 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProgressive Gradient Flow for Robust N:M Sparsity Training in Transformers
Feb 07, 2024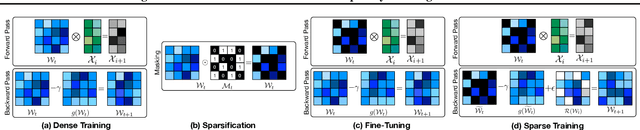


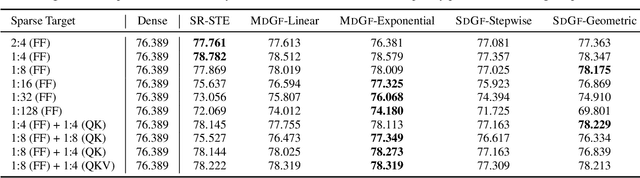
N:M Structured sparsity has garnered significant interest as a result of relatively modest overhead and improved efficiency. Additionally, this form of sparsity holds considerable appeal for reducing the memory footprint owing to their modest representation overhead. There have been efforts to develop training recipes for N:M structured sparsity, they primarily focus on low-sparsity regions ($\sim$50\%). Nonetheless, performance of models trained using these approaches tends to decline when confronted with high-sparsity regions ($>$80\%). In this work, we study the effectiveness of existing sparse training recipes at \textit{high-sparsity regions} and argue that these methods fail to sustain the model quality on par with low-sparsity regions. We demonstrate that the significant factor contributing to this disparity is the presence of elevated levels of induced noise in the gradient magnitudes. To mitigate this undesirable effect, we employ decay mechanisms to progressively restrict the flow of gradients towards pruned elements. Our approach improves the model quality by up to 2$\%$ and 5$\%$ in vision and language models at high sparsity regime, respectively. We also evaluate the trade-off between model accuracy and training compute cost in terms of FLOPs. At iso-training FLOPs, our method yields better performance compared to conventional sparse training recipes, exhibiting an accuracy improvement of up to 2$\%$. The source code is available at https://github.com/abhibambhaniya/progressive_gradient_flow_nm_sparsity.
USM-Lite: Quantization and Sparsity Aware Fine-tuning for Speech Recognition with Universal Speech Models
Jan 03, 2024End-to-end automatic speech recognition (ASR) models have seen revolutionary quality gains with the recent development of large-scale universal speech models (USM). However, deploying these massive USMs is extremely expensive due to the enormous memory usage and computational cost. Therefore, model compression is an important research topic to fit USM-based ASR under budget in real-world scenarios. In this study, we propose a USM fine-tuning approach for ASR, with a low-bit quantization and N:M structured sparsity aware paradigm on the model weights, reducing the model complexity from parameter precision and matrix topology perspectives. We conducted extensive experiments with a 2-billion parameter USM on a large-scale voice search dataset to evaluate our proposed method. A series of ablation studies validate the effectiveness of up to int4 quantization and 2:4 sparsity. However, a single compression technique fails to recover the performance well under extreme setups including int2 quantization and 1:4 sparsity. By contrast, our proposed method can compress the model to have 9.4% of the size, at the cost of only 7.3% relative word error rate (WER) regressions. We also provided in-depth analyses on the results and discussions on the limitations and potential solutions, which would be valuable for future studies.
Gemini: A Family of Highly Capable Multimodal Models
Dec 19, 2023This report introduces a new family of multimodal models, Gemini, that exhibit remarkable capabilities across image, audio, video, and text understanding. The Gemini family consists of Ultra, Pro, and Nano sizes, suitable for applications ranging from complex reasoning tasks to on-device memory-constrained use-cases. Evaluation on a broad range of benchmarks shows that our most-capable Gemini Ultra model advances the state of the art in 30 of 32 of these benchmarks - notably being the first model to achieve human-expert performance on the well-studied exam benchmark MMLU, and improving the state of the art in every one of the 20 multimodal benchmarks we examined. We believe that the new capabilities of Gemini models in cross-modal reasoning and language understanding will enable a wide variety of use cases and we discuss our approach toward deploying them responsibly to users.
JaxPruner: A concise library for sparsity research
May 02, 2023


This paper introduces JaxPruner, an open-source JAX-based pruning and sparse training library for machine learning research. JaxPruner aims to accelerate research on sparse neural networks by providing concise implementations of popular pruning and sparse training algorithms with minimal memory and latency overhead. Algorithms implemented in JaxPruner use a common API and work seamlessly with the popular optimization library Optax, which, in turn, enables easy integration with existing JAX based libraries. We demonstrate this ease of integration by providing examples in four different codebases: Scenic, t5x, Dopamine and FedJAX and provide baseline experiments on popular benchmarks.
STEP: Learning N:M Structured Sparsity Masks from Scratch with Precondition
Feb 02, 2023



Recent innovations on hardware (e.g. Nvidia A100) have motivated learning N:M structured sparsity masks from scratch for fast model inference. However, state-of-the-art learning recipes in this regime (e.g. SR-STE) are proposed for non-adaptive optimizers like momentum SGD, while incurring non-trivial accuracy drop for Adam-trained models like attention-based LLMs. In this paper, we first demonstrate such gap origins from poorly estimated second moment (i.e. variance) in Adam states given by the masked weights. We conjecture that learning N:M masks with Adam should take the critical regime of variance estimation into account. In light of this, we propose STEP, an Adam-aware recipe that learns N:M masks with two phases: first, STEP calculates a reliable variance estimate (precondition phase) and subsequently, the variance remains fixed and is used as a precondition to learn N:M masks (mask-learning phase). STEP automatically identifies the switching point of two phases by dynamically sampling variance changes over the training trajectory and testing the sample concentration. Empirically, we evaluate STEP and other baselines such as ASP and SR-STE on multiple tasks including CIFAR classification, machine translation and LLM fine-tuning (BERT-Base, GPT-2). We show STEP mitigates the accuracy drop of baseline recipes and is robust to aggressive structured sparsity ratios.
Efficiently Scaling Transformer Inference
Nov 09, 2022



We study the problem of efficient generative inference for Transformer models, in one of its most challenging settings: large deep models, with tight latency targets and long sequence lengths. Better understanding of the engineering tradeoffs for inference for large Transformer-based models is important as use cases of these models are growing rapidly throughout application areas. We develop a simple analytical model for inference efficiency to select the best multi-dimensional partitioning techniques optimized for TPU v4 slices based on the application requirements. We combine these with a suite of low-level optimizations to achieve a new Pareto frontier on the latency and model FLOPS utilization (MFU) tradeoffs on 500B+ parameter models that outperforms the FasterTransformer suite of benchmarks. We further show that with appropriate partitioning, the lower memory requirements of multiquery attention (i.e. multiple query heads share single key/value head) enables scaling up to 32x larger context lengths. Finally, we achieve a low-batch-size latency of 29ms per token during generation (using int8 weight quantization) and a 76% MFU during large-batch-size processing of input tokens, while supporting a long 2048-token context length on the PaLM 540B parameter model.
Streaming Parrotron for on-device speech-to-speech conversion
Oct 25, 2022



We present a fully on-device and streaming Speech-To-Speech (STS) conversion model that normalizes a given input speech directly to synthesized output speech (a.k.a. Parrotron). Deploying such an end-to-end model locally on mobile devices pose significant challenges in terms of memory footprint and computation requirements. In this paper, we present a streaming-based approach to produce an acceptable delay, with minimal loss in speech conversion quality, when compared to a non-streaming server-based approach. Our approach consists of first streaming the encoder in real time while the speaker is speaking. Then, as soon as the speaker stops speaking, we run the spectrogram decoder in streaming mode along the side of a streaming vocoder to generate output speech in real time. To achieve an acceptable delay quality trade-off, we study a novel hybrid approach for look-ahead in the encoder which combines a look-ahead feature stacker with a look-ahead self-attention. We also compare the model with int4 quantization aware training and int8 post training quantization and show that our streaming approach is 2x faster than real time on the Pixel4 CPU.
Training Recipe for N:M Structured Sparsity with Decaying Pruning Mask
Sep 15, 2022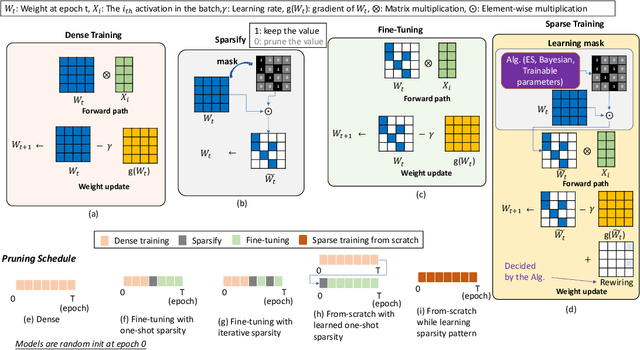

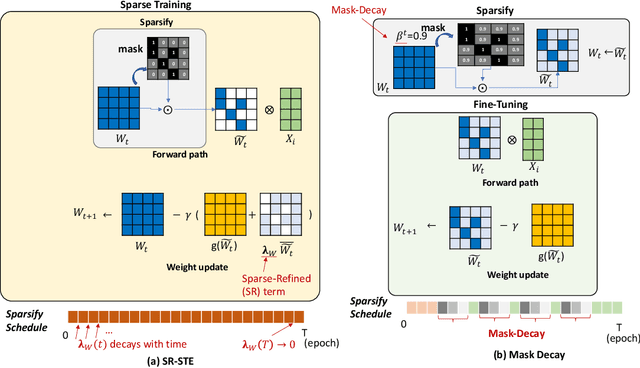

Sparsity has become one of the promising methods to compress and accelerate Deep Neural Networks (DNNs). Among different categories of sparsity, structured sparsity has gained more attention due to its efficient execution on modern accelerators. Particularly, N:M sparsity is attractive because there are already hardware accelerator architectures that can leverage certain forms of N:M structured sparsity to yield higher compute-efficiency. In this work, we focus on N:M sparsity and extensively study and evaluate various training recipes for N:M sparsity in terms of the trade-off between model accuracy and compute cost (FLOPs). Building upon this study, we propose two new decay-based pruning methods, namely "pruning mask decay" and "sparse structure decay". Our evaluations indicate that these proposed methods consistently deliver state-of-the-art (SOTA) model accuracy, comparable to unstructured sparsity, on a Transformer-based model for a translation task. The increase in the accuracy of the sparse model using the new training recipes comes at the cost of marginal increase in the total training compute (FLOPs).
PaLM: Scaling Language Modeling with Pathways
Apr 19, 2022



Large language models have been shown to achieve remarkable performance across a variety of natural language tasks using few-shot learning, which drastically reduces the number of task-specific training examples needed to adapt the model to a particular application. To further our understanding of the impact of scale on few-shot learning, we trained a 540-billion parameter, densely activated, Transformer language model, which we call Pathways Language Model PaLM. We trained PaLM on 6144 TPU v4 chips using Pathways, a new ML system which enables highly efficient training across multiple TPU Pods. We demonstrate continued benefits of scaling by achieving state-of-the-art few-shot learning results on hundreds of language understanding and generation benchmarks. On a number of these tasks, PaLM 540B achieves breakthrough performance, outperforming the finetuned state-of-the-art on a suite of multi-step reasoning tasks, and outperforming average human performance on the recently released BIG-bench benchmark. A significant number of BIG-bench tasks showed discontinuous improvements from model scale, meaning that performance steeply increased as we scaled to our largest model. PaLM also has strong capabilities in multilingual tasks and source code generation, which we demonstrate on a wide array of benchmarks. We additionally provide a comprehensive analysis on bias and toxicity, and study the extent of training data memorization with respect to model scale. Finally, we discuss the ethical considerations related to large language models and discuss potential mitigation strategies.
4-bit Conformer with Native Quantization Aware Training for Speech Recognition
Mar 29, 2022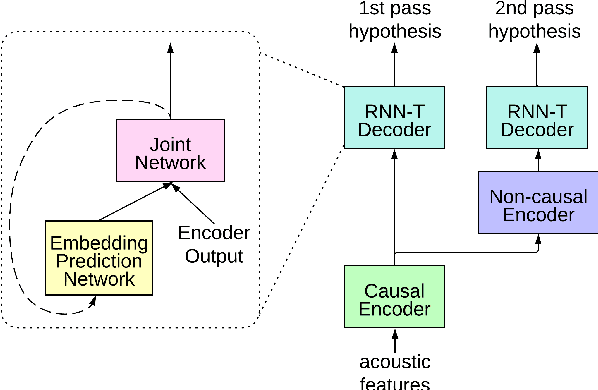
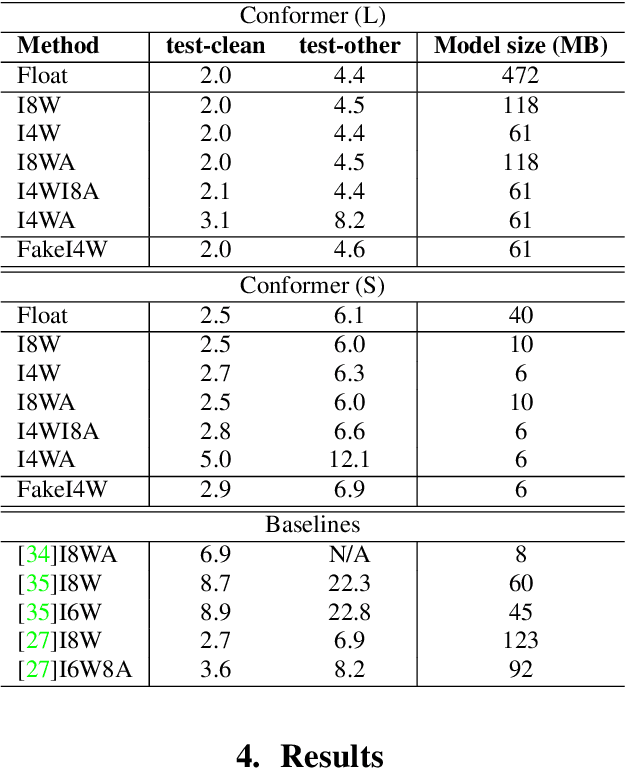

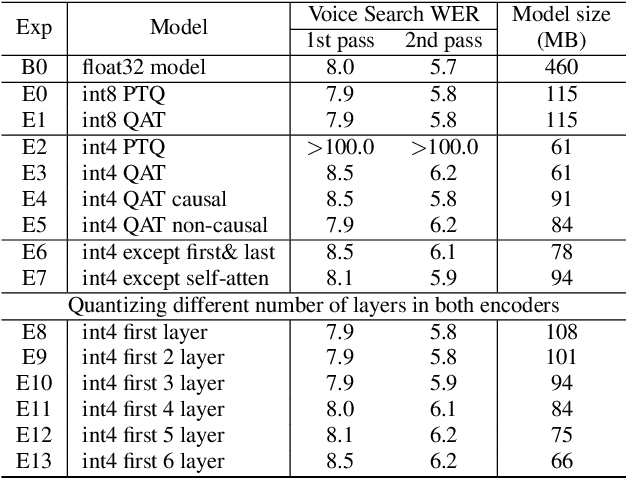
Reducing the latency and model size has always been a significant research problem for live Automatic Speech Recognition (ASR) application scenarios. Along this direction, model quantization has become an increasingly popular approach to compress neural networks and reduce computation cost. Most of the existing practical ASR systems apply post-training 8-bit quantization. To achieve a higher compression rate without introducing additional performance regression, in this study, we propose to develop 4-bit ASR models with native quantization aware training, which leverages native integer operations to effectively optimize both training and inference. We conducted two experiments on state-of-the-art Conformer-based ASR models to evaluate our proposed quantization technique. First, we explored the impact of different precisions for both weight and activation quantization on the LibriSpeech dataset, and obtained a lossless 4-bit Conformer model with 7.7x size reduction compared to the float32 model. Following this, we for the first time investigated and revealed the viability of 4-bit quantization on a practical ASR system that is trained with large-scale datasets, and produced a lossless Conformer ASR model with mixed 4-bit and 8-bit weights that has 5x size reduction compared to the float32 model.