 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExtending RNN-T-based speech recognition systems with emotion and language classification
Jul 28, 2022
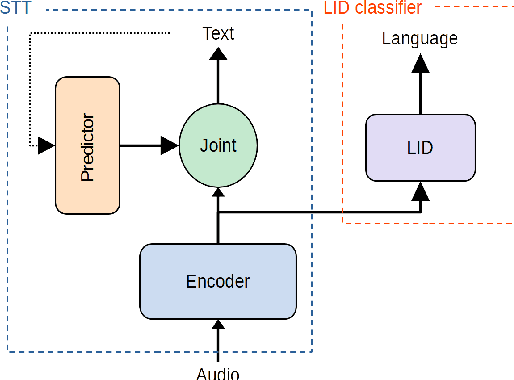
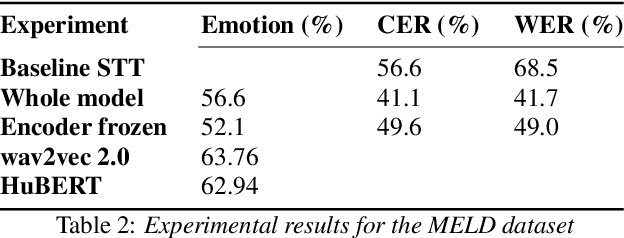
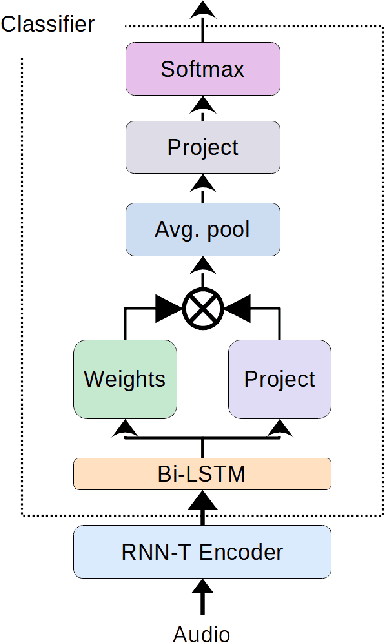
Speech transcription, emotion recognition, and language identification are usually considered to be three different tasks. Each one requires a different model with a different architecture and training process. We propose using a recurrent neural network transducer (RNN-T)-based speech-to-text (STT) system as a common component that can be used for emotion recognition and language identification as well as for speech recognition. Our work extends the STT system for emotion classification through minimal changes, and shows successful results on the IEMOCAP and MELD datasets. In addition, we demonstrate that by adding a lightweight component to the RNN-T module, it can also be used for language identification. In our evaluations, this new classifier demonstrates state-of-the-art accuracy for the NIST-LRE-07 dataset.
A new data augmentation method for intent classification enhancement and its application on spoken conversation datasets
Feb 21, 2022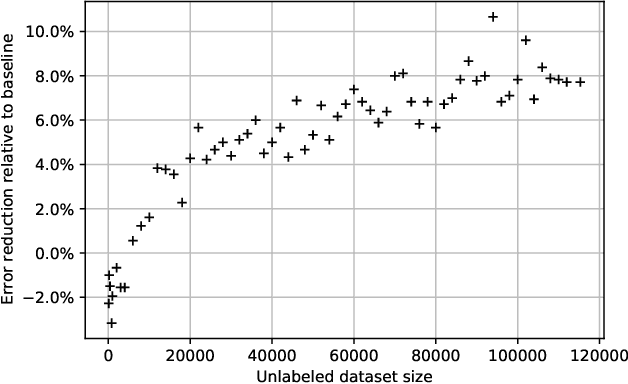
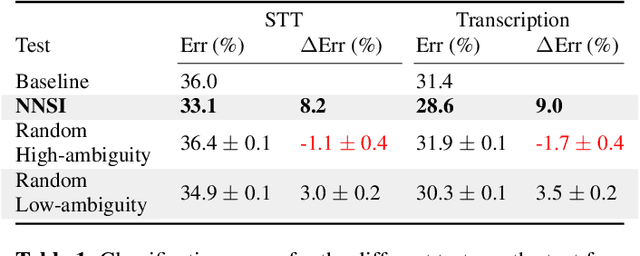
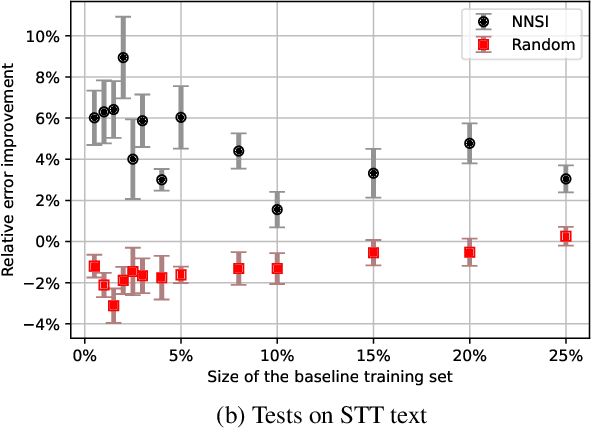
Intent classifiers are vital to the successful operation of virtual agent systems. This is especially so in voice activated systems where the data can be noisy with many ambiguous directions for user intents. Before operation begins, these classifiers are generally lacking in real-world training data. Active learning is a common approach used to help label large amounts of collected user input. However, this approach requires many hours of manual labeling work. We present the Nearest Neighbors Scores Improvement (NNSI) algorithm for automatic data selection and labeling. The NNSI reduces the need for manual labeling by automatically selecting highly-ambiguous samples and labeling them with high accuracy. This is done by integrating the classifier's output from a semantically similar group of text samples. The labeled samples can then be added to the training set to improve the accuracy of the classifier. We demonstrated the use of NNSI on two large-scale, real-life voice conversation systems. Evaluation of our results showed that our method was able to select and label useful samples with high accuracy. Adding these new samples to the training data significantly improved the classifiers and reduced error rates by up to 10%.
Speak or Chat with Me: End-to-End Spoken Language Understanding System with Flexible Inputs
Apr 07, 2021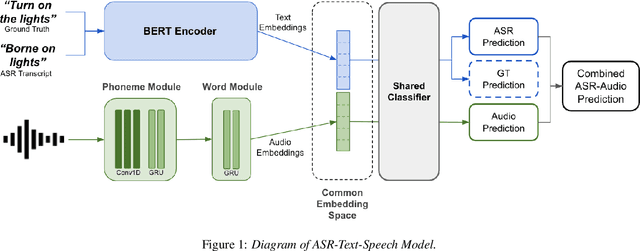
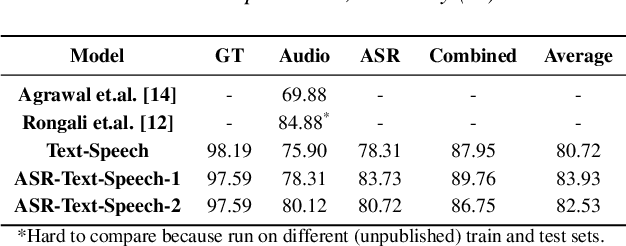
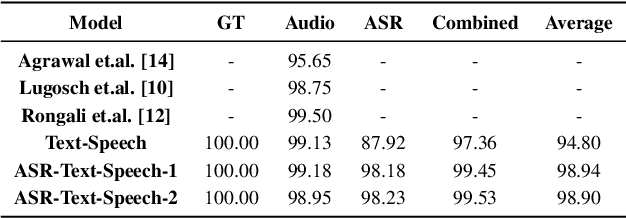
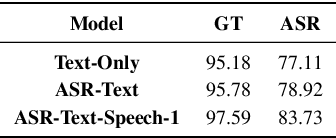
A major focus of recent research in spoken language understanding (SLU) has been on the end-to-end approach where a single model can predict intents directly from speech inputs without intermediate transcripts. However, this approach presents some challenges. First, since speech can be considered as personally identifiable information, in some cases only automatic speech recognition (ASR) transcripts are accessible. Second, intent-labeled speech data is scarce. To address the first challenge, we propose a novel system that can predict intents from flexible types of inputs: speech, ASR transcripts, or both. We demonstrate strong performance for either modality separately, and when both speech and ASR transcripts are available, through system combination, we achieve better results than using a single input modality. To address the second challenge, we leverage a semantically robust pre-trained BERT model and adopt a cross-modal system that co-trains text embeddings and acoustic embeddings in a shared latent space. We further enhance this system by utilizing an acoustic module pre-trained on LibriSpeech and domain-adapting the text module on our target datasets. Our experiments show significant advantages for these pre-training and fine-tuning strategies, resulting in a system that achieves competitive intent-classification performance on Snips SLU and Fluent Speech Commands datasets.
Leveraging Unpaired Text Data for Training End-to-End Speech-to-Intent Systems
Oct 08, 2020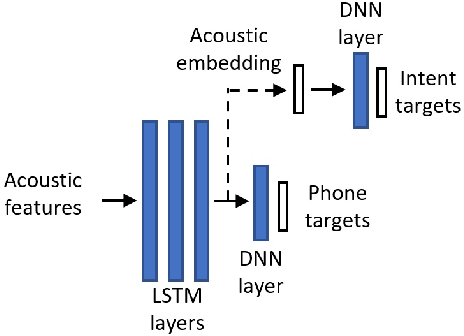

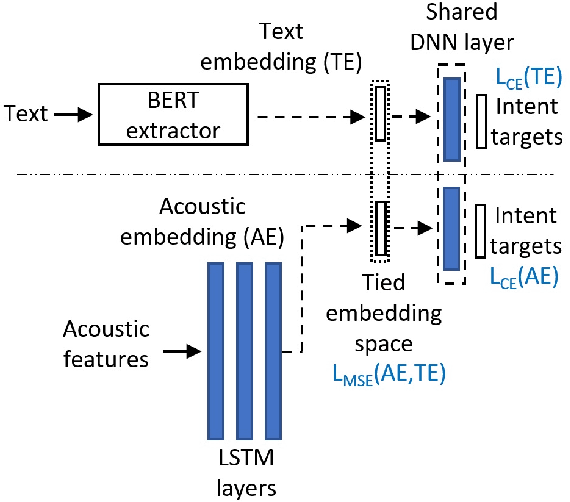
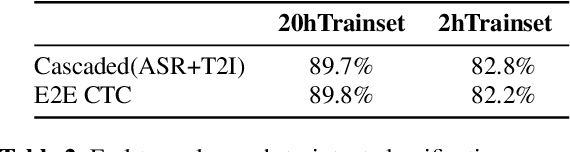
Training an end-to-end (E2E) neural network speech-to-intent (S2I) system that directly extracts intents from speech requires large amounts of intent-labeled speech data, which is time consuming and expensive to collect. Initializing the S2I model with an ASR model trained on copious speech data can alleviate data sparsity. In this paper, we attempt to leverage NLU text resources. We implemented a CTC-based S2I system that matches the performance of a state-of-the-art, traditional cascaded SLU system. We performed controlled experiments with varying amounts of speech and text training data. When only a tenth of the original data is available, intent classification accuracy degrades by 7.6% absolute. Assuming we have additional text-to-intent data (without speech) available, we investigated two techniques to improve the S2I system: (1) transfer learning, in which acoustic embeddings for intent classification are tied to fine-tuned BERT text embeddings; and (2) data augmentation, in which the text-to-intent data is converted into speech-to-intent data using a multi-speaker text-to-speech system. The proposed approaches recover 80% of performance lost due to using limited intent-labeled speech.
A Recorded Debating Dataset
Mar 27, 2018
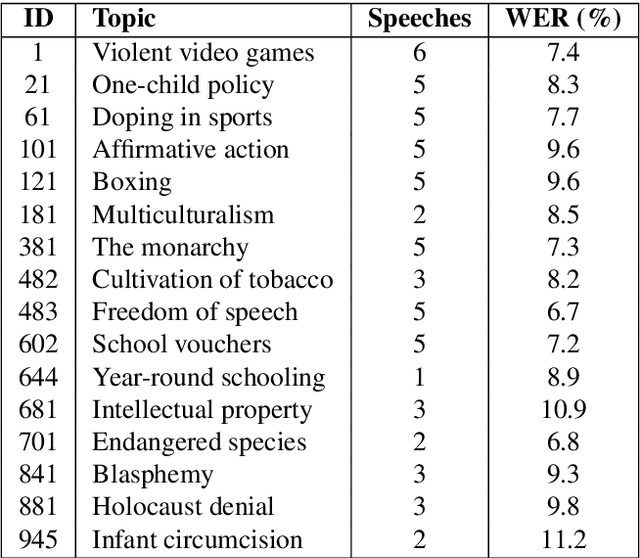
This paper describes an English audio and textual dataset of debating speeches, a unique resource for the growing research field of computational argumentation and debating technologies. We detail the process of speech recording by professional debaters, the transcription of the speeches with an Automatic Speech Recognition (ASR) system, their consequent automatic processing to produce a text that is more "NLP-friendly", and in parallel -- the manual transcription of the speeches in order to produce gold-standard "reference" transcripts. We release 60 speeches on various controversial topics, each in five formats corresponding to the different stages in the production of the data. The intention is to allow utilizing this resource for multiple research purposes, be it the addition of in-domain training data for a debate-specific ASR system, or applying argumentation mining on either noisy or clean debate transcripts. We intend to make further releases of this data in the future.