More importantly, such models generalize better to unseen conditions and allow for rapid adaptation -- we show that by using as little as 10 hours of data from a new domain, an adapted domain-invariant model can match performance of a domain-specific model trained from scratch using 70 times as much data. We also highlight some of the limitations of such models and areas that need addressing in future work.