 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStrategies of Code-switching in Human-Machine Dialogs
Aug 10, 2025Most people are multilingual, and most multilinguals code-switch, yet the characteristics of code-switched language are not fully understood. We developed a chatbot capable of completing a Map Task with human participants using code-switched Spanish and English. In two experiments, we prompted the bot to code-switch according to different strategies, examining (1) the feasibility of such experiments for investigating bilingual language use, and (2) whether participants would be sensitive to variations in discourse and grammatical patterns. Participants generally enjoyed code-switching with our bot as long as it produced predictable code-switching behavior; when code-switching was random or ungrammatical (as when producing unattested incongruent mixed-language noun phrases, such as `la fork'), participants enjoyed the task less and were less successful at completing it. These results underscore the potential downsides of deploying insufficiently developed multilingual language technology, while also illustrating the promise of such technology for conducting research on bilingual language use.
Knesset-DictaBERT: A Hebrew Language Model for Parliamentary Proceedings
Jul 30, 2024
We present Knesset-DictaBERT, a large Hebrew language model fine-tuned on the Knesset Corpus, which comprises Israeli parliamentary proceedings. The model is based on the DictaBERT architecture and demonstrates significant improvements in understanding parliamentary language according to the MLM task. We provide a detailed evaluation of the model's performance, showing improvements in perplexity and accuracy over the baseline DictaBERT model.
The Knesset Corpus: An Annotated Corpus of Hebrew Parliamentary Proceedings
May 28, 2024We present the Knesset Corpus, a corpus of Hebrew parliamentary proceedings containing over 30 million sentences (over 384 million tokens) from all the (plenary and committee) protocols held in the Israeli parliament between 1998 and 2022. Sentences are annotated with morpho-syntactic information and are associated with detailed meta-information reflecting demographic and political properties of the speakers, based on a large database of parliament members and factions that we compiled. We discuss the structure and composition of the corpus and the various processing steps we applied to it. To demonstrate the utility of this novel dataset we present two use cases. We show that the corpus can be used to examine historical developments in the style of political discussions by showing a reduction in lexical richness in the proceedings over time. We also investigate some differences between the styles of men and women speakers. These use cases exemplify the potential of the corpus to shed light on important trends in the Israeli society, supporting research in linguistics, political science, communication, law, etc.
Shared Lexical Items as Triggers of Code Switching
Aug 29, 2023Why do bilingual speakers code-switch (mix their two languages)? Among the several theories that attempt to explain this natural and ubiquitous phenomenon, the Triggering Hypothesis relates code-switching to the presence of lexical triggers, specifically cognates and proper names, adjacent to the switch point. We provide a fuller, more nuanced and refined exploration of the triggering hypothesis, based on five large datasets in three language pairs, reflecting both spoken and written bilingual interactions. Our results show that words that are assumed to reside in a mental lexicon shared by both languages indeed trigger code-switching; that the tendency to switch depends on the distance of the trigger from the switch point; and on whether the trigger precedes or succeeds the switch; but not on the etymology of the trigger words. We thus provide strong, robust, evidence-based confirmation to several hypotheses on the relationships between lexical triggers and code-switching.
Speaker Information Can Guide Models to Better Inductive Biases: A Case Study On Predicting Code-Switching
Mar 16, 2022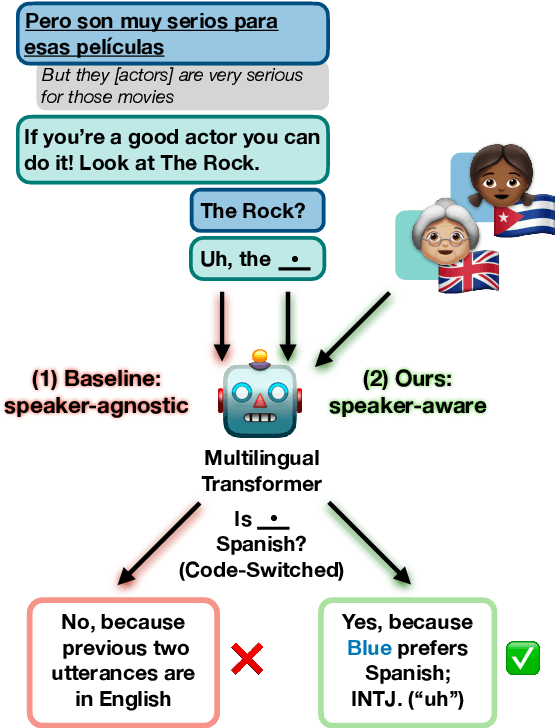

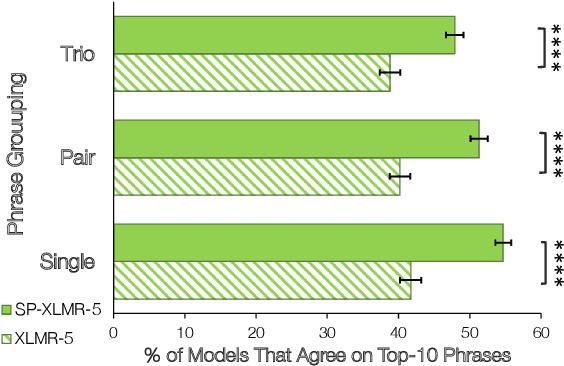
Natural language processing (NLP) models trained on people-generated data can be unreliable because, without any constraints, they can learn from spurious correlations that are not relevant to the task. We hypothesize that enriching models with speaker information in a controlled, educated way can guide them to pick up on relevant inductive biases. For the speaker-driven task of predicting code-switching points in English--Spanish bilingual dialogues, we show that adding sociolinguistically-grounded speaker features as prepended prompts significantly improves accuracy. We find that by adding influential phrases to the input, speaker-informed models learn useful and explainable linguistic information. To our knowledge, we are the first to incorporate speaker characteristics in a neural model for code-switching, and more generally, take a step towards developing transparent, personalized models that use speaker information in a controlled way.
Machine Translation into Low-resource Language Varieties
Jun 12, 2021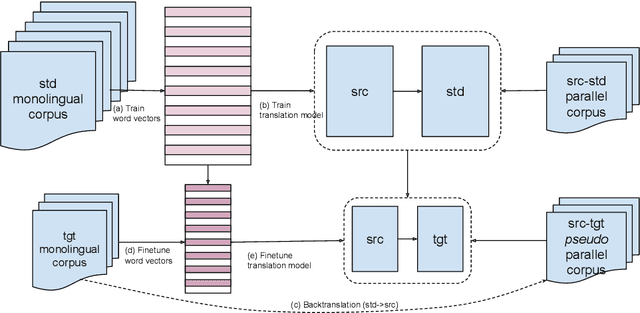
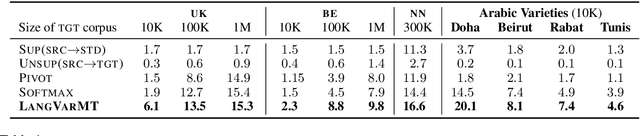


State-of-the-art machine translation (MT) systems are typically trained to generate the "standard" target language; however, many languages have multiple varieties (regional varieties, dialects, sociolects, non-native varieties) that are different from the standard language. Such varieties are often low-resource, and hence do not benefit from contemporary NLP solutions, MT included. We propose a general framework to rapidly adapt MT systems to generate language varieties that are close to, but different from, the standard target language, using no parallel (source--variety) data. This also includes adaptation of MT systems to low-resource typologically-related target languages. We experiment with adapting an English--Russian MT system to generate Ukrainian and Belarusian, an English--Norwegian Bokm{\aa}l system to generate Nynorsk, and an English--Arabic system to generate four Arabic dialects, obtaining significant improvements over competitive baselines.
Topics to Avoid: Demoting Latent Confounds in Text Classification
Sep 01, 2019

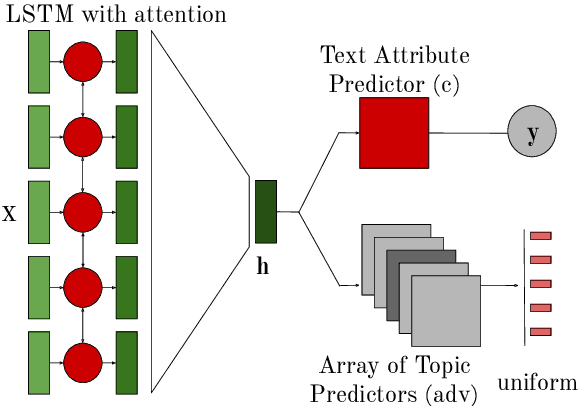

Despite impressive performance on many text classification tasks, deep neural networks tend to learn frequent superficial patterns that are specific to the training data and do not always generalize well. In this work, we observe this limitation with respect to the task of native language identification. We find that standard text classifiers which perform well on the test set end up learning topical features which are confounds of the prediction task (e.g., if the input text mentions Sweden, the classifier predicts that the author's native language is Swedish). We propose a method that represents the latent topical confounds and a model which "unlearns" confounding features by predicting both the label of the input text and the confound; but we train the two predictors adversarially in an alternating fashion to learn a text representation that predicts the correct label but is less prone to using information about the confound. We show that this model generalizes better and learns features that are indicative of the writing style rather than the content.
Framing and Agenda-setting in Russian News: a Computational Analysis of Intricate Political Strategies
Oct 29, 2018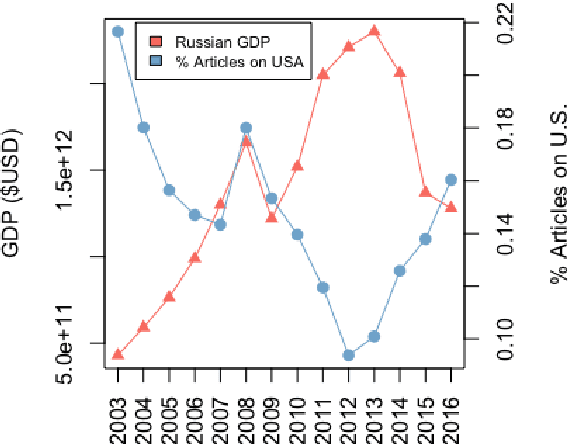
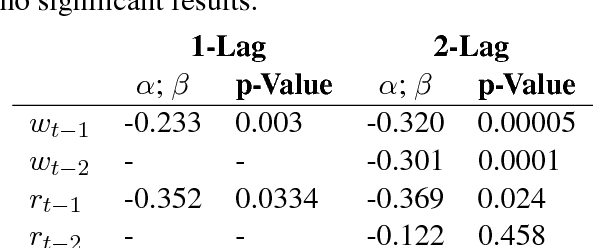

Amidst growing concern over media manipulation, NLP attention has focused on overt strategies like censorship and "fake news'". Here, we draw on two concepts from the political science literature to explore subtler strategies for government media manipulation: agenda-setting (selecting what topics to cover) and framing (deciding how topics are covered). We analyze 13 years (100K articles) of the Russian newspaper Izvestia and identify a strategy of distraction: articles mention the U.S. more frequently in the month directly following an economic downturn in Russia. We introduce embedding-based methods for cross-lingually projecting English frames to Russian, and discover that these articles emphasize U.S. moral failings and threats to the U.S. Our work offers new ways to identify subtle media manipulation strategies at the intersection of agenda-setting and framing.
Native Language Cognate Effects on Second Language Lexical Choice
May 24, 2018We present a computational analysis of cognate effects on the spontaneous linguistic productions of advanced non-native speakers. Introducing a large corpus of highly competent non-native English speakers, and using a set of carefully selected lexical items, we show that the lexical choices of non-natives are affected by cognates in their native language. This effect is so powerful that we are able to reconstruct the phylogenetic language tree of the Indo-European language family solely from the frequencies of specific lexical items in the English of authors with various native languages. We quantitatively analyze non-native lexical choice, highlighting cognate facilitation as one of the important phenomena shaping the language of non-native speakers.
The UN Parallel Corpus Annotated for Translation Direction
May 20, 2018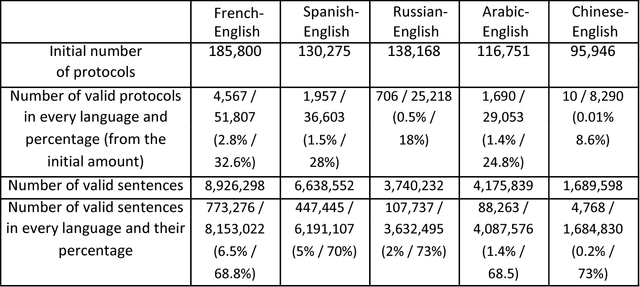
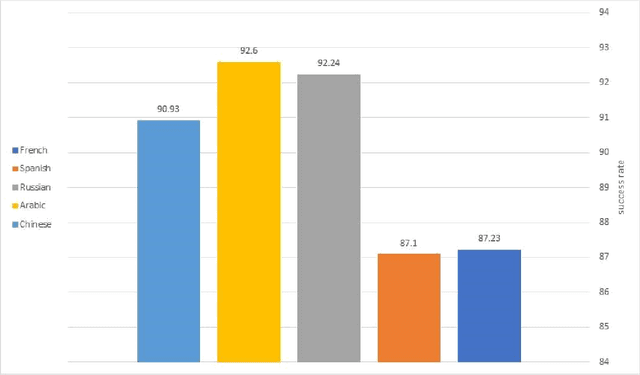
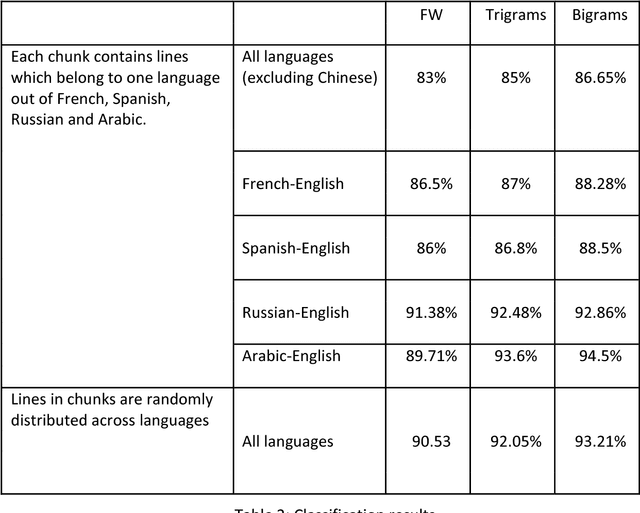

This work distinguishes between translated and original text in the UN protocol corpus. By modeling the problem as classification problem, we can achieve up to 95% classification accuracy. We begin by deriving a parallel corpus for different language-pairs annotated for translation direction, and then classify the data by using various feature extraction methods. We compare the different methods as well as the ability to distinguish between translated and original texts in the different languages. The annotated corpus is publicly available.