 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUSM-Lite: Quantization and Sparsity Aware Fine-tuning for Speech Recognition with Universal Speech Models
Jan 03, 2024End-to-end automatic speech recognition (ASR) models have seen revolutionary quality gains with the recent development of large-scale universal speech models (USM). However, deploying these massive USMs is extremely expensive due to the enormous memory usage and computational cost. Therefore, model compression is an important research topic to fit USM-based ASR under budget in real-world scenarios. In this study, we propose a USM fine-tuning approach for ASR, with a low-bit quantization and N:M structured sparsity aware paradigm on the model weights, reducing the model complexity from parameter precision and matrix topology perspectives. We conducted extensive experiments with a 2-billion parameter USM on a large-scale voice search dataset to evaluate our proposed method. A series of ablation studies validate the effectiveness of up to int4 quantization and 2:4 sparsity. However, a single compression technique fails to recover the performance well under extreme setups including int2 quantization and 1:4 sparsity. By contrast, our proposed method can compress the model to have 9.4% of the size, at the cost of only 7.3% relative word error rate (WER) regressions. We also provided in-depth analyses on the results and discussions on the limitations and potential solutions, which would be valuable for future studies.
2-bit Conformer quantization for automatic speech recognition
May 26, 2023

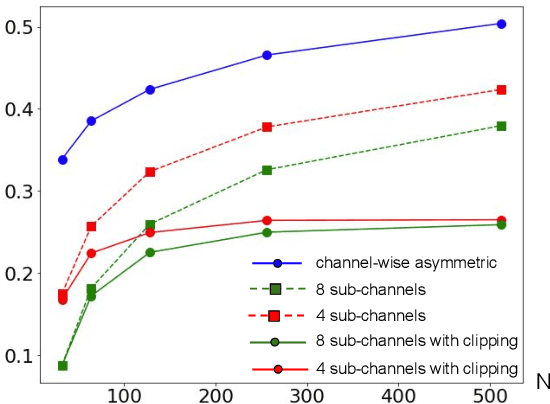

Large speech models are rapidly gaining traction in research community. As a result, model compression has become an important topic, so that these models can fit in memory and be served with reduced cost. Practical approaches for compressing automatic speech recognition (ASR) model use int8 or int4 weight quantization. In this study, we propose to develop 2-bit ASR models. We explore the impact of symmetric and asymmetric quantization combined with sub-channel quantization and clipping on both LibriSpeech dataset and large-scale training data. We obtain a lossless 2-bit Conformer model with 32% model size reduction when compared to state of the art 4-bit Conformer model for LibriSpeech. With the large-scale training data, we obtain a 2-bit Conformer model with over 40% model size reduction against the 4-bit version at the cost of 17% relative word error rate degradation
RAND: Robustness Aware Norm Decay For Quantized Seq2seq Models
May 24, 2023



With the rapid increase in the size of neural networks, model compression has become an important area of research. Quantization is an effective technique at decreasing the model size, memory access, and compute load of large models. Despite recent advances in quantization aware training (QAT) technique, most papers present evaluations that are focused on computer vision tasks, which have different training dynamics compared to sequence tasks. In this paper, we first benchmark the impact of popular techniques such as straight through estimator, pseudo-quantization noise, learnable scale parameter, clipping, etc. on 4-bit seq2seq models across a suite of speech recognition datasets ranging from 1,000 hours to 1 million hours, as well as one machine translation dataset to illustrate its applicability outside of speech. Through the experiments, we report that noise based QAT suffers when there is insufficient regularization signal flowing back to the quantization scale. We propose low complexity changes to the QAT process to improve model accuracy (outperforming popular learnable scale and clipping methods). With the improved accuracy, it opens up the possibility to exploit some of the other benefits of noise based QAT: 1) training a single model that performs well in mixed precision mode and 2) improved generalization on long form speech recognition.
Improving Facial Analysis and Performance Driven Animation through Disentangling Identity and Expression
May 22, 2016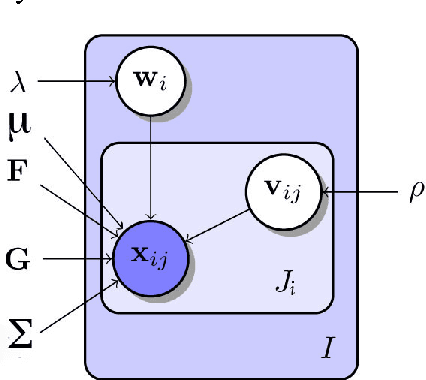
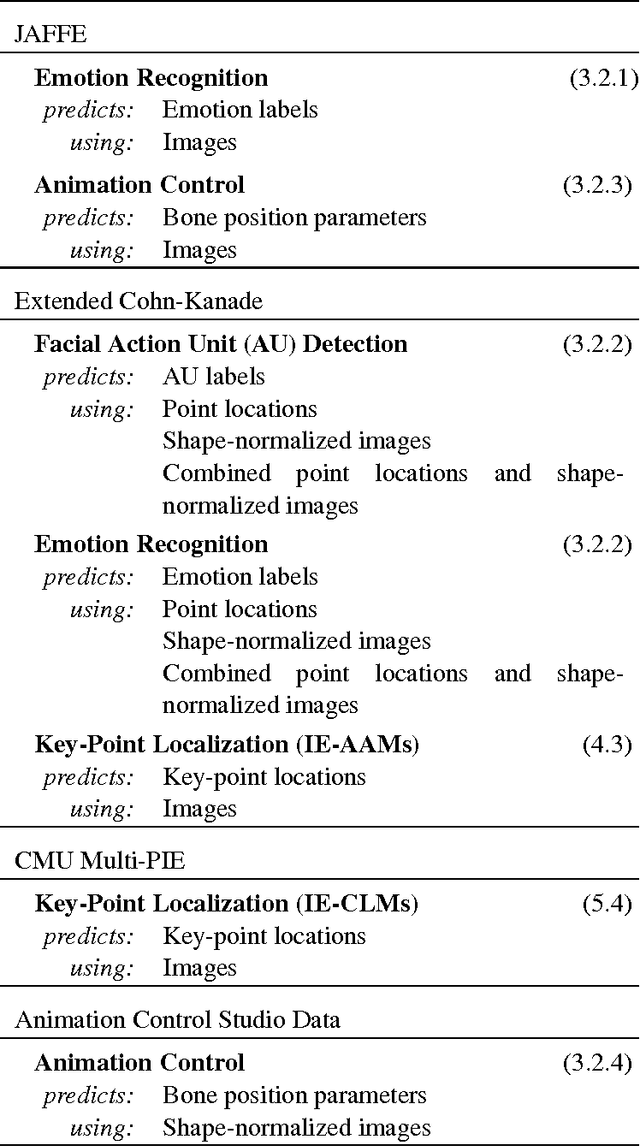

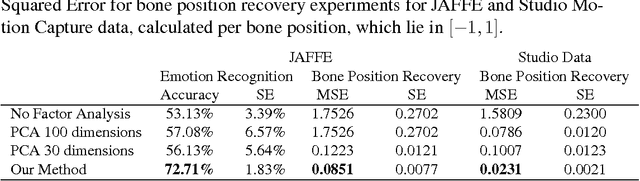
We present techniques for improving performance driven facial animation, emotion recognition, and facial key-point or landmark prediction using learned identity invariant representations. Established approaches to these problems can work well if sufficient examples and labels for a particular identity are available and factors of variation are highly controlled. However, labeled examples of facial expressions, emotions and key-points for new individuals are difficult and costly to obtain. In this paper we improve the ability of techniques to generalize to new and unseen individuals by explicitly modeling previously seen variations related to identity and expression. We use a weakly-supervised approach in which identity labels are used to learn the different factors of variation linked to identity separately from factors related to expression. We show how probabilistic modeling of these sources of variation allows one to learn identity-invariant representations for expressions which can then be used to identity-normalize various procedures for facial expression analysis and animation control. We also show how to extend the widely used techniques of active appearance models and constrained local models through replacing the underlying point distribution models which are typically constructed using principal component analysis with identity-expression factorized representations. We present a wide variety of experiments in which we consistently improve performance on emotion recognition, markerless performance-driven facial animation and facial key-point tracking.