 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhat if we had no Wikipedia? Domain-independent Term Extraction from a Large News Corpus
Paper and Code
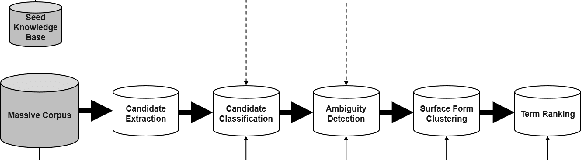
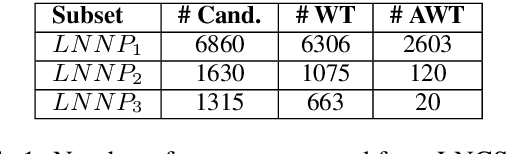
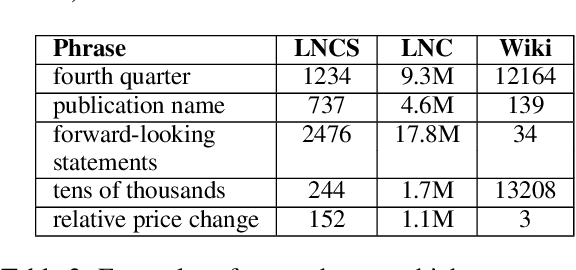
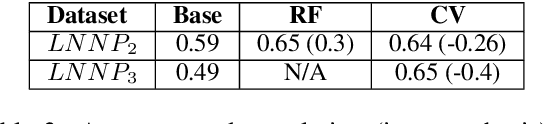
One of the most impressive human endeavors of the past two decades is the collection and categorization of human knowledge in the free and accessible format that is Wikipedia. In this work we ask what makes a term worthy of entering this edifice of knowledge, and having a page of its own in Wikipedia? To what extent is this a natural product of on-going human discourse and discussion rather than an idiosyncratic choice of Wikipedia editors? Specifically, we aim to identify such "wiki-worthy" terms in a massive news corpus, and see if this can be done with no, or minimal, dependency on actual Wikipedia entries. We suggest a five-step pipeline for doing so, providing baseline results for all five, and the relevant datasets for benchmarking them. Our work sheds new light on the domain-specific Automatic Term Extraction problem, with the problem at hand being a domain-independent variant of it.