 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeToward domain-invariant speech recognition via large scale training
Aug 16, 2018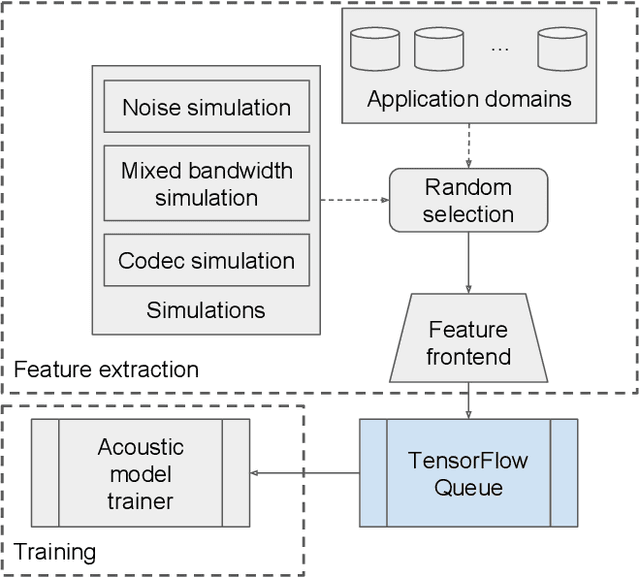
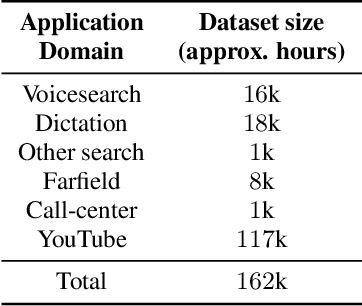
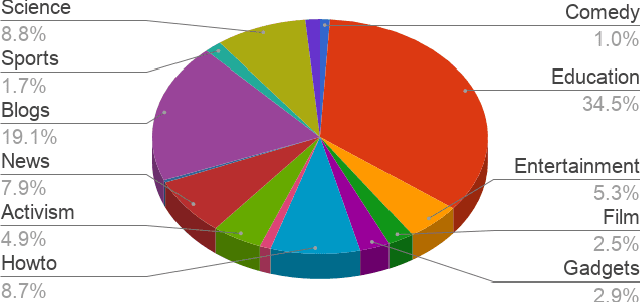
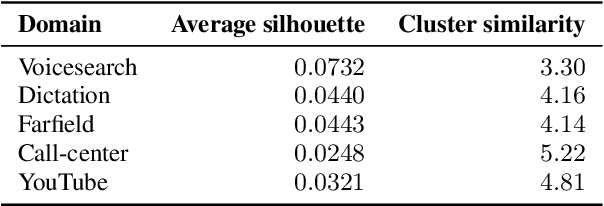
Current state-of-the-art automatic speech recognition systems are trained to work in specific `domains', defined based on factors like application, sampling rate and codec. When such recognizers are used in conditions that do not match the training domain, performance significantly drops. This work explores the idea of building a single domain-invariant model for varied use-cases by combining large scale training data from multiple application domains. Our final system is trained using 162,000 hours of speech. Additionally, each utterance is artificially distorted during training to simulate effects like background noise, codec distortion, and sampling rates. Our results show that, even at such a scale, a model thus trained works almost as well as those fine-tuned to specific subsets: A single model can be robust to multiple application domains, and variations like codecs and noise. More importantly, such models generalize better to unseen conditions and allow for rapid adaptation -- we show that by using as little as 10 hours of data from a new domain, an adapted domain-invariant model can match performance of a domain-specific model trained from scratch using 70 times as much data. We also highlight some of the limitations of such models and areas that need addressing in future work.