 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultilingual Argument Mining: Datasets and Analysis
Oct 13, 2020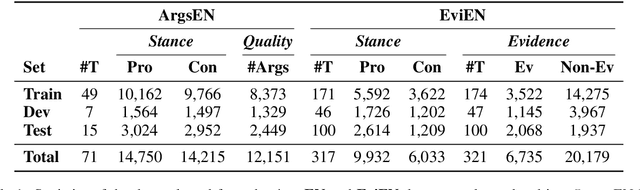
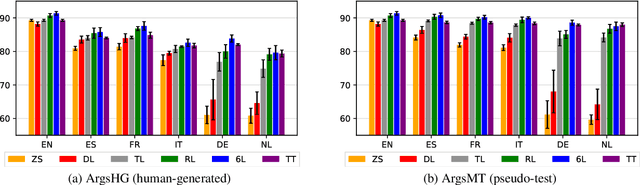
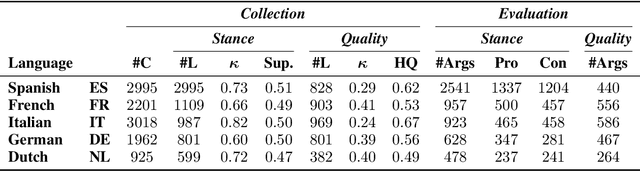
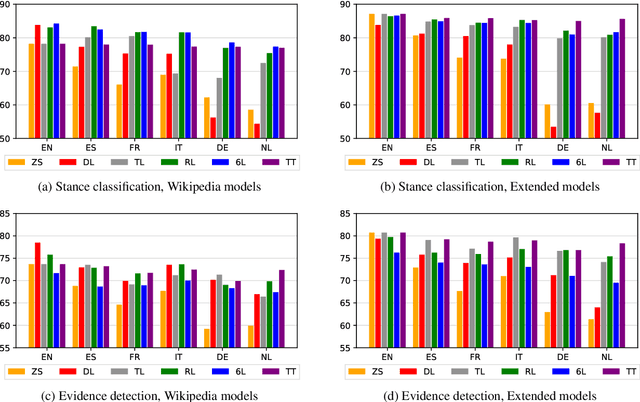
The growing interest in argument mining and computational argumentation brings with it a plethora of Natural Language Understanding (NLU) tasks and corresponding datasets. However, as with many other NLU tasks, the dominant language is English, with resources in other languages being few and far between. In this work, we explore the potential of transfer learning using the multilingual BERT model to address argument mining tasks in non-English languages, based on English datasets and the use of machine translation. We show that such methods are well suited for classifying the stance of arguments and detecting evidence, but less so for assessing the quality of arguments, presumably because quality is harder to preserve under translation. In addition, focusing on the translate-train approach, we show how the choice of languages for translation, and the relations among them, affect the accuracy of the resultant model. Finally, to facilitate evaluation of transfer learning on argument mining tasks, we provide a human-generated dataset with more than 10k arguments in multiple languages, as well as machine translation of the English datasets.
The workweek is the best time to start a family -- A Study of GPT-2 Based Claim Generation
Oct 13, 2020
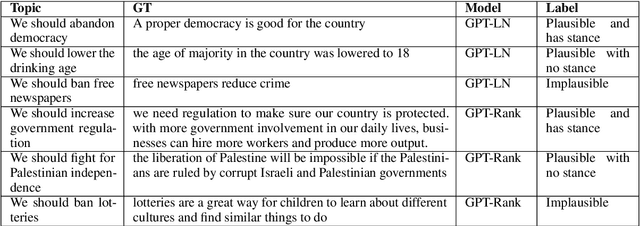


Argument generation is a challenging task whose research is timely considering its potential impact on social media and the dissemination of information. Here we suggest a pipeline based on GPT-2 for generating coherent claims, and explore the types of claims that it produces, and their veracity, using an array of manual and automatic assessments. In addition, we explore the interplay between this task and the task of Claim Retrieval, showing how they can complement one another.
What if we had no Wikipedia? Domain-independent Term Extraction from a Large News Corpus
Sep 17, 2020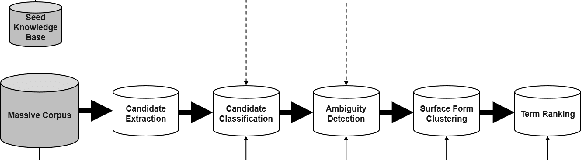
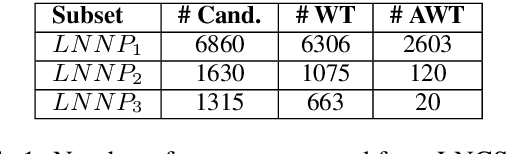
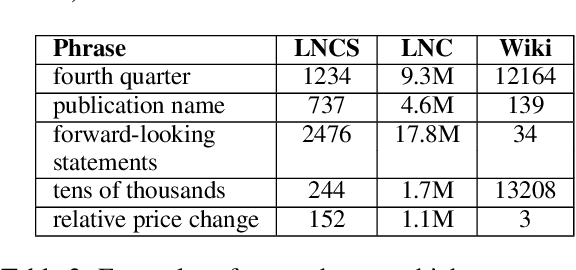
One of the most impressive human endeavors of the past two decades is the collection and categorization of human knowledge in the free and accessible format that is Wikipedia. In this work we ask what makes a term worthy of entering this edifice of knowledge, and having a page of its own in Wikipedia? To what extent is this a natural product of on-going human discourse and discussion rather than an idiosyncratic choice of Wikipedia editors? Specifically, we aim to identify such "wiki-worthy" terms in a massive news corpus, and see if this can be done with no, or minimal, dependency on actual Wikipedia entries. We suggest a five-step pipeline for doing so, providing baseline results for all five, and the relevant datasets for benchmarking them. Our work sheds new light on the domain-specific Automatic Term Extraction problem, with the problem at hand being a domain-independent variant of it.
Out of the Echo Chamber: Detecting Countering Debate Speeches
May 03, 2020
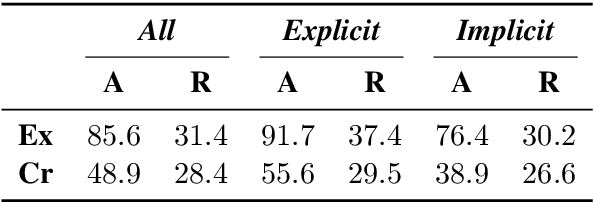
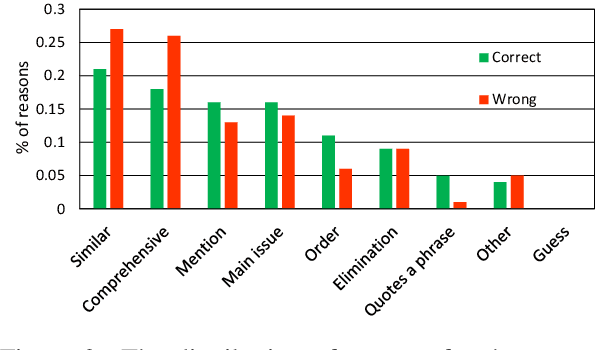

An educated and informed consumption of media content has become a challenge in modern times. With the shift from traditional news outlets to social media and similar venues, a major concern is that readers are becoming encapsulated in "echo chambers" and may fall prey to fake news and disinformation, lacking easy access to dissenting views. We suggest a novel task aiming to alleviate some of these concerns -- that of detecting articles that most effectively counter the arguments -- and not just the stance -- made in a given text. We study this problem in the context of debate speeches. Given such a speech, we aim to identify, from among a set of speeches on the same topic and with an opposing stance, the ones that directly counter it. We provide a large dataset of 3,685 such speeches (in English), annotated for this relation, which hopefully would be of general interest to the NLP community. We explore several algorithms addressing this task, and while some are successful, all fall short of expert human performance, suggesting room for further research. All data collected during this work is freely available for research.
Corpus Wide Argument Mining -- a Working Solution
Nov 25, 2019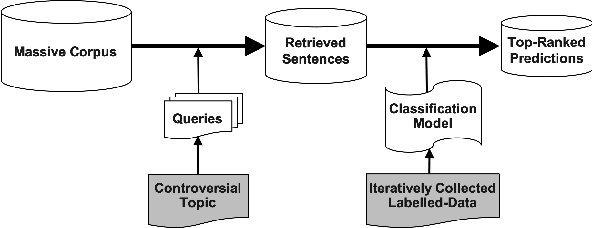
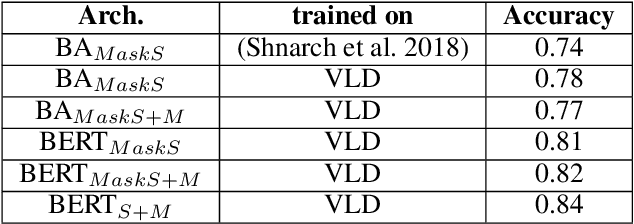
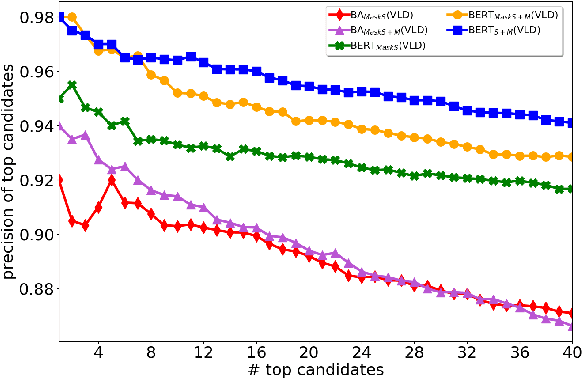
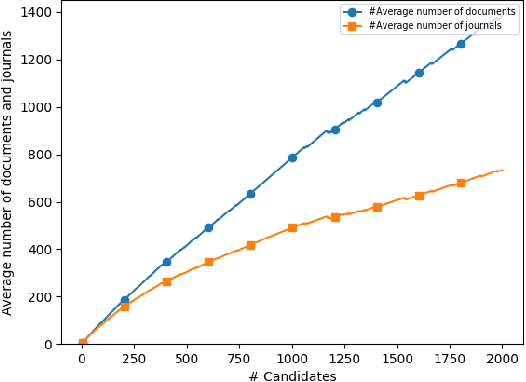
One of the main tasks in argument mining is the retrieval of argumentative content pertaining to a given topic. Most previous work addressed this task by retrieving a relatively small number of relevant documents as the initial source for such content. This line of research yielded moderate success, which is of limited use in a real-world system. Furthermore, for such a system to yield a comprehensive set of relevant arguments, over a wide range of topics, it requires leveraging a large and diverse corpus in an appropriate manner. Here we present a first end-to-end high-precision, corpus-wide argument mining system. This is made possible by combining sentence-level queries over an appropriate indexing of a very large corpus of newspaper articles, with an iterative annotation scheme. This scheme addresses the inherent label bias in the data and pinpoints the regions of the sample space whose manual labeling is required to obtain high-precision among top-ranked candidates.
A Dataset of General-Purpose Rebuttal
Sep 01, 2019
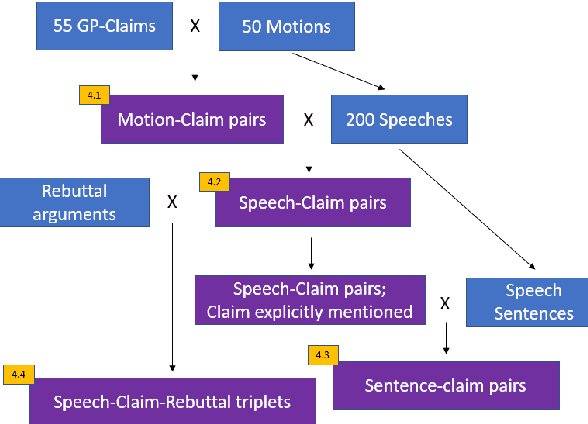
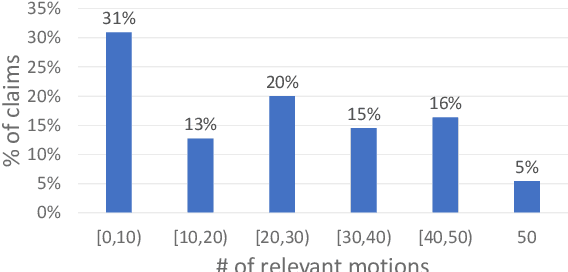
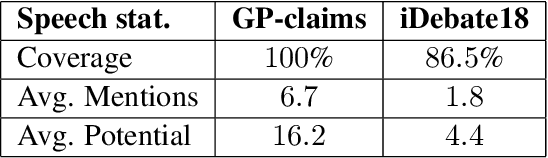
In Natural Language Understanding, the task of response generation is usually focused on responses to short texts, such as tweets or a turn in a dialog. Here we present a novel task of producing a critical response to a long argumentative text, and suggest a method based on general rebuttal arguments to address it. We do this in the context of the recently-suggested task of listening comprehension over argumentative content: given a speech on some specified topic, and a list of relevant arguments, the goal is to determine which of the arguments appear in the speech. The general rebuttals we describe here (written in English) overcome the need for topic-specific arguments to be provided, by proving to be applicable for a large set of topics. This allows creating responses beyond the scope of topics for which specific arguments are available. All data collected during this work is freely available for research.
Argument Invention from First Principles
Aug 22, 2019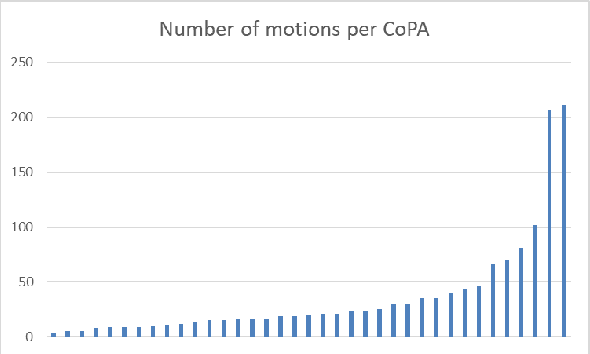


Competitive debaters often find themselves facing a challenging task -- how to debate a topic they know very little about, with only minutes to prepare, and without access to books or the Internet? What they often do is rely on "first principles", commonplace arguments which are relevant to many topics, and which they have refined in past debates. In this work we aim to explicitly define a taxonomy of such principled recurring arguments, and, given a controversial topic, to automatically identify which of these arguments are relevant to the topic. As far as we know, this is the first time that this approach to argument invention is formalized and made explicit in the context of NLP. The main goal of this work is to show that it is possible to define such a taxonomy. While the taxonomy suggested here should be thought of as a "first attempt" it is nonetheless coherent, covers well the relevant topics and coincides with what professional debaters actually argue in their speeches, and facilitates automatic argument invention for new topics.
Controversy in Context
Aug 20, 2019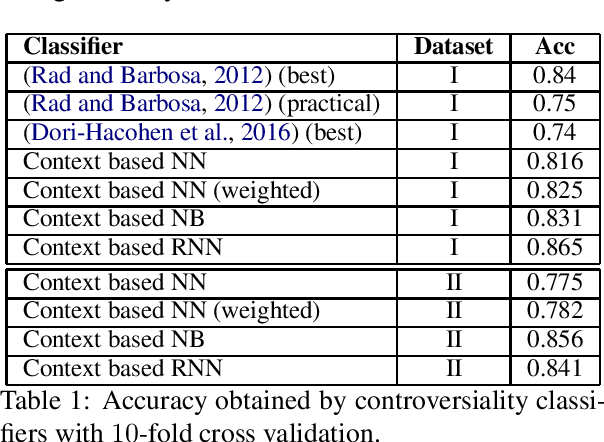
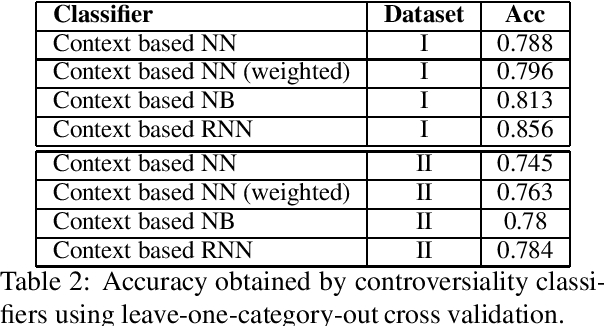
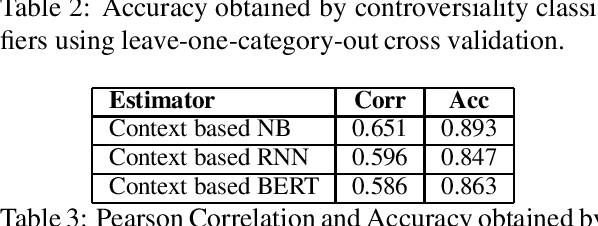
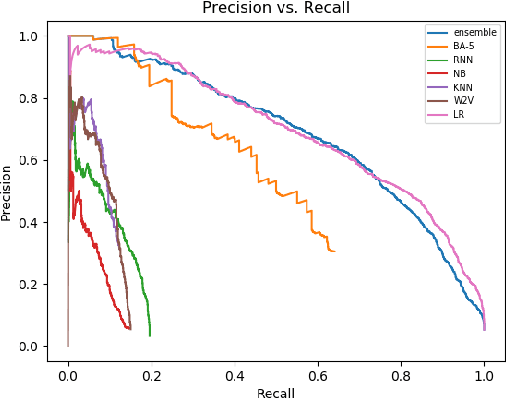
With the growing interest in social applications of Natural Language Processing and Computational Argumentation, a natural question is how controversial a given concept is. Prior works relied on Wikipedia's metadata and on content analysis of the articles pertaining to a concept in question. Here we show that the immediate textual context of a concept is strongly indicative of this property, and, using simple and language-independent machine-learning tools, we leverage this observation to achieve state-of-the-art results in controversiality prediction. In addition, we analyze and make available a new dataset of concepts labeled for controversiality. It is significantly larger than existing datasets, and grades concepts on a 0-10 scale, rather than treating controversiality as a binary label.
Towards Effective Rebuttal: Listening Comprehension using Corpus-Wide Claim Mining
Jul 27, 2019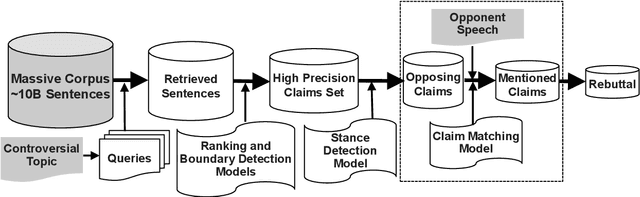
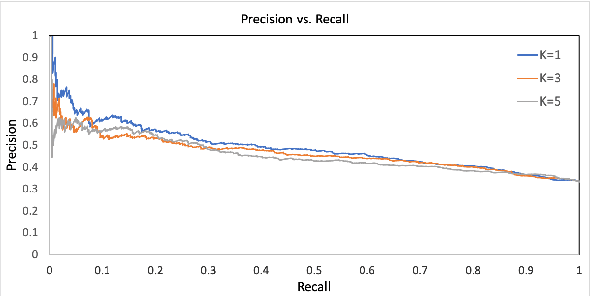
Engaging in a live debate requires, among other things, the ability to effectively rebut arguments claimed by your opponent. In particular, this requires identifying these arguments. Here, we suggest doing so by automatically mining claims from a corpus of news articles containing billions of sentences, and searching for them in a given speech. This raises the question of whether such claims indeed correspond to those made in spoken speeches. To this end, we collected a large dataset of $400$ speeches in English discussing $200$ controversial topics, mined claims for each topic, and asked annotators to identify the mined claims mentioned in each speech. Results show that in the vast majority of speeches debaters indeed make use of such claims. In addition, we present several baselines for the automatic detection of mined claims in speeches, forming the basis for future work. All collected data is freely available for research.
On the practically interesting instances of MAXCUT
May 22, 2012The complexity of a computational problem is traditionally quantified based on the hardness of its worst case. This approach has many advantages and has led to a deep and beautiful theory. However, from the practical perspective, this leaves much to be desired. In application areas, practically interesting instances very often occupy just a tiny part of an algorithm's space of instances, and the vast majority of instances are simply irrelevant. Addressing these issues is a major challenge for theoretical computer science which may make theory more relevant to the practice of computer science. Following Bilu and Linial, we apply this perspective to MAXCUT, viewed as a clustering problem. Using a variety of techniques, we investigate practically interesting instances of this problem. Specifically, we show how to solve in polynomial time distinguished, metric, expanding and dense instances of MAXCUT under mild stability assumptions. In particular, $(1+\epsilon)$-stability (which is optimal) suffices for metric and dense MAXCUT. We also show how to solve in polynomial time $\Omega(\sqrt{n})$-stable instances of MAXCUT, substantially improving the best previously known result.