 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLeveraging LLM Inconsistency to Boost Pass@k Performance
May 19, 2025Large language models (LLMs) achieve impressive abilities in numerous domains, but exhibit inconsistent performance in response to minor input changes. Rather than view this as a drawback, in this paper we introduce a novel method for leveraging models' inconsistency to boost Pass@k performance. Specifically, we present a "Variator" agent that generates k variants of a given task and submits one candidate solution for each one. Our variant generation approach is applicable to a wide range of domains as it is task agnostic and compatible with free-form inputs. We demonstrate the efficacy of our agent theoretically using a probabilistic model of the inconsistency effect, and show empirically that it outperforms the baseline on the APPS dataset. Furthermore, we establish that inconsistency persists even in frontier reasoning models across coding and cybersecurity domains, suggesting our method is likely to remain relevant for future model generations.
What Makes an Evaluation Useful? Common Pitfalls and Best Practices
Mar 30, 2025

Following the rapid increase in Artificial Intelligence (AI) capabilities in recent years, the AI community has voiced concerns regarding possible safety risks. To support decision-making on the safe use and development of AI systems, there is a growing need for high-quality evaluations of dangerous model capabilities. While several attempts to provide such evaluations have been made, a clear definition of what constitutes a "good evaluation" has yet to be agreed upon. In this practitioners' perspective paper, we present a set of best practices for safety evaluations, drawing on prior work in model evaluation and illustrated through cybersecurity examples. We first discuss the steps of the initial thought process, which connects threat modeling to evaluation design. Then, we provide the characteristics and parameters that make an evaluation useful. Finally, we address additional considerations as we move from building specific evaluations to building a full and comprehensive evaluation suite.
Benchmark Data and Evaluation Framework for Intent Discovery Around COVID-19 Vaccine Hesitancy
May 24, 2022
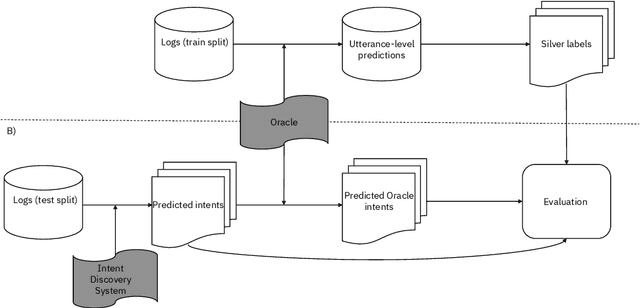

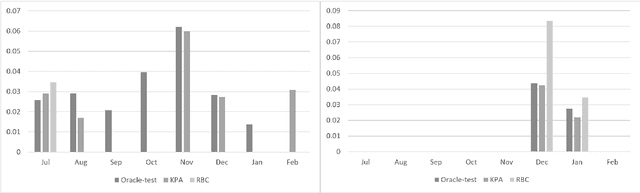
The COVID-19 pandemic has made a huge global impact and cost millions of lives. As COVID-19 vaccines were rolled out, they were quickly met with widespread hesitancy. To address the concerns of hesitant people, we launched VIRA, a public dialogue system aimed at addressing questions and concerns surrounding the COVID-19 vaccines. Here, we release VIRADialogs, a dataset of over 8k dialogues conducted by actual users with VIRA, providing a unique real-world conversational dataset. In light of rapid changes in users' intents, due to updates in guidelines or as a response to new information, we highlight the important task of intent discovery in this use-case. We introduce a novel automatic evaluation framework for intent discovery, leveraging the existing intent classifier of a given dialogue system. We use this framework to report baseline intent-discovery results over VIRADialogs, that highlight the difficulty of this task.
A Search Engine for Discovery of Scientific Challenges and Directions
Sep 10, 2021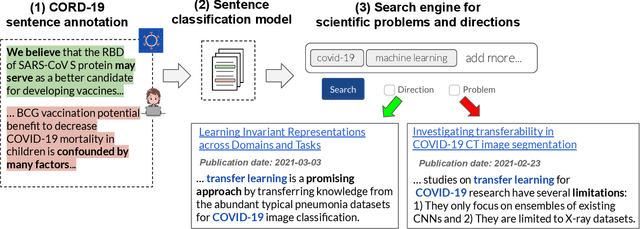


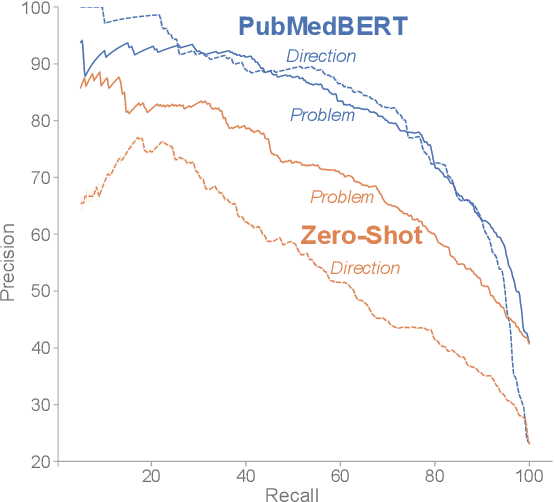
Keeping track of scientific challenges, advances and emerging directions is a fundamental part of research. However, researchers face a flood of papers that hinders discovery of important knowledge. In biomedicine, this directly impacts human lives. To address this problem, we present a novel task of extraction and search of scientific challenges and directions, to facilitate rapid knowledge discovery. We construct and release an expert-annotated corpus of texts sampled from full-length papers, labeled with novel semantic categories that generalize across many types of challenges and directions. We focus on a large corpus of interdisciplinary work relating to the COVID-19 pandemic, ranging from biomedicine to areas such as AI and economics. We apply a model trained on our data to identify challenges and directions across the corpus and build a dedicated search engine. In experiments with 19 researchers and clinicians using our system, we outperform a popular scientific search engine in assisting knowledge discovery. Finally, we show that models trained on our resource generalize to the wider biomedical domain and to AI papers, highlighting its broad utility. We make our data, model and search engine publicly available. https://challenges.apps.allenai.org/
MultiModalQA: Complex Question Answering over Text, Tables and Images
Apr 13, 2021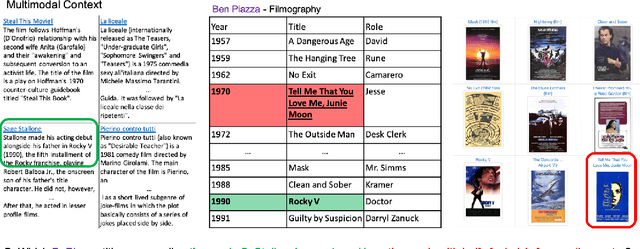
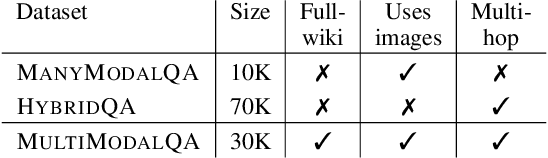

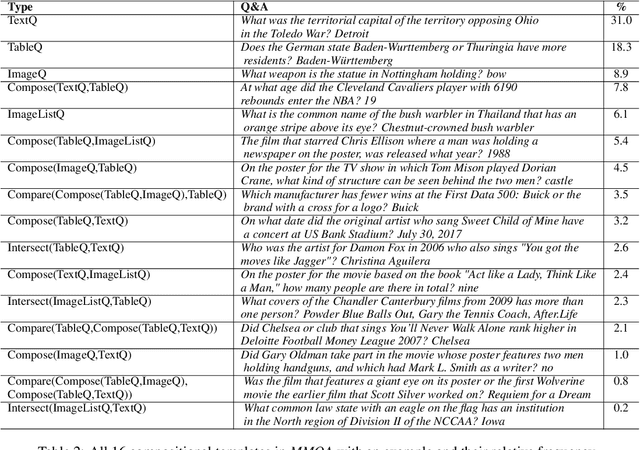
When answering complex questions, people can seamlessly combine information from visual, textual and tabular sources. While interest in models that reason over multiple pieces of evidence has surged in recent years, there has been relatively little work on question answering models that reason across multiple modalities. In this paper, we present MultiModalQA(MMQA): a challenging question answering dataset that requires joint reasoning over text, tables and images. We create MMQA using a new framework for generating complex multi-modal questions at scale, harvesting tables from Wikipedia, and attaching images and text paragraphs using entities that appear in each table. We then define a formal language that allows us to take questions that can be answered from a single modality, and combine them to generate cross-modal questions. Last, crowdsourcing workers take these automatically-generated questions and rephrase them into more fluent language. We create 29,918 questions through this procedure, and empirically demonstrate the necessity of a multi-modal multi-hop approach to solve our task: our multi-hop model, ImplicitDecomp, achieves an average F1of 51.7 over cross-modal questions, substantially outperforming a strong baseline that achieves 38.2 F1, but still lags significantly behind human performance, which is at 90.1 F1
Quantitative Argument Summarization and Beyond: Cross-Domain Key Point Analysis
Oct 11, 2020

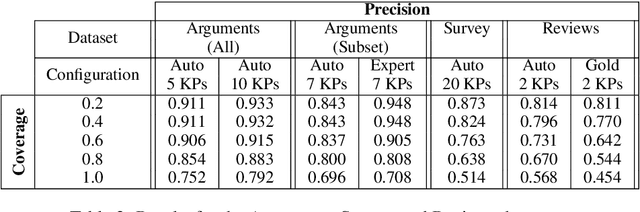
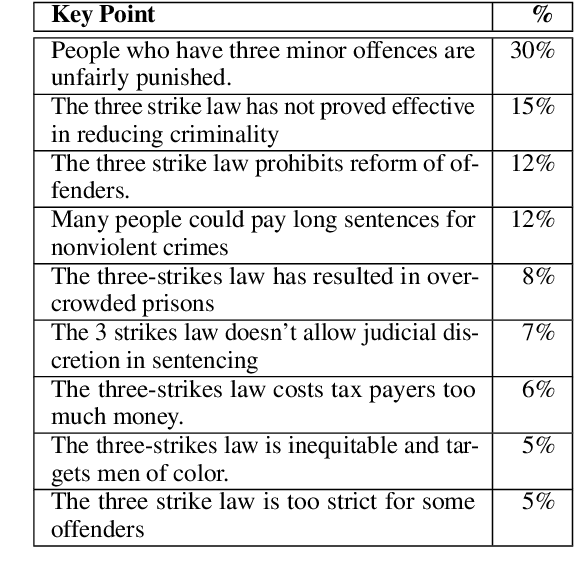
When summarizing a collection of views, arguments or opinions on some topic, it is often desirable not only to extract the most salient points, but also to quantify their prevalence. Work on multi-document summarization has traditionally focused on creating textual summaries, which lack this quantitative aspect. Recent work has proposed to summarize arguments by mapping them to a small set of expert-generated key points, where the salience of each key point corresponds to the number of its matching arguments. The current work advances key point analysis in two important respects: first, we develop a method for automatic extraction of key points, which enables fully automatic analysis, and is shown to achieve performance comparable to a human expert. Second, we demonstrate that the applicability of key point analysis goes well beyond argumentation data. Using models trained on publicly available argumentation datasets, we achieve promising results in two additional domains: municipal surveys and user reviews. An additional contribution is an in-depth evaluation of argument-to-key point matching models, where we substantially outperform previous results.
Interactive Extractive Search over Biomedical Corpora
Jun 07, 2020

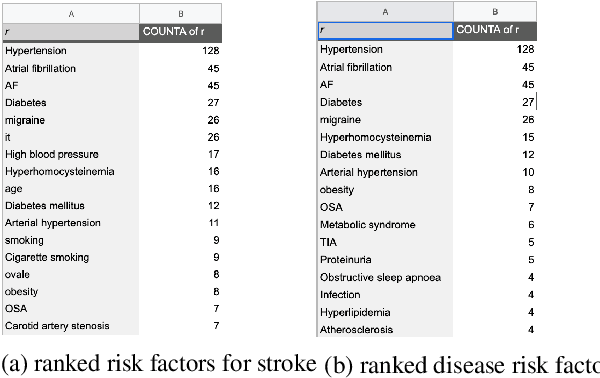
We present a system that allows life-science researchers to search a linguistically annotated corpus of scientific texts using patterns over dependency graphs, as well as using patterns over token sequences and a powerful variant of boolean keyword queries. In contrast to previous attempts to dependency-based search, we introduce a light-weight query language that does not require the user to know the details of the underlying linguistic representations, and instead to query the corpus by providing an example sentence coupled with simple markup. Search is performed at an interactive speed due to efficient linguistic graph-indexing and retrieval engine. This allows for rapid exploration, development and refinement of user queries. We demonstrate the system using example workflows over two corpora: the PubMed corpus including 14,446,243 PubMed abstracts and the CORD-19 dataset, a collection of over 45,000 research papers focused on COVID-19 research. The system is publicly available at https://allenai.github.io/spike
From Arguments to Key Points: Towards Automatic Argument Summarization
May 04, 2020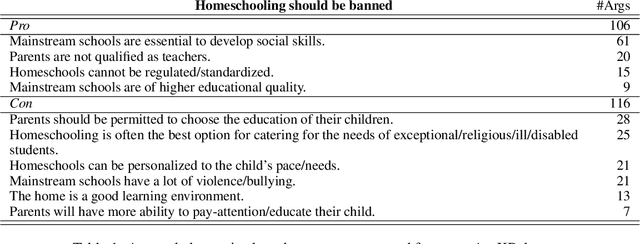
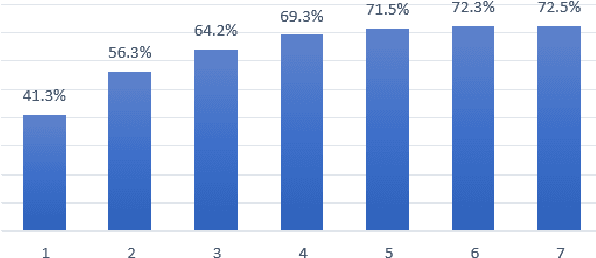
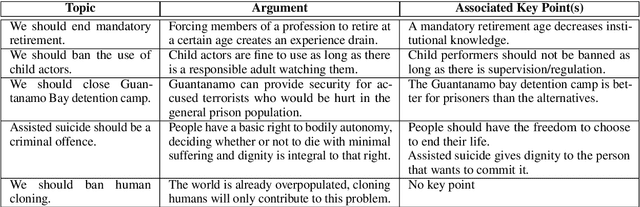
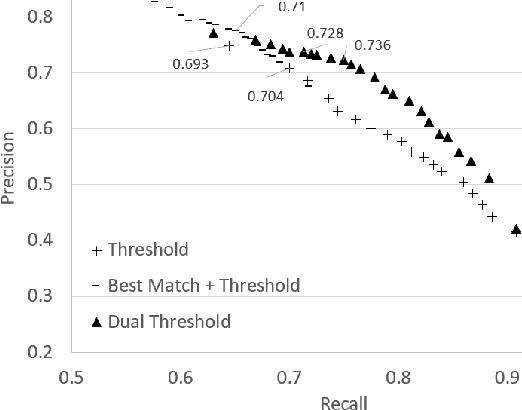
Generating a concise summary from a large collection of arguments on a given topic is an intriguing yet understudied problem. We propose to represent such summaries as a small set of talking points, termed "key points", each scored according to its salience. We show, by analyzing a large dataset of crowd-contributed arguments, that a small number of key points per topic is typically sufficient for covering the vast majority of the arguments. Furthermore, we found that a domain expert can often predict these key points in advance. We study the task of argument-to-key point mapping, and introduce a novel large-scale dataset for this task. We report empirical results for an extensive set of experiments with this dataset, showing promising performance.
Out of the Echo Chamber: Detecting Countering Debate Speeches
May 03, 2020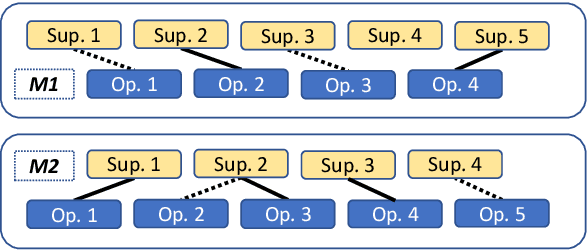

An educated and informed consumption of media content has become a challenge in modern times. With the shift from traditional news outlets to social media and similar venues, a major concern is that readers are becoming encapsulated in "echo chambers" and may fall prey to fake news and disinformation, lacking easy access to dissenting views. We suggest a novel task aiming to alleviate some of these concerns -- that of detecting articles that most effectively counter the arguments -- and not just the stance -- made in a given text. We study this problem in the context of debate speeches. Given such a speech, we aim to identify, from among a set of speeches on the same topic and with an opposing stance, the ones that directly counter it. We provide a large dataset of 3,685 such speeches (in English), annotated for this relation, which hopefully would be of general interest to the NLP community. We explore several algorithms addressing this task, and while some are successful, all fall short of expert human performance, suggesting room for further research. All data collected during this work is freely available for research.
A Large-scale Dataset for Argument Quality Ranking: Construction and Analysis
Nov 26, 2019

Identifying the quality of free-text arguments has become an important task in the rapidly expanding field of computational argumentation. In this work, we explore the challenging task of argument quality ranking. To this end, we created a corpus of 30,497 arguments carefully annotated for point-wise quality, released as part of this work. To the best of our knowledge, this is the largest dataset annotated for point-wise argument quality, larger by a factor of five than previously released datasets. Moreover, we address the core issue of inducing a labeled score from crowd annotations by performing a comprehensive evaluation of different approaches to this problem. In addition, we analyze the quality dimensions that characterize this dataset. Finally, we present a neural method for argument quality ranking, which outperforms several baselines on our own dataset, as well as previous methods published for another dataset.