 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving Facial Analysis and Performance Driven Animation through Disentangling Identity and Expression
Paper and Code
May 22, 2016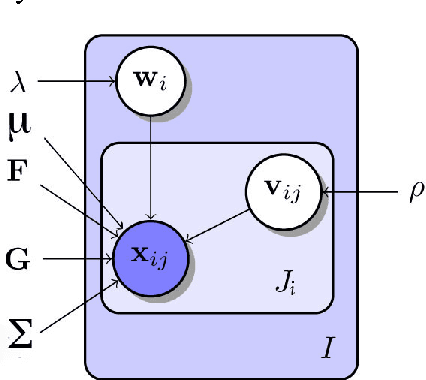

We present techniques for improving performance driven facial animation, emotion recognition, and facial key-point or landmark prediction using learned identity invariant representations. Established approaches to these problems can work well if sufficient examples and labels for a particular identity are available and factors of variation are highly controlled. However, labeled examples of facial expressions, emotions and key-points for new individuals are difficult and costly to obtain. In this paper we improve the ability of techniques to generalize to new and unseen individuals by explicitly modeling previously seen variations related to identity and expression. We use a weakly-supervised approach in which identity labels are used to learn the different factors of variation linked to identity separately from factors related to expression. We show how probabilistic modeling of these sources of variation allows one to learn identity-invariant representations for expressions which can then be used to identity-normalize various procedures for facial expression analysis and animation control. We also show how to extend the widely used techniques of active appearance models and constrained local models through replacing the underlying point distribution models which are typically constructed using principal component analysis with identity-expression factorized representations. We present a wide variety of experiments in which we consistently improve performance on emotion recognition, markerless performance-driven facial animation and facial key-point tracking.