 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeZero-shot Cross-lingual Voice Transfer for TTS
Sep 20, 2024

In this paper, we introduce a zero-shot Voice Transfer (VT) module that can be seamlessly integrated into a multi-lingual Text-to-speech (TTS) system to transfer an individual's voice across languages. Our proposed VT module comprises a speaker-encoder that processes reference speech, a bottleneck layer, and residual adapters, connected to preexisting TTS layers. We compare the performance of various configurations of these components and report Mean Opinion Score (MOS) and Speaker Similarity across languages. Using a single English reference speech per speaker, we achieve an average voice transfer similarity score of 73% across nine target languages. Vocal characteristics contribute significantly to the construction and perception of individual identity. The loss of one's voice, due to physical or neurological conditions, can lead to a profound sense of loss, impacting one's core identity. As a case study, we demonstrate that our approach can not only transfer typical speech but also restore the voices of individuals with dysarthria, even when only atypical speech samples are available - a valuable utility for those who have never had typical speech or banked their voice. Cross-lingual typical audio samples, plus videos demonstrating voice restoration for dysarthric speakers are available here (google.github.io/tacotron/publications/zero_shot_voice_transfer).
Hierarchical Recurrent Adapters for Efficient Multi-Task Adaptation of Large Speech Models
Mar 25, 2024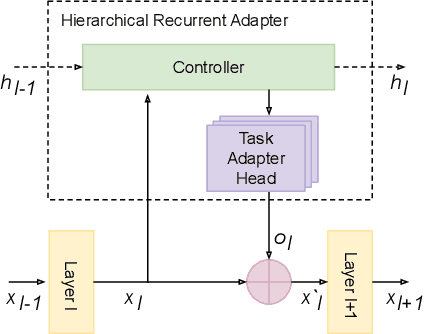
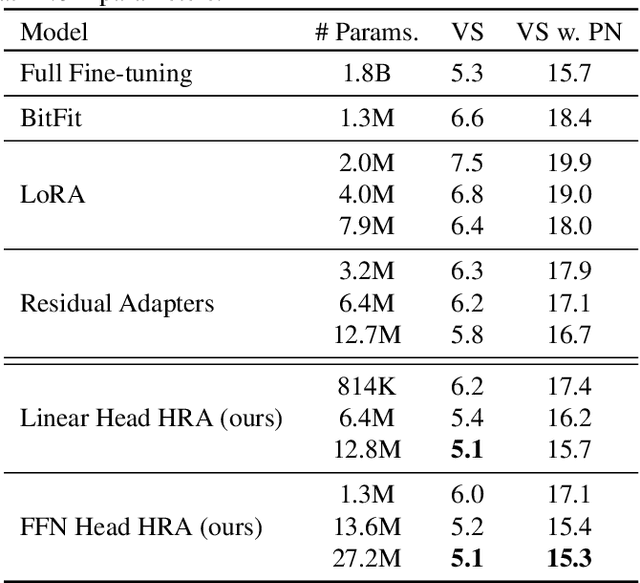
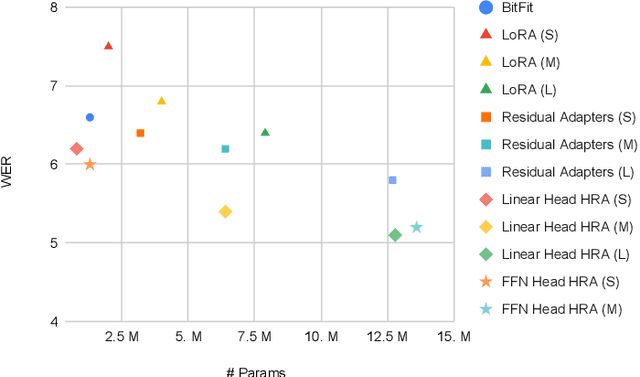
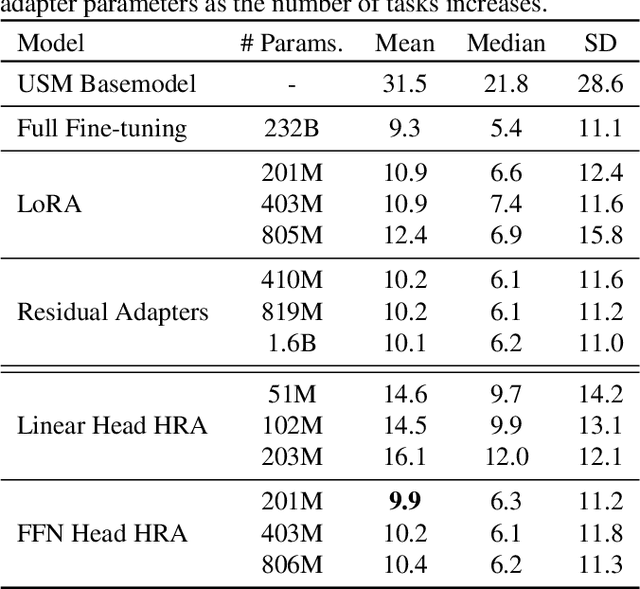
Parameter efficient adaptation methods have become a key mechanism to train large pre-trained models for downstream tasks. However, their per-task parameter overhead is considered still high when the number of downstream tasks to adapt for is large. We introduce an adapter module that has a better efficiency in large scale multi-task adaptation scenario. Our adapter is hierarchical in terms of how the adapter parameters are allocated. The adapter consists of a single shared controller network and multiple task-level adapter heads to reduce the per-task parameter overhead without performance regression on downstream tasks. The adapter is also recurrent so the entire adapter parameters are reused across different layers of the pre-trained model. Our Hierarchical Recurrent Adapter (HRA) outperforms the previous adapter-based approaches as well as full model fine-tuning baseline in both single and multi-task adaptation settings when evaluated on automatic speech recognition tasks.
Streaming Parrotron for on-device speech-to-speech conversion
Oct 25, 2022



We present a fully on-device and streaming Speech-To-Speech (STS) conversion model that normalizes a given input speech directly to synthesized output speech (a.k.a. Parrotron). Deploying such an end-to-end model locally on mobile devices pose significant challenges in terms of memory footprint and computation requirements. In this paper, we present a streaming-based approach to produce an acceptable delay, with minimal loss in speech conversion quality, when compared to a non-streaming server-based approach. Our approach consists of first streaming the encoder in real time while the speaker is speaking. Then, as soon as the speaker stops speaking, we run the spectrogram decoder in streaming mode along the side of a streaming vocoder to generate output speech in real time. To achieve an acceptable delay quality trade-off, we study a novel hybrid approach for look-ahead in the encoder which combines a look-ahead feature stacker with a look-ahead self-attention. We also compare the model with int4 quantization aware training and int8 post training quantization and show that our streaming approach is 2x faster than real time on the Pixel4 CPU.
Non-Parallel Voice Conversion for ASR Augmentation
Sep 15, 2022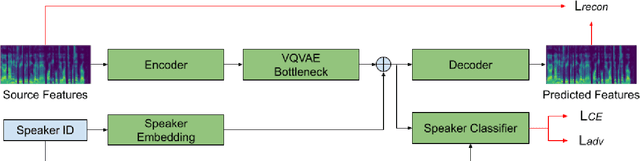
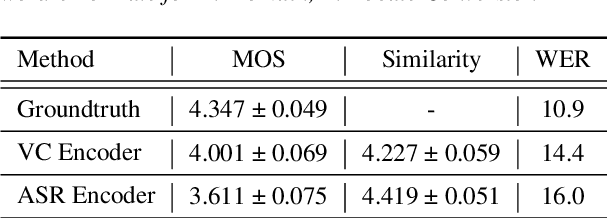
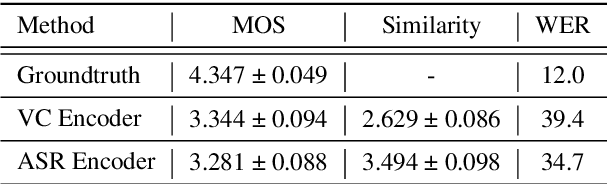
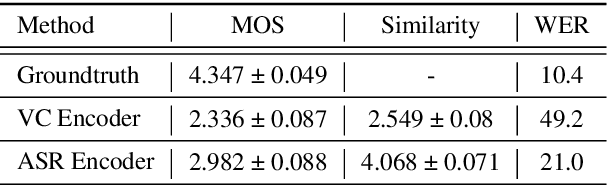
Automatic speech recognition (ASR) needs to be robust to speaker differences. Voice Conversion (VC) modifies speaker characteristics of input speech. This is an attractive feature for ASR data augmentation. In this paper, we demonstrate that voice conversion can be used as a data augmentation technique to improve ASR performance, even on LibriSpeech, which contains 2,456 speakers. For ASR augmentation, it is necessary that the VC model be robust to a wide range of input speech. This motivates the use of a non-autoregressive, non-parallel VC model, and the use of a pretrained ASR encoder within the VC model. This work suggests that despite including many speakers, speaker diversity may remain a limitation to ASR quality. Finally, interrogation of our VC performance has provided useful metrics for objective evaluation of VC quality.
A Scalable Model Specialization Framework for Training and Inference using Submodels and its Application to Speech Model Personalization
Mar 23, 2022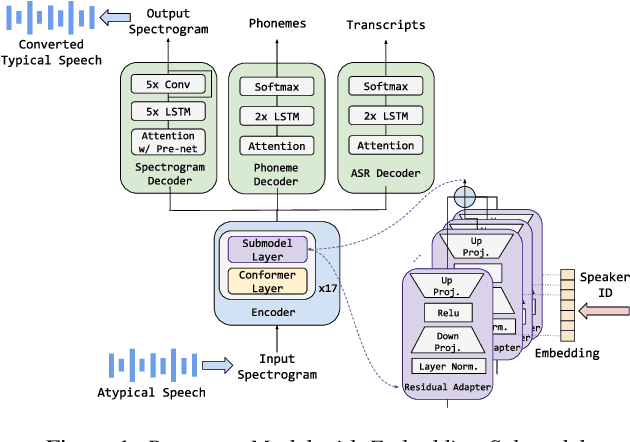
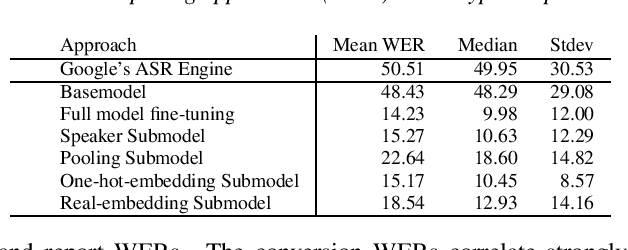
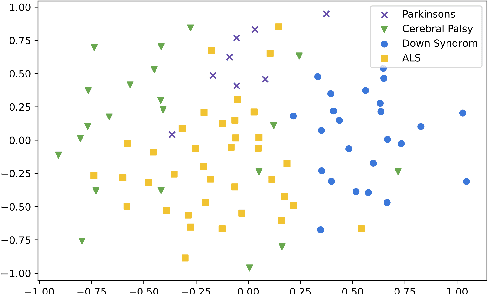
Model fine-tuning and adaptation have become a common approach for model specialization for downstream tasks or domains. Fine-tuning the entire model or a subset of the parameters using light-weight adaptation has shown considerable success across different specialization tasks. Fine-tuning a model for a large number of domains typically requires starting a new training job for every domain posing scaling limitations. Once these models are trained, deploying them also poses significant scalability challenges for inference for real-time applications. In this paper, building upon prior light-weight adaptation techniques, we propose a modular framework that enables us to substantially improve scalability for model training and inference. We introduce Submodels that can be quickly and dynamically loaded for on-the-fly inference. We also propose multiple approaches for training those Submodels in parallel using an embedding space in the same training job. We test our framework on an extreme use-case which is speech model personalization for atypical speech, requiring a Submodel for each user. We obtain 128x Submodel throughput with a fixed computation budget without a loss of accuracy. We also show that learning a speaker-embedding space can scale further and reduce the amount of personalization training data required per speaker.
Real time spectrogram inversion on mobile phone
Mar 10, 2022
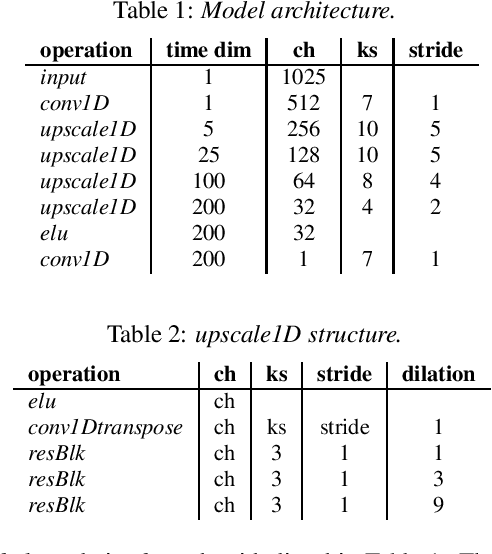


With the growth of computing power on mobile phones and privacy concerns over user's data, on-device real time speech processing has become an important research topic. In this paper, we focus on methods for real time spectrogram inversion, where an algorithm receives a portion of the input signal (e.g., one frame) and processes it incrementally, i.e., operating in streaming mode. We present a real time Griffin Lim(GL) algorithm using a sliding window approach in STFT domain. The proposed algorithm is 2.4x faster than real time on the ARM CPU of a Pixel4. In addition we explore a neural vocoder operating in streaming mode and demonstrate the impact of looking ahead on perceptual quality. As little as one hop size (12.5ms) of lookahead is able to significantly improve perceptual quality in comparison to a causal model. We compare GL with the neural vocoder and show different trade-offs in terms of perceptual quality, on-device latency, algorithmic delay, memory footprint and noise sensitivity. For fair quality assessment of the GL approach, we use input log magnitude spectrogram without mel transformation. We evaluate presented real time spectrogram inversion approaches on clean, noisy and atypical speech.
Residual Adapters for Parameter-Efficient ASR Adaptation to Atypical and Accented Speech
Sep 14, 2021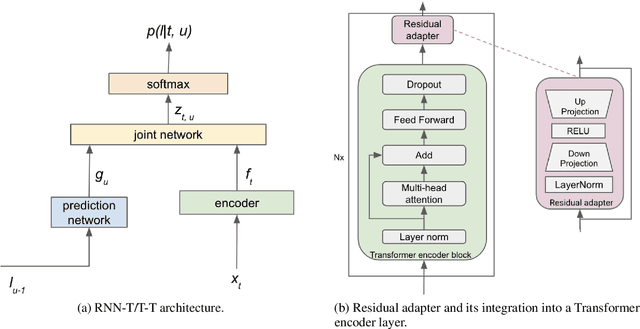
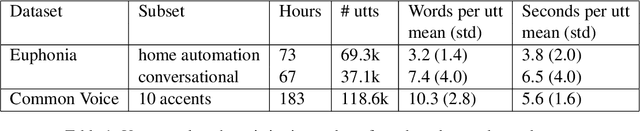
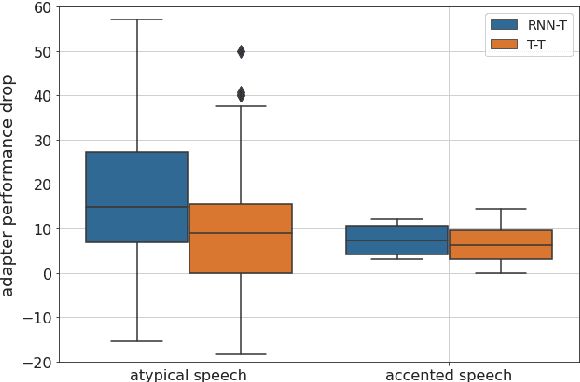
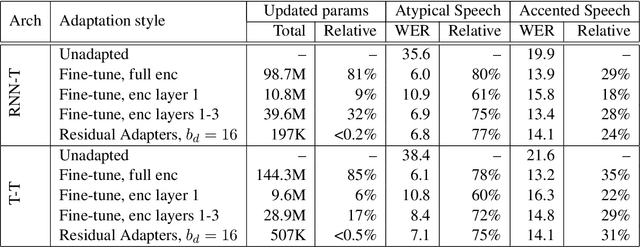
Automatic Speech Recognition (ASR) systems are often optimized to work best for speakers with canonical speech patterns. Unfortunately, these systems perform poorly when tested on atypical speech and heavily accented speech. It has previously been shown that personalization through model fine-tuning substantially improves performance. However, maintaining such large models per speaker is costly and difficult to scale. We show that by adding a relatively small number of extra parameters to the encoder layers via so-called residual adapter, we can achieve similar adaptation gains compared to model fine-tuning, while only updating a tiny fraction (less than 0.5%) of the model parameters. We demonstrate this on two speech adaptation tasks (atypical and accented speech) and for two state-of-the-art ASR architectures.
Direct speech-to-speech translation with a sequence-to-sequence model
Apr 12, 2019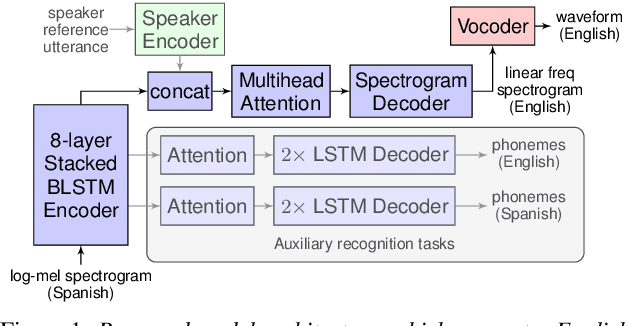
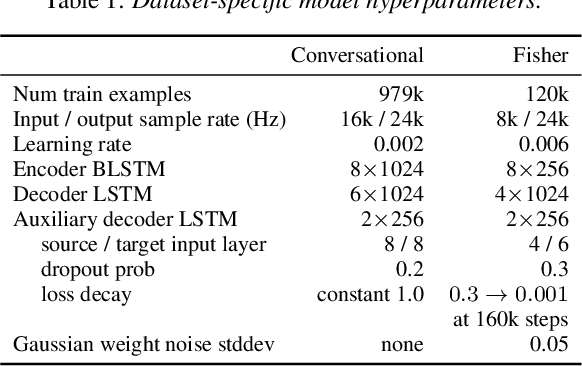
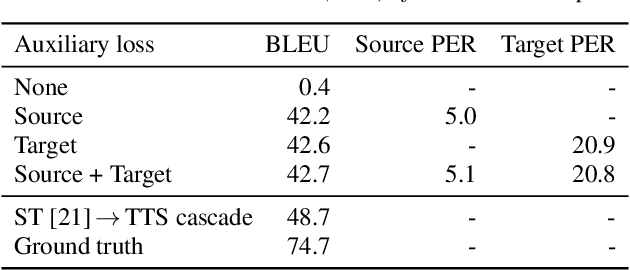
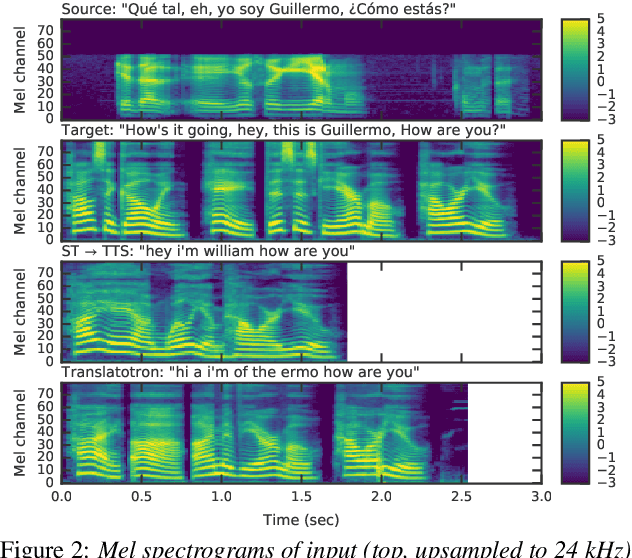
We present an attention-based sequence-to-sequence neural network which can directly translate speech from one language into speech in another language, without relying on an intermediate text representation. The network is trained end-to-end, learning to map speech spectrograms into target spectrograms in another language, corresponding to the translated content (in a different canonical voice). We further demonstrate the ability to synthesize translated speech using the voice of the source speaker. We conduct experiments on two Spanish-to-English speech translation datasets, and find that the proposed model slightly underperforms a baseline cascade of a direct speech-to-text translation model and a text-to-speech synthesis model, demonstrating the feasibility of the approach on this very challenging task.