 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGeneral Agent Evaluation
Feb 26, 2026The promise of general-purpose agents - systems that perform tasks in unfamiliar environments without domain-specific engineering - remains largely unrealized. Existing agents are predominantly specialized, and while emerging implementations like OpenAI SDK Agent and Claude Code hint at broader capabilities, no systematic evaluation of their general performance has been pursued. Current agentic benchmarks assume domain-specific integration, encoding task information in ways that preclude fair evaluation of general agents. This paper frames general-agent evaluation as a first-class research objective. We propose conceptual principles for such evaluation, a Unified Protocol enabling agent-benchmark integration, and Exgentic - a practical framework for general agent evaluation. We benchmark five prominent agent implementations across six environments as the first Open General Agent Leaderboard. Our experiments show that general agents generalize across diverse environments, achieving performance comparable to domain-specific agents without any environment-specific tuning. We release our evaluation protocol, framework, and leaderboard to establish a foundation for systematic research on general-purpose agents.
Out of the Echo Chamber: Detecting Countering Debate Speeches
May 03, 2020

An educated and informed consumption of media content has become a challenge in modern times. With the shift from traditional news outlets to social media and similar venues, a major concern is that readers are becoming encapsulated in "echo chambers" and may fall prey to fake news and disinformation, lacking easy access to dissenting views. We suggest a novel task aiming to alleviate some of these concerns -- that of detecting articles that most effectively counter the arguments -- and not just the stance -- made in a given text. We study this problem in the context of debate speeches. Given such a speech, we aim to identify, from among a set of speeches on the same topic and with an opposing stance, the ones that directly counter it. We provide a large dataset of 3,685 such speeches (in English), annotated for this relation, which hopefully would be of general interest to the NLP community. We explore several algorithms addressing this task, and while some are successful, all fall short of expert human performance, suggesting room for further research. All data collected during this work is freely available for research.
Automatic Argument Quality Assessment -- New Datasets and Methods
Sep 03, 2019
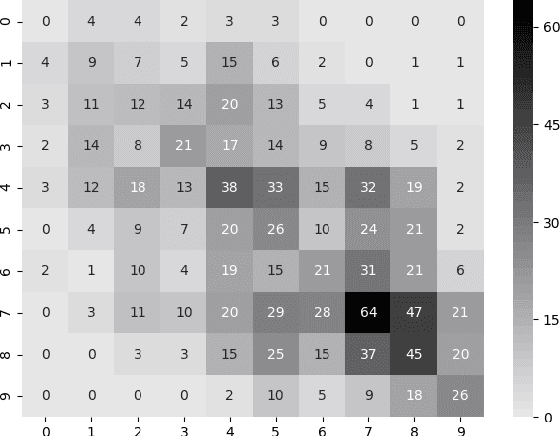
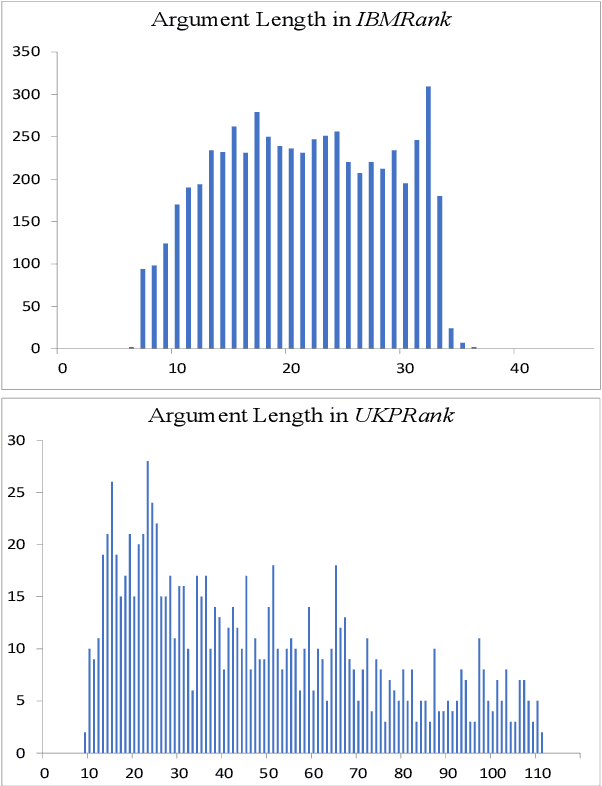
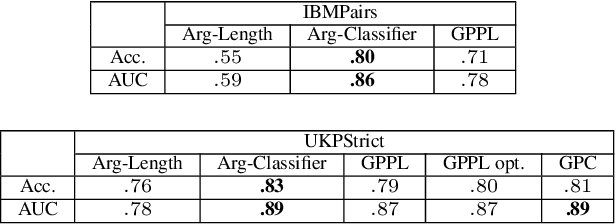
We explore the task of automatic assessment of argument quality. To that end, we actively collected 6.3k arguments, more than a factor of five compared to previously examined data. Each argument was explicitly and carefully annotated for its quality. In addition, 14k pairs of arguments were annotated independently, identifying the higher quality argument in each pair. In spite of the inherent subjective nature of the task, both annotation schemes led to surprisingly consistent results. We release the labeled datasets to the community. Furthermore, we suggest neural methods based on a recently released language model, for argument ranking as well as for argument-pair classification. In the former task, our results are comparable to state-of-the-art; in the latter task our results significantly outperform earlier methods.
A Dataset of General-Purpose Rebuttal
Sep 01, 2019
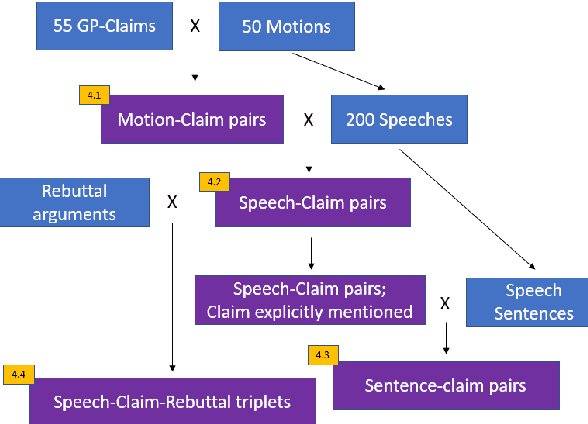
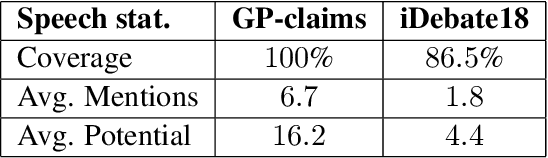
In Natural Language Understanding, the task of response generation is usually focused on responses to short texts, such as tweets or a turn in a dialog. Here we present a novel task of producing a critical response to a long argumentative text, and suggest a method based on general rebuttal arguments to address it. We do this in the context of the recently-suggested task of listening comprehension over argumentative content: given a speech on some specified topic, and a list of relevant arguments, the goal is to determine which of the arguments appear in the speech. The general rebuttals we describe here (written in English) overcome the need for topic-specific arguments to be provided, by proving to be applicable for a large set of topics. This allows creating responses beyond the scope of topics for which specific arguments are available. All data collected during this work is freely available for research.
Towards Effective Rebuttal: Listening Comprehension using Corpus-Wide Claim Mining
Jul 27, 2019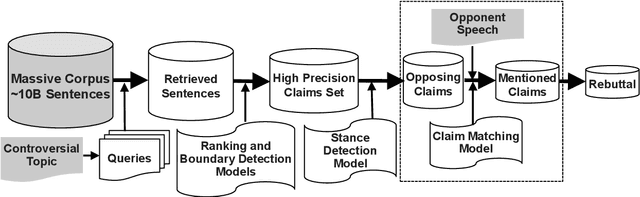
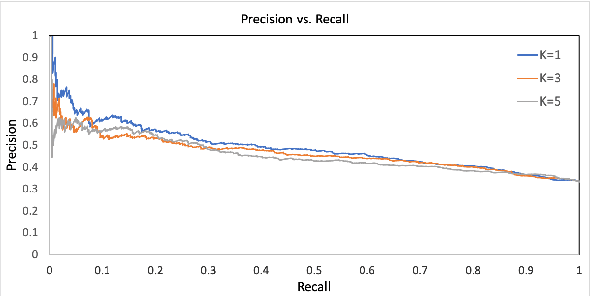
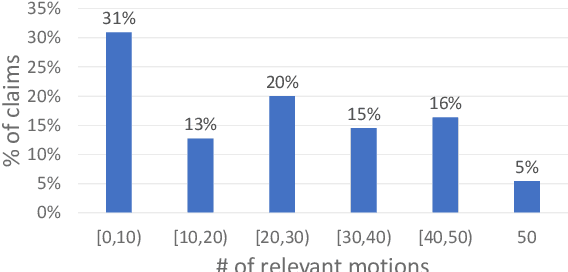
Engaging in a live debate requires, among other things, the ability to effectively rebut arguments claimed by your opponent. In particular, this requires identifying these arguments. Here, we suggest doing so by automatically mining claims from a corpus of news articles containing billions of sentences, and searching for them in a given speech. This raises the question of whether such claims indeed correspond to those made in spoken speeches. To this end, we collected a large dataset of $400$ speeches in English discussing $200$ controversial topics, mined claims for each topic, and asked annotators to identify the mined claims mentioned in each speech. Results show that in the vast majority of speeches debaters indeed make use of such claims. In addition, we present several baselines for the automatic detection of mined claims in speeches, forming the basis for future work. All collected data is freely available for research.
A Recorded Debating Dataset
Mar 27, 2018
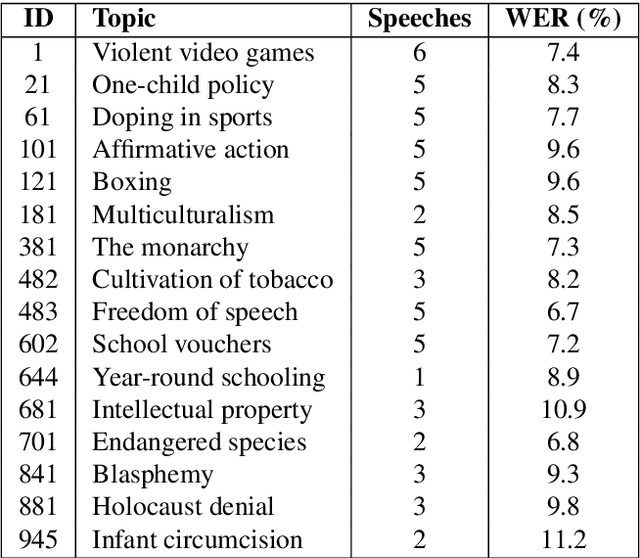
This paper describes an English audio and textual dataset of debating speeches, a unique resource for the growing research field of computational argumentation and debating technologies. We detail the process of speech recording by professional debaters, the transcription of the speeches with an Automatic Speech Recognition (ASR) system, their consequent automatic processing to produce a text that is more "NLP-friendly", and in parallel -- the manual transcription of the speeches in order to produce gold-standard "reference" transcripts. We release 60 speeches on various controversial topics, each in five formats corresponding to the different stages in the production of the data. The intention is to allow utilizing this resource for multiple research purposes, be it the addition of in-domain training data for a debate-specific ASR system, or applying argumentation mining on either noisy or clean debate transcripts. We intend to make further releases of this data in the future.