 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Large-scale Dataset for Argument Quality Ranking: Construction and Analysis
Paper and Code
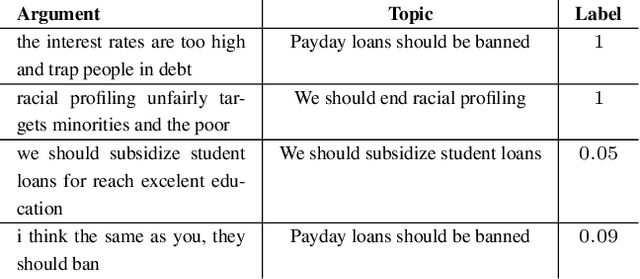
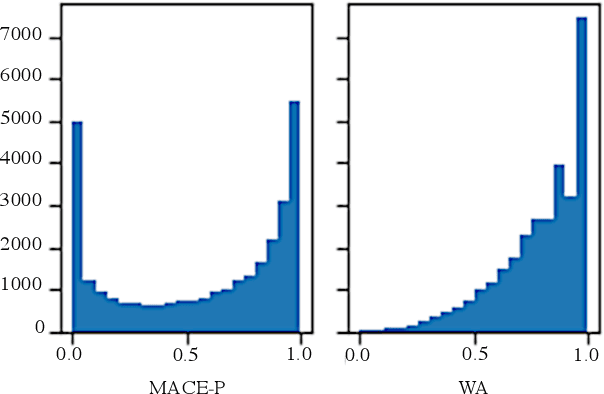

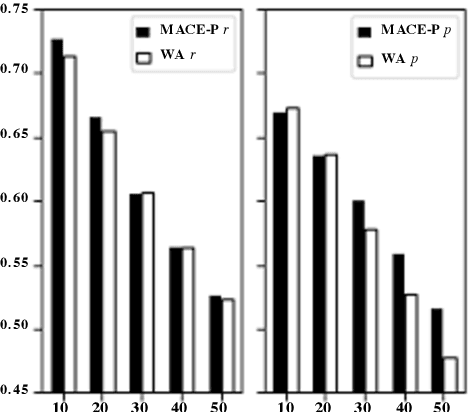
Identifying the quality of free-text arguments has become an important task in the rapidly expanding field of computational argumentation. In this work, we explore the challenging task of argument quality ranking. To this end, we created a corpus of 30,497 arguments carefully annotated for point-wise quality, released as part of this work. To the best of our knowledge, this is the largest dataset annotated for point-wise argument quality, larger by a factor of five than previously released datasets. Moreover, we address the core issue of inducing a labeled score from crowd annotations by performing a comprehensive evaluation of different approaches to this problem. In addition, we analyze the quality dimensions that characterize this dataset. Finally, we present a neural method for argument quality ranking, which outperforms several baselines on our own dataset, as well as previous methods published for another dataset.