 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAI-Augmented LLMs Achieve Therapist-Level Responses in Motivational Interviewing
May 23, 2025Large language models (LLMs) like GPT-4 show potential for scaling motivational interviewing (MI) in addiction care, but require systematic evaluation of therapeutic capabilities. We present a computational framework assessing user-perceived quality (UPQ) through expected and unexpected MI behaviors. Analyzing human therapist and GPT-4 MI sessions via human-AI collaboration, we developed predictive models integrating deep learning and explainable AI to identify 17 MI-consistent (MICO) and MI-inconsistent (MIIN) behavioral metrics. A customized chain-of-thought prompt improved GPT-4's MI performance, reducing inappropriate advice while enhancing reflections and empathy. Although GPT-4 remained marginally inferior to therapists overall, it demonstrated superior advice management capabilities. The model achieved measurable quality improvements through prompt engineering, yet showed limitations in addressing complex emotional nuances. This framework establishes a pathway for optimizing LLM-based therapeutic tools through targeted behavioral metric analysis and human-AI co-evaluation. Findings highlight both the scalability potential and current constraints of LLMs in clinical communication applications.
Display Content, Display Methods and Evaluation Methods of the HCI in Explainable Recommender Systems: A Survey
May 14, 2025Explainable Recommender Systems (XRS) aim to provide users with understandable reasons for the recommendations generated by these systems, representing a crucial research direction in artificial intelligence (AI). Recent research has increasingly focused on the algorithms, display, and evaluation methodologies of XRS. While current research and reviews primarily emphasize the algorithmic aspects, with fewer studies addressing the Human-Computer Interaction (HCI) layer of XRS. Additionally, existing reviews lack a unified taxonomy for XRS and there is insufficient attention given to the emerging area of short video recommendations. In this study, we synthesize existing literature and surveys on XRS, presenting a unified framework for its research and development. The main contributions are as follows: 1) We adopt a lifecycle perspective to systematically summarize the technologies and methods used in XRS, addressing challenges posed by the diversity and complexity of algorithmic models and explanation techniques. 2) For the first time, we highlight the application of multimedia, particularly video-based explanations, along with its potential, technical pathways, and challenges in XRS. 3) We provide a structured overview of evaluation methods from both qualitative and quantitative dimensions. These findings provide valuable insights for the systematic design, progress, and testing of XRS.
Bayes-Optimal Fair Classification with Multiple Sensitive Features
May 01, 2025Existing theoretical work on Bayes-optimal fair classifiers usually considers a single (binary) sensitive feature. In practice, individuals are often defined by multiple sensitive features. In this paper, we characterize the Bayes-optimal fair classifier for multiple sensitive features under general approximate fairness measures, including mean difference and mean ratio. We show that these approximate measures for existing group fairness notions, including Demographic Parity, Equal Opportunity, Predictive Equality, and Accuracy Parity, are linear transformations of selection rates for specific groups defined by both labels and sensitive features. We then characterize that Bayes-optimal fair classifiers for multiple sensitive features become instance-dependent thresholding rules that rely on a weighted sum of these group membership probabilities. Our framework applies to both attribute-aware and attribute-blind settings and can accommodate composite fairness notions like Equalized Odds. Building on this, we propose two practical algorithms for Bayes-optimal fair classification via in-processing and post-processing. We show empirically that our methods compare favorably to existing methods.
An Enhanced Zeroth-Order Stochastic Frank-Wolfe Framework for Constrained Finite-Sum Optimization
Jan 13, 2025We propose an enhanced zeroth-order stochastic Frank-Wolfe framework to address constrained finite-sum optimization problems, a structure prevalent in large-scale machine-learning applications. Our method introduces a novel double variance reduction framework that effectively reduces the gradient approximation variance induced by zeroth-order oracles and the stochastic sampling variance from finite-sum objectives. By leveraging this framework, our algorithm achieves significant improvements in query efficiency, making it particularly well-suited for high-dimensional optimization tasks. Specifically, for convex objectives, the algorithm achieves a query complexity of O(d \sqrt{n}/\epsilon ) to find an epsilon-suboptimal solution, where d is the dimensionality and n is the number of functions in the finite-sum objective. For non-convex objectives, it achieves a query complexity of O(d^{3/2}\sqrt{n}/\epsilon^2 ) without requiring the computation ofd partial derivatives at each iteration. These complexities are the best known among zeroth-order stochastic Frank-Wolfe algorithms that avoid explicit gradient calculations. Empirical experiments on convex and non-convex machine learning tasks, including sparse logistic regression, robust classification, and adversarial attacks on deep networks, validate the computational efficiency and scalability of our approach. Our algorithm demonstrates superior performance in both convergence rate and query complexity compared to existing methods.
Large-scale Language Model Rescoring on Long-form Data
Jun 13, 2023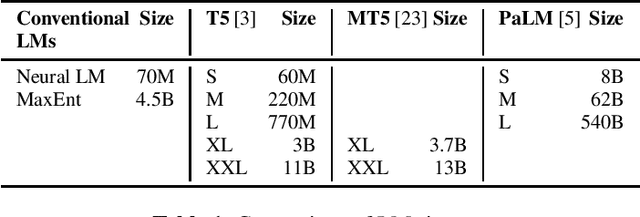
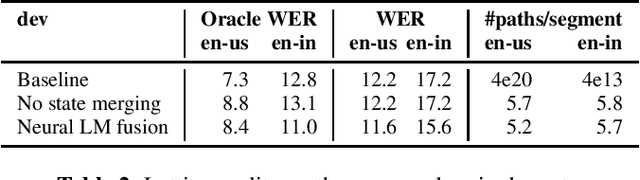


In this work, we study the impact of Large-scale Language Models (LLM) on Automated Speech Recognition (ASR) of YouTube videos, which we use as a source for long-form ASR. We demonstrate up to 8\% relative reduction in Word Error Eate (WER) on US English (en-us) and code-switched Indian English (en-in) long-form ASR test sets and a reduction of up to 30\% relative on Salient Term Error Rate (STER) over a strong first-pass baseline that uses a maximum-entropy based language model. Improved lattice processing that results in a lattice with a proper (non-tree) digraph topology and carrying context from the 1-best hypothesis of the previous segment(s) results in significant wins in rescoring with LLMs. We also find that the gains in performance from the combination of LLMs trained on vast quantities of available data (such as C4) and conventional neural LMs is additive and significantly outperforms a strong first-pass baseline with a maximum entropy LM.
* 5 pages, accepted in ICASSP 2023
Modular Hybrid Autoregressive Transducer
Oct 31, 2022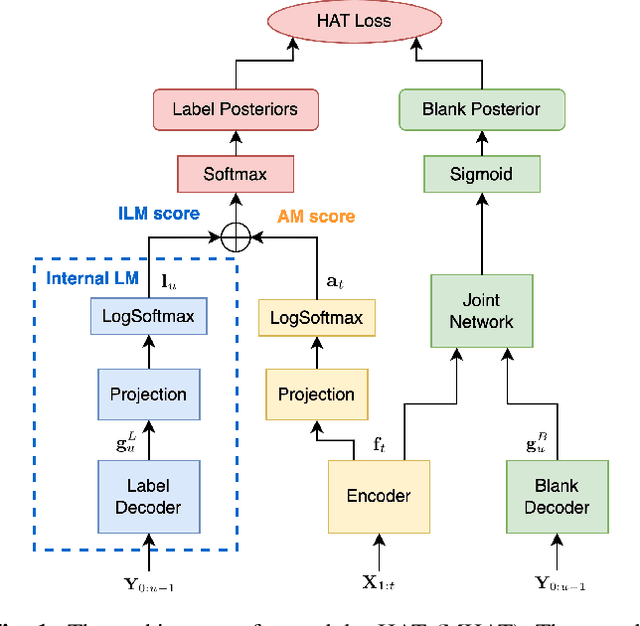
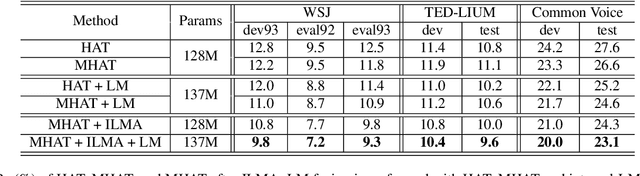
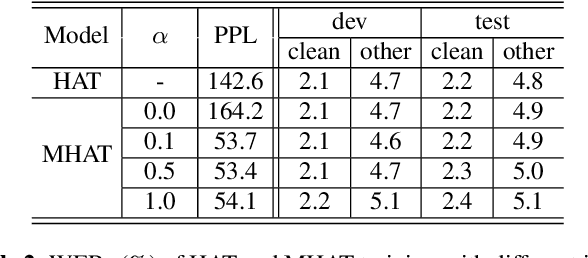
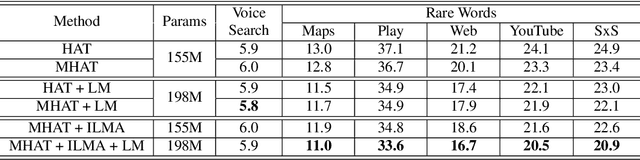
Text-only adaptation of a transducer model remains challenging for end-to-end speech recognition since the transducer has no clearly separated acoustic model (AM), language model (LM) or blank model. In this work, we propose a modular hybrid autoregressive transducer (MHAT) that has structurally separated label and blank decoders to predict label and blank distributions, respectively, along with a shared acoustic encoder. The encoder and label decoder outputs are directly projected to AM and internal LM scores and then added to compute label posteriors. We train MHAT with an internal LM loss and a HAT loss to ensure that its internal LM becomes a standalone neural LM that can be effectively adapted to text. Moreover, text adaptation of MHAT fosters a much better LM fusion than internal LM subtraction-based methods. On Google's large-scale production data, a multi-domain MHAT adapted with 100B sentences achieves relative WER reductions of up to 12.4% without LM fusion and 21.5% with LM fusion from 400K-hour trained HAT.
* 8 pages, 1 figure, SLT 2022
Non-Parallel Voice Conversion for ASR Augmentation
Sep 15, 2022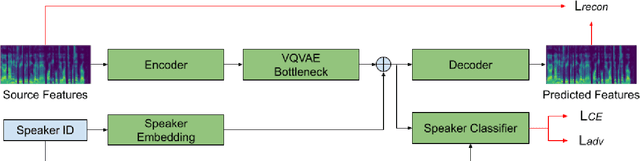
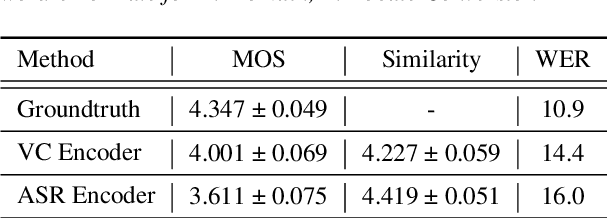
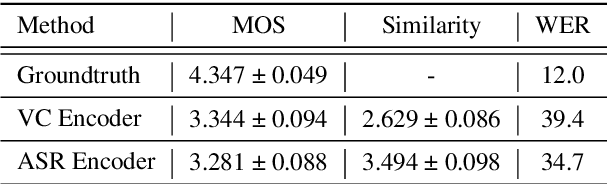
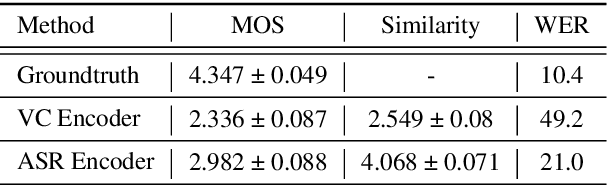
Automatic speech recognition (ASR) needs to be robust to speaker differences. Voice Conversion (VC) modifies speaker characteristics of input speech. This is an attractive feature for ASR data augmentation. In this paper, we demonstrate that voice conversion can be used as a data augmentation technique to improve ASR performance, even on LibriSpeech, which contains 2,456 speakers. For ASR augmentation, it is necessary that the VC model be robust to a wide range of input speech. This motivates the use of a non-autoregressive, non-parallel VC model, and the use of a pretrained ASR encoder within the VC model. This work suggests that despite including many speakers, speaker diversity may remain a limitation to ASR quality. Finally, interrogation of our VC performance has provided useful metrics for objective evaluation of VC quality.
Analysis of Self-Attention Head Diversity for Conformer-based Automatic Speech Recognition
Sep 13, 2022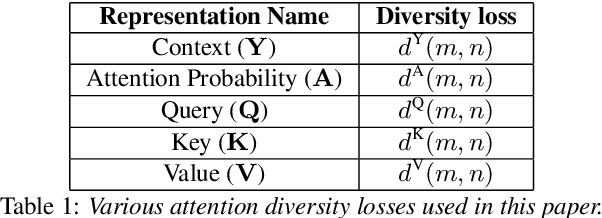
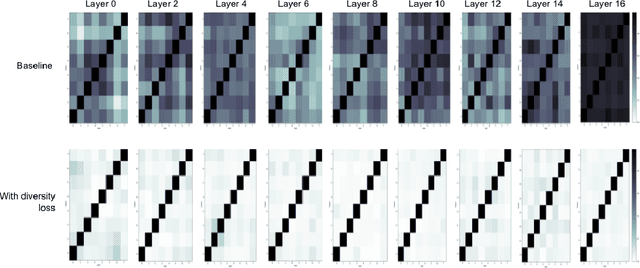
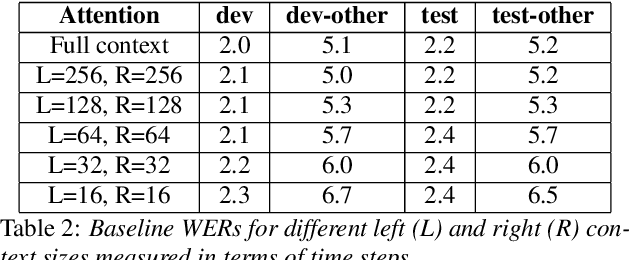
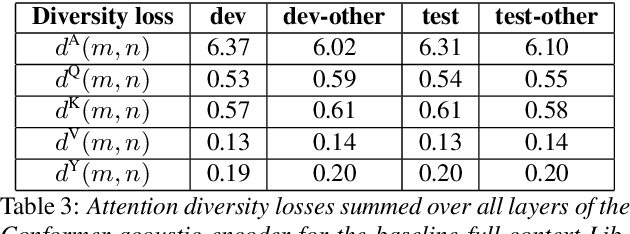
Attention layers are an integral part of modern end-to-end automatic speech recognition systems, for instance as part of the Transformer or Conformer architecture. Attention is typically multi-headed, where each head has an independent set of learned parameters and operates on the same input feature sequence. The output of multi-headed attention is a fusion of the outputs from the individual heads. We empirically analyze the diversity between representations produced by the different attention heads and demonstrate that the heads become highly correlated during the course of training. We investigate a few approaches to increasing attention head diversity, including using different attention mechanisms for each head and auxiliary training loss functions to promote head diversity. We show that introducing diversity-promoting auxiliary loss functions during training is a more effective approach, and obtain WER improvements of up to 6% relative on the Librispeech corpus. Finally, we draw a connection between the diversity of attention heads and the similarity of the gradients of head parameters.
Leveraging Unpaired Text Data for Training End-to-End Speech-to-Intent Systems
Oct 08, 2020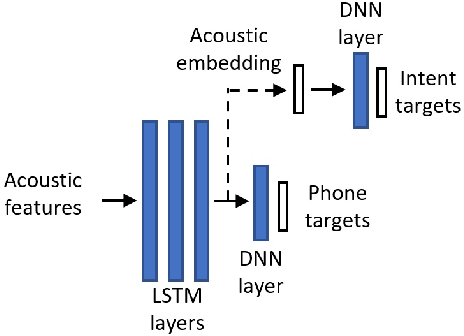

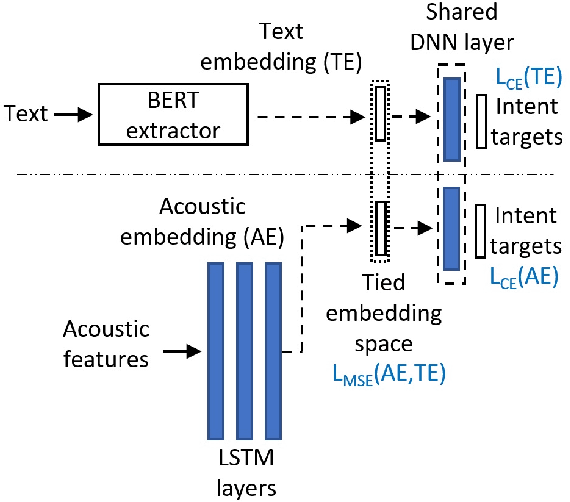
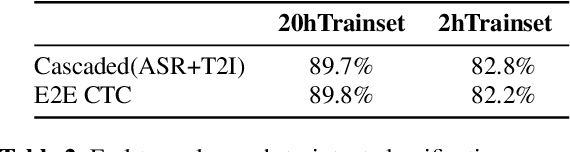
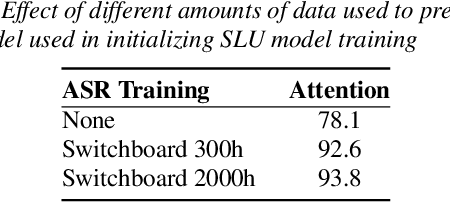
Training an end-to-end (E2E) neural network speech-to-intent (S2I) system that directly extracts intents from speech requires large amounts of intent-labeled speech data, which is time consuming and expensive to collect. Initializing the S2I model with an ASR model trained on copious speech data can alleviate data sparsity. In this paper, we attempt to leverage NLU text resources. We implemented a CTC-based S2I system that matches the performance of a state-of-the-art, traditional cascaded SLU system. We performed controlled experiments with varying amounts of speech and text training data. When only a tenth of the original data is available, intent classification accuracy degrades by 7.6% absolute. Assuming we have additional text-to-intent data (without speech) available, we investigated two techniques to improve the S2I system: (1) transfer learning, in which acoustic embeddings for intent classification are tied to fine-tuned BERT text embeddings; and (2) data augmentation, in which the text-to-intent data is converted into speech-to-intent data using a multi-speaker text-to-speech system. The proposed approaches recover 80% of performance lost due to using limited intent-labeled speech.
End-to-End Spoken Language Understanding Without Full Transcripts
Sep 30, 2020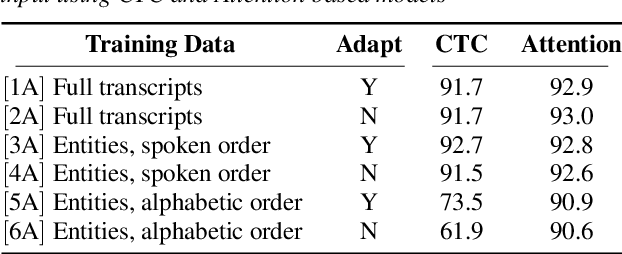
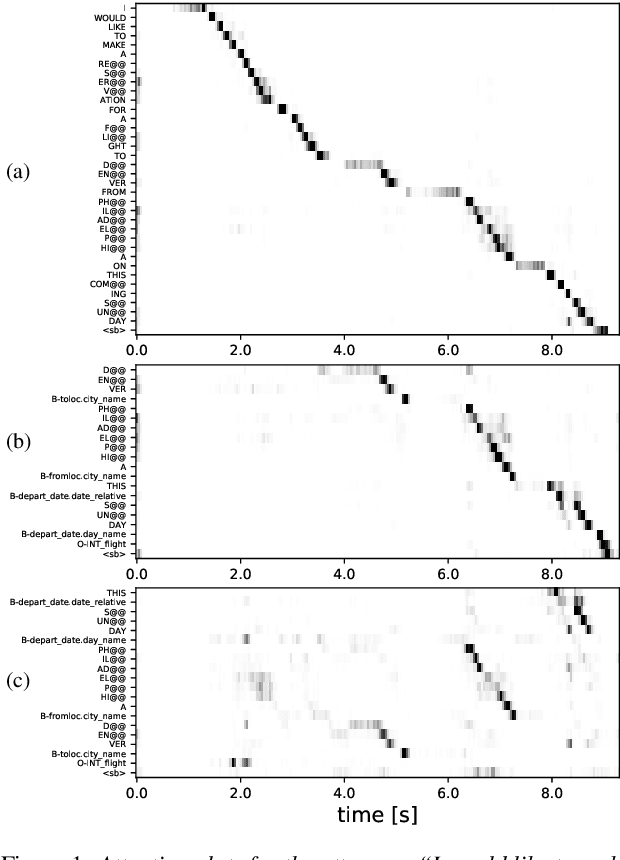

An essential component of spoken language understanding (SLU) is slot filling: representing the meaning of a spoken utterance using semantic entity labels. In this paper, we develop end-to-end (E2E) spoken language understanding systems that directly convert speech input to semantic entities and investigate if these E2E SLU models can be trained solely on semantic entity annotations without word-for-word transcripts. Training such models is very useful as they can drastically reduce the cost of data collection. We created two types of such speech-to-entities models, a CTC model and an attention-based encoder-decoder model, by adapting models trained originally for speech recognition. Given that our experiments involve speech input, these systems need to recognize both the entity label and words representing the entity value correctly. For our speech-to-entities experiments on the ATIS corpus, both the CTC and attention models showed impressive ability to skip non-entity words: there was little degradation when trained on just entities versus full transcripts. We also explored the scenario where the entities are in an order not necessarily related to spoken order in the utterance. With its ability to do re-ordering, the attention model did remarkably well, achieving only about 2% degradation in speech-to-bag-of-entities F1 score.