 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNon-Parallel Voice Conversion for ASR Augmentation
Paper and Code
Sep 15, 2022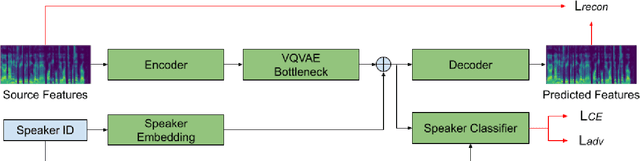
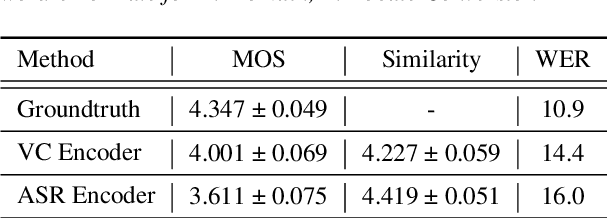
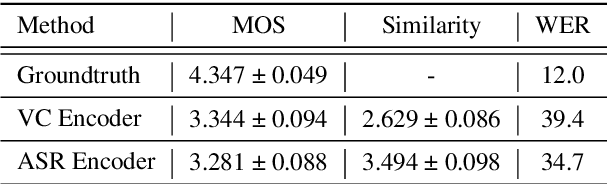
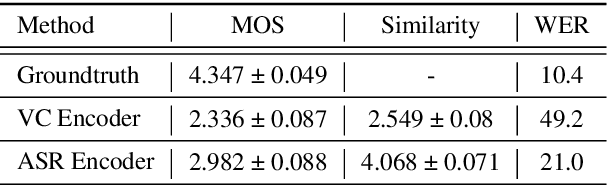
Automatic speech recognition (ASR) needs to be robust to speaker differences. Voice Conversion (VC) modifies speaker characteristics of input speech. This is an attractive feature for ASR data augmentation. In this paper, we demonstrate that voice conversion can be used as a data augmentation technique to improve ASR performance, even on LibriSpeech, which contains 2,456 speakers. For ASR augmentation, it is necessary that the VC model be robust to a wide range of input speech. This motivates the use of a non-autoregressive, non-parallel VC model, and the use of a pretrained ASR encoder within the VC model. This work suggests that despite including many speakers, speaker diversity may remain a limitation to ASR quality. Finally, interrogation of our VC performance has provided useful metrics for objective evaluation of VC quality.