 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Knesset Corpus: An Annotated Corpus of Hebrew Parliamentary Proceedings
May 28, 2024We present the Knesset Corpus, a corpus of Hebrew parliamentary proceedings containing over 30 million sentences (over 384 million tokens) from all the (plenary and committee) protocols held in the Israeli parliament between 1998 and 2022. Sentences are annotated with morpho-syntactic information and are associated with detailed meta-information reflecting demographic and political properties of the speakers, based on a large database of parliament members and factions that we compiled. We discuss the structure and composition of the corpus and the various processing steps we applied to it. To demonstrate the utility of this novel dataset we present two use cases. We show that the corpus can be used to examine historical developments in the style of political discussions by showing a reduction in lexical richness in the proceedings over time. We also investigate some differences between the styles of men and women speakers. These use cases exemplify the potential of the corpus to shed light on important trends in the Israeli society, supporting research in linguistics, political science, communication, law, etc.
A Second Wave of UD Hebrew Treebanking and Cross-Domain Parsing
Oct 18, 2022
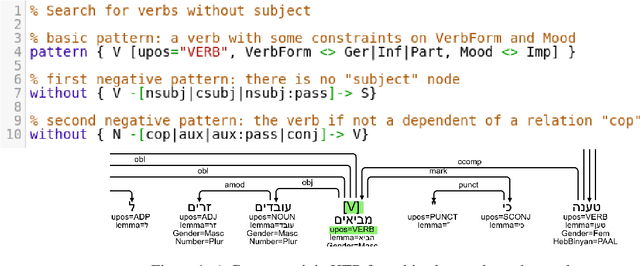
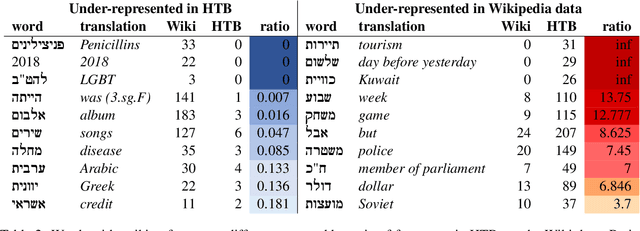
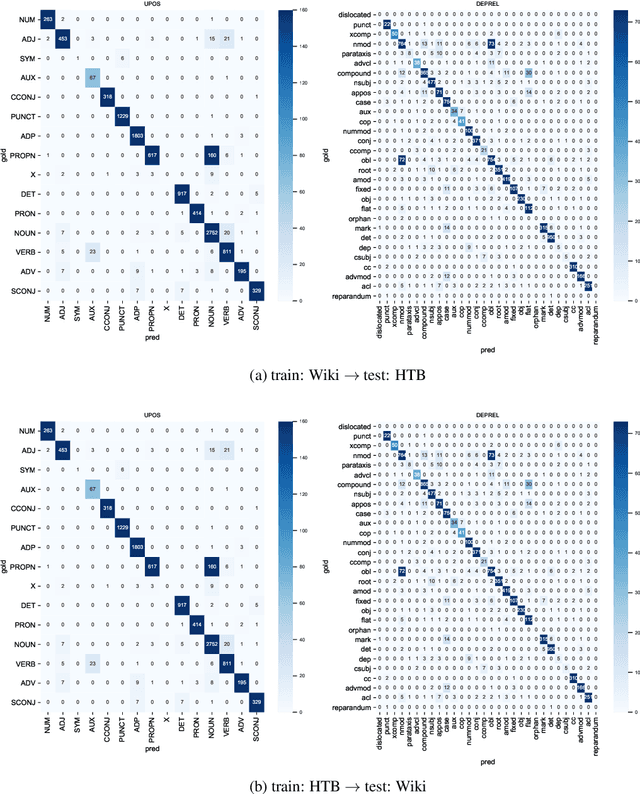
Foundational Hebrew NLP tasks such as segmentation, tagging and parsing, have relied to date on various versions of the Hebrew Treebank (HTB, Sima'an et al. 2001). However, the data in HTB, a single-source newswire corpus, is now over 30 years old, and does not cover many aspects of contemporary Hebrew on the web. This paper presents a new, freely available UD treebank of Hebrew stratified from a range of topics selected from Hebrew Wikipedia. In addition to introducing the corpus and evaluating the quality of its annotations, we deploy automatic validation tools based on grew (Guillaume, 2021), and conduct the first cross domain parsing experiments in Hebrew. We obtain new state-of-the-art (SOTA) results on UD NLP tasks, using a combination of the latest language modelling and some incremental improvements to existing transformer based approaches. We also release a new version of the UD HTB matching annotation scheme updates from our new corpus.
Found in Translation: Reconstructing Phylogenetic Language Trees from Translations
Apr 24, 2017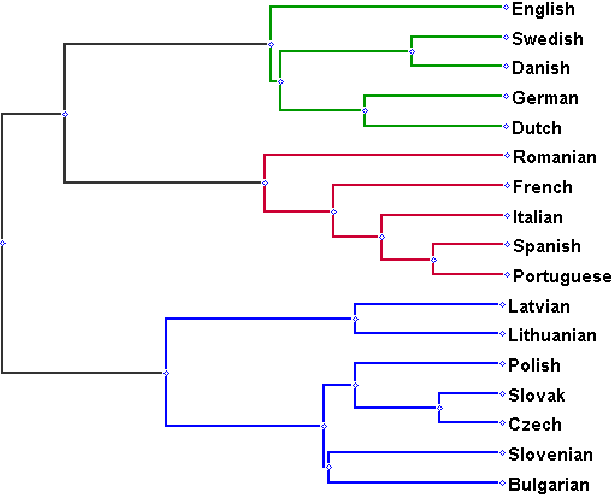

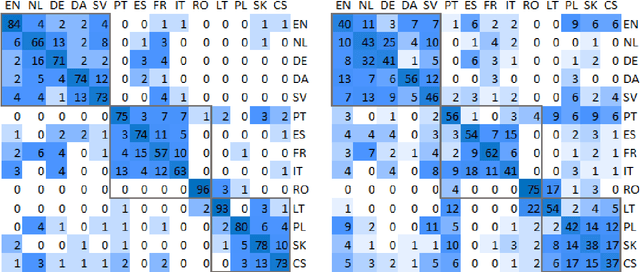
Translation has played an important role in trade, law, commerce, politics, and literature for thousands of years. Translators have always tried to be invisible; ideal translations should look as if they were written originally in the target language. We show that traces of the source language remain in the translation product to the extent that it is possible to uncover the history of the source language by looking only at the translation. Specifically, we automatically reconstruct phylogenetic language trees from monolingual texts (translated from several source languages). The signal of the source language is so powerful that it is retained even after two phases of translation. This strongly indicates that source language interference is the most dominant characteristic of translated texts, overshadowing the more subtle signals of universal properties of translation.
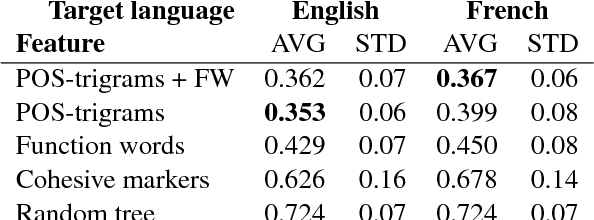
On the Similarities Between Native, Non-native and Translated Texts
Sep 11, 2016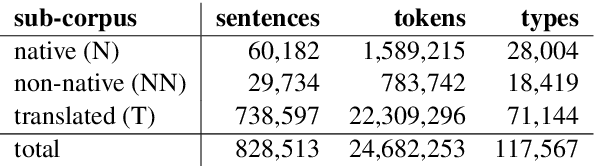
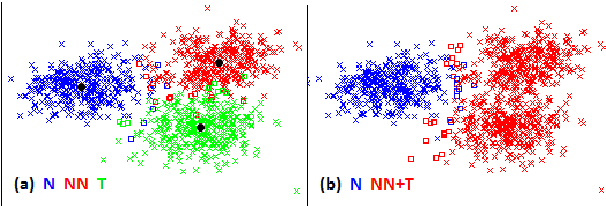
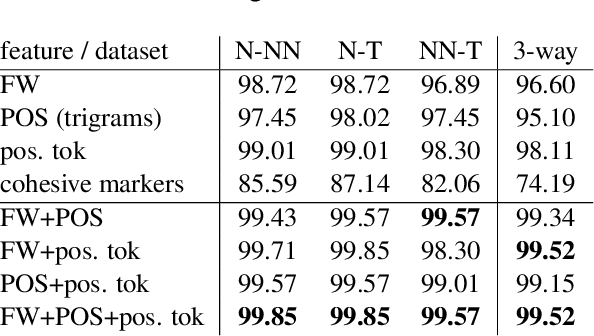
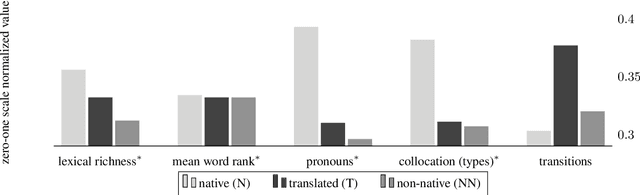
We present a computational analysis of three language varieties: native, advanced non-native, and translation. Our goal is to investigate the similarities and differences between non-native language productions and translations, contrasting both with native language. Using a collection of computational methods we establish three main results: (1) the three types of texts are easily distinguishable; (2) non-native language and translations are closer to each other than each of them is to native language; and (3) some of these characteristics depend on the source or native language, while others do not, reflecting, perhaps, unified principles that similarly affect translations and non-native language.