 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOut of the Echo Chamber: Detecting Countering Debate Speeches
Paper and Code
May 03, 2020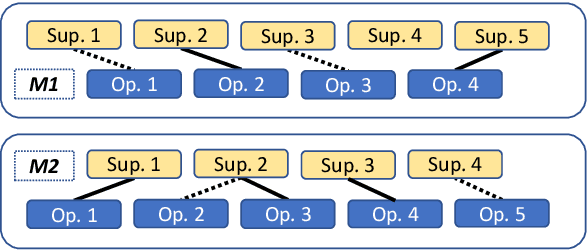
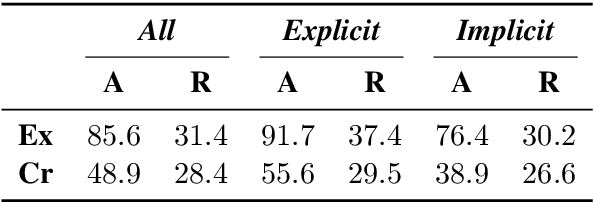
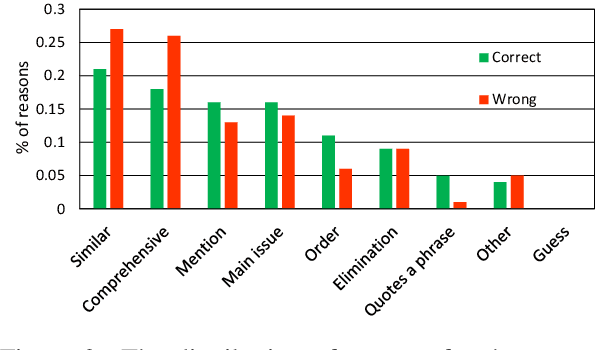

An educated and informed consumption of media content has become a challenge in modern times. With the shift from traditional news outlets to social media and similar venues, a major concern is that readers are becoming encapsulated in "echo chambers" and may fall prey to fake news and disinformation, lacking easy access to dissenting views. We suggest a novel task aiming to alleviate some of these concerns -- that of detecting articles that most effectively counter the arguments -- and not just the stance -- made in a given text. We study this problem in the context of debate speeches. Given such a speech, we aim to identify, from among a set of speeches on the same topic and with an opposing stance, the ones that directly counter it. We provide a large dataset of 3,685 such speeches (in English), annotated for this relation, which hopefully would be of general interest to the NLP community. We explore several algorithms addressing this task, and while some are successful, all fall short of expert human performance, suggesting room for further research. All data collected during this work is freely available for research.