 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvaluating Grounded Reasoning by Code-Assisted Large Language Models for Mathematics
Apr 24, 2025Assisting LLMs with code generation improved their performance on mathematical reasoning tasks. However, the evaluation of code-assisted LLMs is generally restricted to execution correctness, lacking a rigorous evaluation of their generated programs. In this work, we bridge this gap by conducting an in-depth analysis of code-assisted LLMs' generated programs in response to math reasoning tasks. Our evaluation focuses on the extent to which LLMs ground their programs to math rules, and how that affects their end performance. For this purpose, we assess the generations of five different LLMs, on two different math datasets, both manually and automatically. Our results reveal that the distribution of grounding depends on LLMs' capabilities and the difficulty of math problems. Furthermore, mathematical grounding is more effective for closed-source models, while open-source models fail to employ math rules in their solutions correctly. On MATH500, the percentage of grounded programs decreased to half, while the ungrounded generations doubled in comparison to ASDiv grade-school problems. Our work highlights the need for in-depth evaluation beyond execution accuracy metrics, toward a better understanding of code-assisted LLMs' capabilities and limits in the math domain.
The Knesset Corpus: An Annotated Corpus of Hebrew Parliamentary Proceedings
May 28, 2024We present the Knesset Corpus, a corpus of Hebrew parliamentary proceedings containing over 30 million sentences (over 384 million tokens) from all the (plenary and committee) protocols held in the Israeli parliament between 1998 and 2022. Sentences are annotated with morpho-syntactic information and are associated with detailed meta-information reflecting demographic and political properties of the speakers, based on a large database of parliament members and factions that we compiled. We discuss the structure and composition of the corpus and the various processing steps we applied to it. To demonstrate the utility of this novel dataset we present two use cases. We show that the corpus can be used to examine historical developments in the style of political discussions by showing a reduction in lexical richness in the proceedings over time. We also investigate some differences between the styles of men and women speakers. These use cases exemplify the potential of the corpus to shed light on important trends in the Israeli society, supporting research in linguistics, political science, communication, law, etc.
A Second Wave of UD Hebrew Treebanking and Cross-Domain Parsing
Oct 18, 2022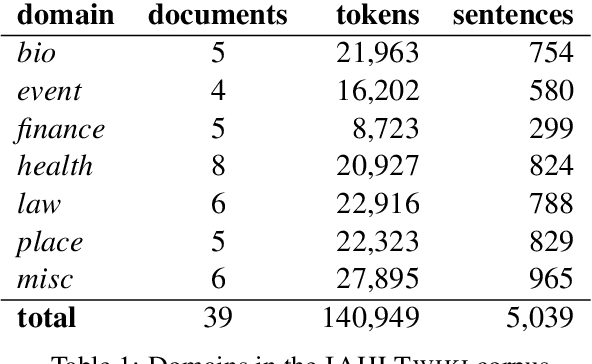
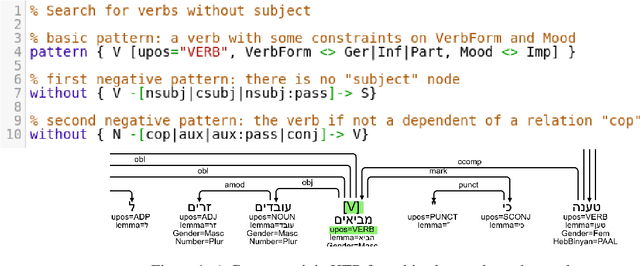
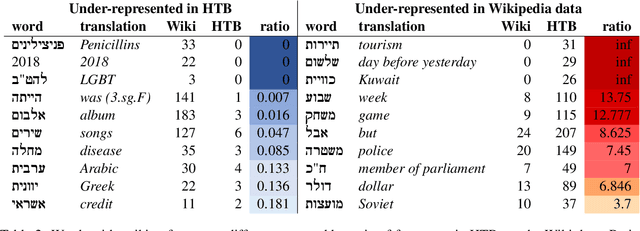
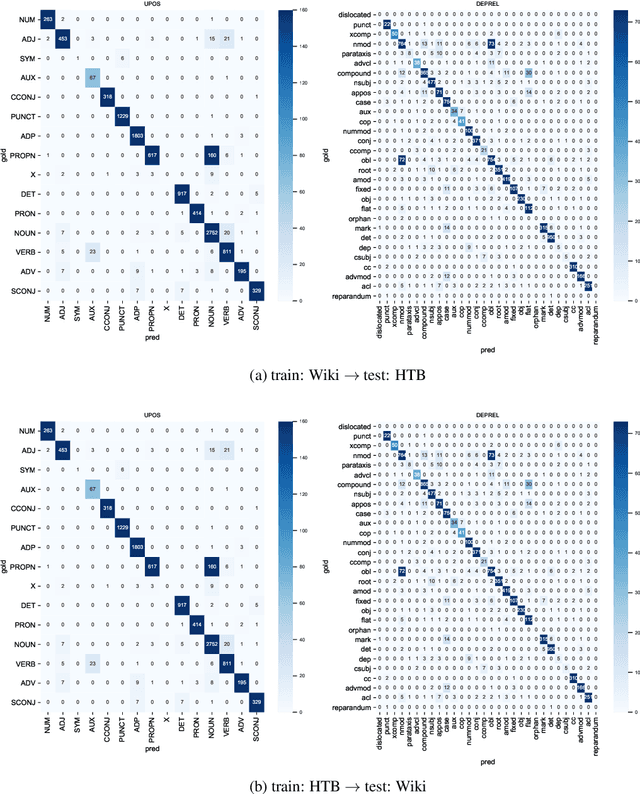
Foundational Hebrew NLP tasks such as segmentation, tagging and parsing, have relied to date on various versions of the Hebrew Treebank (HTB, Sima'an et al. 2001). However, the data in HTB, a single-source newswire corpus, is now over 30 years old, and does not cover many aspects of contemporary Hebrew on the web. This paper presents a new, freely available UD treebank of Hebrew stratified from a range of topics selected from Hebrew Wikipedia. In addition to introducing the corpus and evaluating the quality of its annotations, we deploy automatic validation tools based on grew (Guillaume, 2021), and conduct the first cross domain parsing experiments in Hebrew. We obtain new state-of-the-art (SOTA) results on UD NLP tasks, using a combination of the latest language modelling and some incremental improvements to existing transformer based approaches. We also release a new version of the UD HTB matching annotation scheme updates from our new corpus.