 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAll Languages Matter: Evaluating LMMs on Culturally Diverse 100 Languages
Nov 25, 2024



Existing Large Multimodal Models (LMMs) generally focus on only a few regions and languages. As LMMs continue to improve, it is increasingly important to ensure they understand cultural contexts, respect local sensitivities, and support low-resource languages, all while effectively integrating corresponding visual cues. In pursuit of culturally diverse global multimodal models, our proposed All Languages Matter Benchmark (ALM-bench) represents the largest and most comprehensive effort to date for evaluating LMMs across 100 languages. ALM-bench challenges existing models by testing their ability to understand and reason about culturally diverse images paired with text in various languages, including many low-resource languages traditionally underrepresented in LMM research. The benchmark offers a robust and nuanced evaluation framework featuring various question formats, including true/false, multiple choice, and open-ended questions, which are further divided into short and long-answer categories. ALM-bench design ensures a comprehensive assessment of a model's ability to handle varied levels of difficulty in visual and linguistic reasoning. To capture the rich tapestry of global cultures, ALM-bench carefully curates content from 13 distinct cultural aspects, ranging from traditions and rituals to famous personalities and celebrations. Through this, ALM-bench not only provides a rigorous testing ground for state-of-the-art open and closed-source LMMs but also highlights the importance of cultural and linguistic inclusivity, encouraging the development of models that can serve diverse global populations effectively. Our benchmark is publicly available.
A Dataset of General-Purpose Rebuttal
Sep 01, 2019
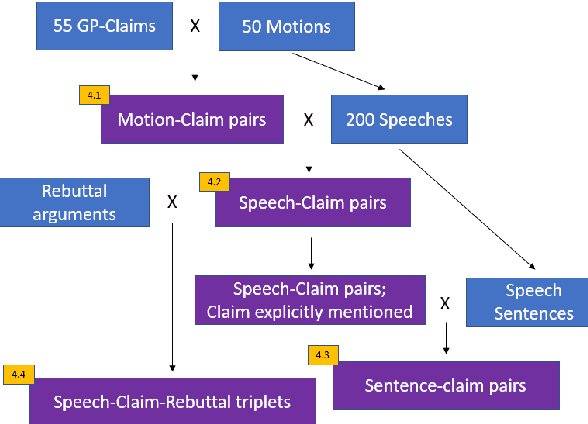
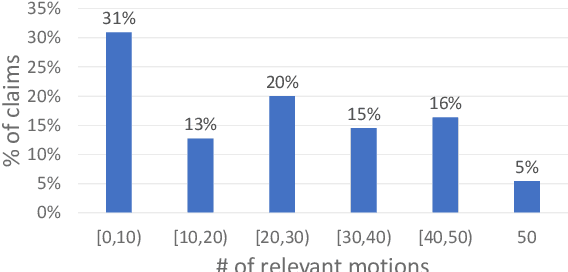
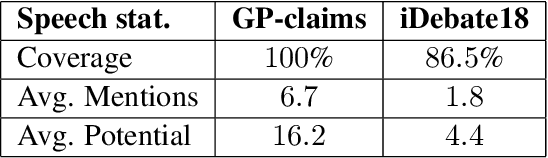
In Natural Language Understanding, the task of response generation is usually focused on responses to short texts, such as tweets or a turn in a dialog. Here we present a novel task of producing a critical response to a long argumentative text, and suggest a method based on general rebuttal arguments to address it. We do this in the context of the recently-suggested task of listening comprehension over argumentative content: given a speech on some specified topic, and a list of relevant arguments, the goal is to determine which of the arguments appear in the speech. The general rebuttals we describe here (written in English) overcome the need for topic-specific arguments to be provided, by proving to be applicable for a large set of topics. This allows creating responses beyond the scope of topics for which specific arguments are available. All data collected during this work is freely available for research.
Towards Effective Rebuttal: Listening Comprehension using Corpus-Wide Claim Mining
Jul 27, 2019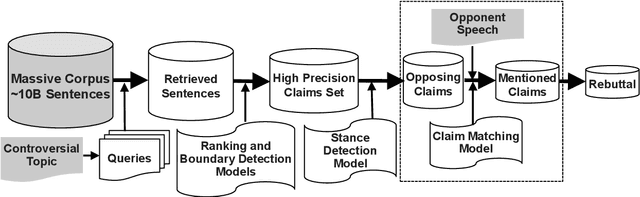
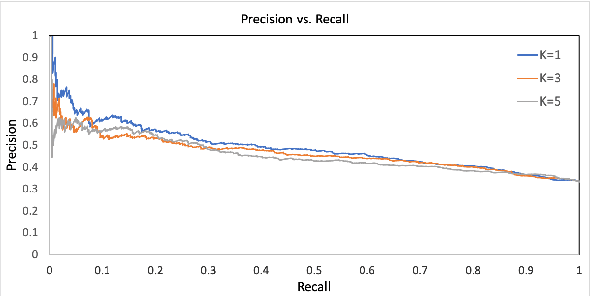
Engaging in a live debate requires, among other things, the ability to effectively rebut arguments claimed by your opponent. In particular, this requires identifying these arguments. Here, we suggest doing so by automatically mining claims from a corpus of news articles containing billions of sentences, and searching for them in a given speech. This raises the question of whether such claims indeed correspond to those made in spoken speeches. To this end, we collected a large dataset of $400$ speeches in English discussing $200$ controversial topics, mined claims for each topic, and asked annotators to identify the mined claims mentioned in each speech. Results show that in the vast majority of speeches debaters indeed make use of such claims. In addition, we present several baselines for the automatic detection of mined claims in speeches, forming the basis for future work. All collected data is freely available for research.
A Recorded Debating Dataset
Mar 27, 2018
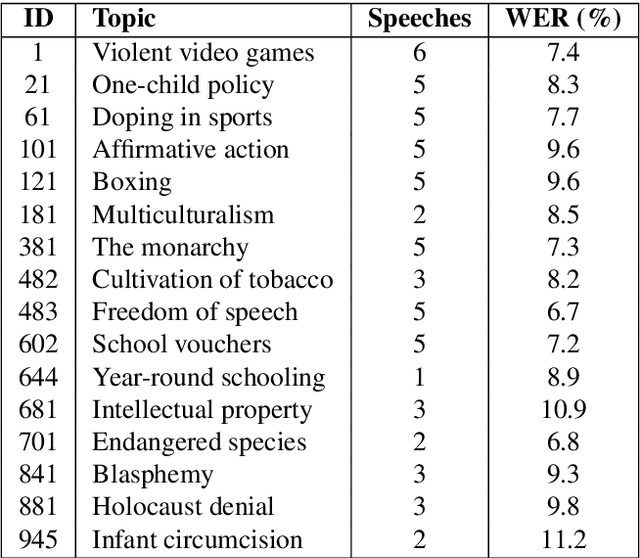
This paper describes an English audio and textual dataset of debating speeches, a unique resource for the growing research field of computational argumentation and debating technologies. We detail the process of speech recording by professional debaters, the transcription of the speeches with an Automatic Speech Recognition (ASR) system, their consequent automatic processing to produce a text that is more "NLP-friendly", and in parallel -- the manual transcription of the speeches in order to produce gold-standard "reference" transcripts. We release 60 speeches on various controversial topics, each in five formats corresponding to the different stages in the production of the data. The intention is to allow utilizing this resource for multiple research purposes, be it the addition of in-domain training data for a debate-specific ASR system, or applying argumentation mining on either noisy or clean debate transcripts. We intend to make further releases of this data in the future.
What did you Mention? A Large Scale Mention Detection Benchmark for Spoken and Written Text
Jan 25, 2018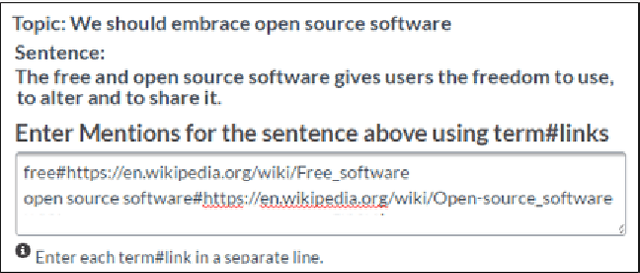
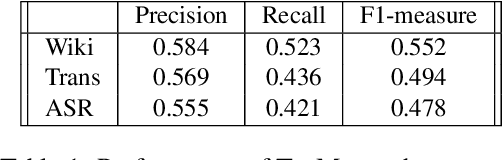
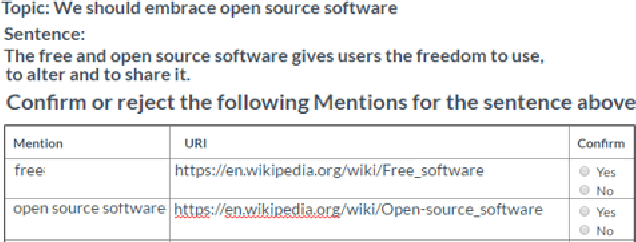
We describe a large, high-quality benchmark for the evaluation of Mention Detection tools. The benchmark contains annotations of both named entities as well as other types of entities, annotated on different types of text, ranging from clean text taken from Wikipedia, to noisy spoken data. The benchmark was built through a highly controlled crowd sourcing process to ensure its quality. We describe the benchmark, the process and the guidelines that were used to build it. We then demonstrate the results of a state-of-the-art system running on that benchmark.
Joint Learning of Correlated Sequence Labelling Tasks Using Bidirectional Recurrent Neural Networks
Jul 18, 2017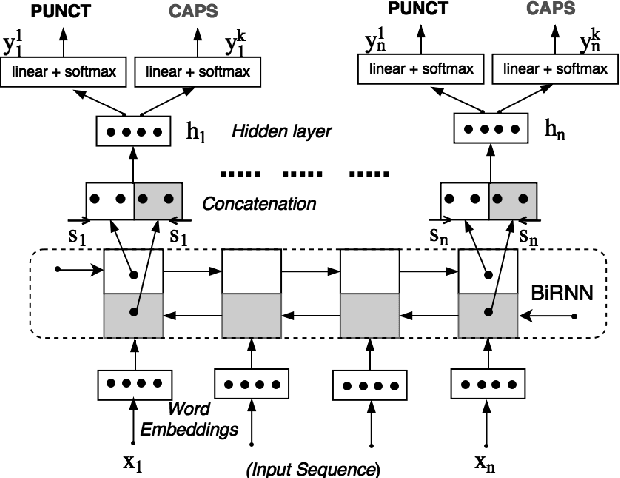
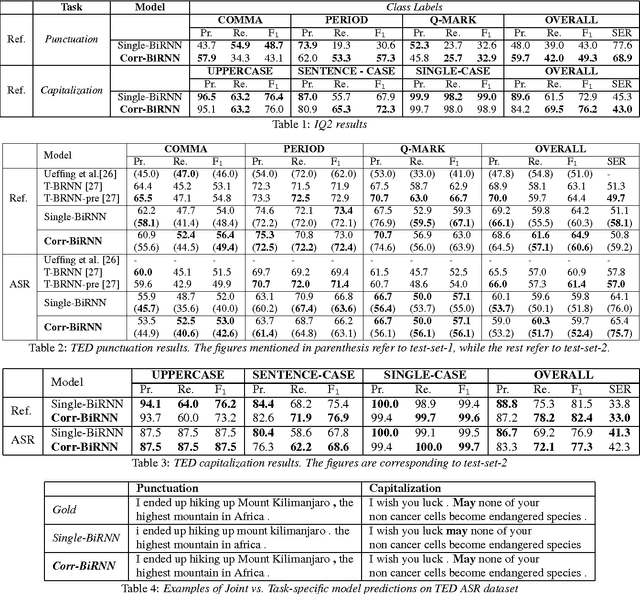
The stream of words produced by Automatic Speech Recognition (ASR) systems is typically devoid of punctuations and formatting. Most natural language processing applications expect segmented and well-formatted texts as input, which is not available in ASR output. This paper proposes a novel technique of jointly modeling multiple correlated tasks such as punctuation and capitalization using bidirectional recurrent neural networks, which leads to improved performance for each of these tasks. This method could be extended for joint modeling of any other correlated sequence labeling tasks.
Personalized Machine Translation: Preserving Original Author Traits
Jan 12, 2017
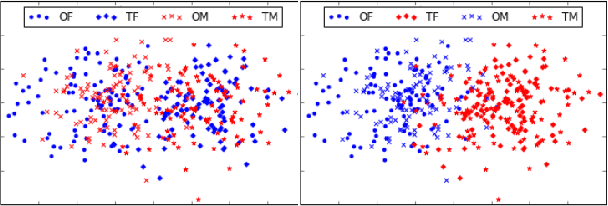
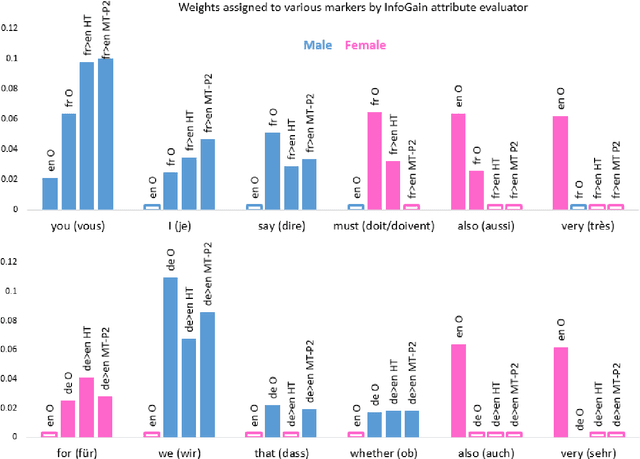
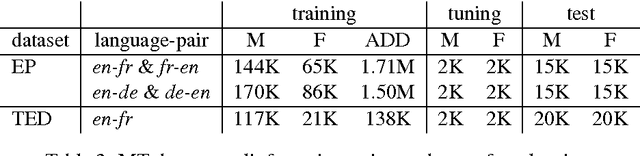
The language that we produce reflects our personality, and various personal and demographic characteristics can be detected in natural language texts. We focus on one particular personal trait of the author, gender, and study how it is manifested in original texts and in translations. We show that author's gender has a powerful, clear signal in originals texts, but this signal is obfuscated in human and machine translation. We then propose simple domain-adaptation techniques that help retain the original gender traits in the translation, without harming the quality of the translation, thereby creating more personalized machine translation systems.