 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the Expressivity of Selective State-Space Layers: A Multivariate Polynomial Approach
Feb 04, 2025



Recent advances in efficient sequence modeling have introduced selective state-space layers, a key component of the Mamba architecture, which have demonstrated remarkable success in a wide range of NLP and vision tasks. While Mamba's empirical performance has matched or surpassed SoTA transformers on such diverse benchmarks, the theoretical foundations underlying its powerful representational capabilities remain less explored. In this work, we investigate the expressivity of selective state-space layers using multivariate polynomials, and prove that they surpass linear transformers in expressiveness. Consequently, our findings reveal that Mamba offers superior representational power over linear attention-based models for long sequences, while not sacrificing their generalization. Our theoretical insights are validated by a comprehensive set of empirical experiments on various datasets.
Provable Benefits of Complex Parameterizations for Structured State Space Models
Oct 17, 2024



Structured state space models (SSMs), the core engine behind prominent neural networks such as S4 and Mamba, are linear dynamical systems adhering to a specified structure, most notably diagonal. In contrast to typical neural network modules, whose parameterizations are real, SSMs often use complex parameterizations. Theoretically explaining the benefits of complex parameterizations for SSMs is an open problem. The current paper takes a step towards its resolution, by establishing formal gaps between real and complex diagonal SSMs. Firstly, we prove that while a moderate dimension suffices in order for a complex SSM to express all mappings of a real SSM, a much higher dimension is needed for a real SSM to express mappings of a complex SSM. Secondly, we prove that even if the dimension of a real SSM is high enough to express a given mapping, typically, doing so requires the parameters of the real SSM to hold exponentially large values, which cannot be learned in practice. In contrast, a complex SSM can express any given mapping with moderate parameter values. Experiments corroborate our theory, and suggest a potential extension of the theory that accounts for selectivity, a new architectural feature yielding state of the art performance.
Implicit Bias of Policy Gradient in Linear Quadratic Control: Extrapolation to Unseen Initial States
Feb 12, 2024



In modern machine learning, models can often fit training data in numerous ways, some of which perform well on unseen (test) data, while others do not. Remarkably, in such cases gradient descent frequently exhibits an implicit bias that leads to excellent performance on unseen data. This implicit bias was extensively studied in supervised learning, but is far less understood in optimal control (reinforcement learning). There, learning a controller applied to a system via gradient descent is known as policy gradient, and a question of prime importance is the extent to which a learned controller extrapolates to unseen initial states. This paper theoretically studies the implicit bias of policy gradient in terms of extrapolation to unseen initial states. Focusing on the fundamental Linear Quadratic Regulator (LQR) problem, we establish that the extent of extrapolation depends on the degree of exploration induced by the system when commencing from initial states included in training. Experiments corroborate our theory, and demonstrate its conclusions on problems beyond LQR, where systems are non-linear and controllers are neural networks. We hypothesize that real-world optimal control may be greatly improved by developing methods for informed selection of initial states to train on.
Overcoming Order in Autoregressive Graph Generation
Feb 04, 2024



Graph generation is a fundamental problem in various domains, including chemistry and social networks. Recent work has shown that molecular graph generation using recurrent neural networks (RNNs) is advantageous compared to traditional generative approaches which require converting continuous latent representations into graphs. One issue which arises when treating graph generation as sequential generation is the arbitrary order of the sequence which results from a particular choice of graph flattening method. In this work we propose using RNNs, taking into account the non-sequential nature of graphs by adding an Orderless Regularization (OLR) term that encourages the hidden state of the recurrent model to be invariant to different valid orderings present under the training distribution. We demonstrate that sequential graph generation models benefit from our proposed regularization scheme, especially when data is scarce. Our findings contribute to the growing body of research on graph generation and provide a valuable tool for various applications requiring the synthesis of realistic and diverse graph structures.
Learning Low Dimensional State Spaces with Overparameterized Recurrent Neural Network
Oct 25, 2022Overparameterization in deep learning typically refers to settings where a trained Neural Network (NN) has representational capacity to fit the training data in many ways, some of which generalize well, while others do not. In the case of Recurrent Neural Networks (RNNs), there exists an additional layer of overparameterization, in the sense that a model may exhibit many solutions that generalize well for sequence lengths seen in training, some of which extrapolate to longer sequences, while others do not. Numerous works studied the tendency of Gradient Descent (GD) to fit overparameterized NNs with solutions that generalize well. On the other hand, its tendency to fit overparameterized RNNs with solutions that extrapolate has been discovered only lately, and is far less understood. In this paper, we analyze the extrapolation properties of GD when applied to overparameterized linear RNNs. In contrast to recent arguments suggesting an implicit bias towards short-term memory, we provide theoretical evidence for learning low dimensional state spaces, which can also model long-term memory. Our result relies on a dynamical characterization which shows that GD (with small step size and near-zero initialization) strives to maintain a certain form of balancedness, as well as on tools developed in the context of the moment problem from statistics (recovery of a probability distribution from its moments). Experiments corroborate our theory, demonstrating extrapolation via learning low dimensional state spaces with both linear and non-linear RNNs
On the Implicit Bias of Gradient Descent for Temporal Extrapolation
Feb 09, 2022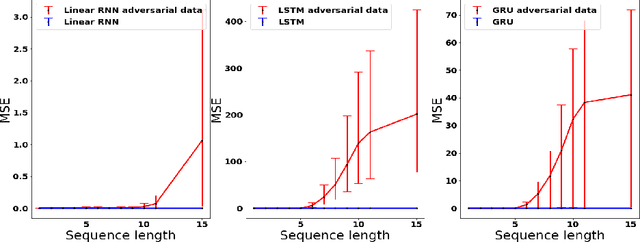
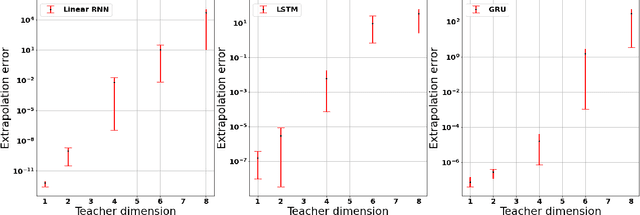
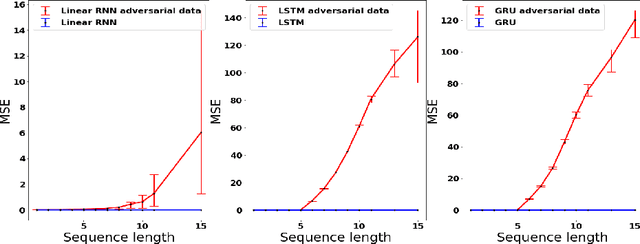
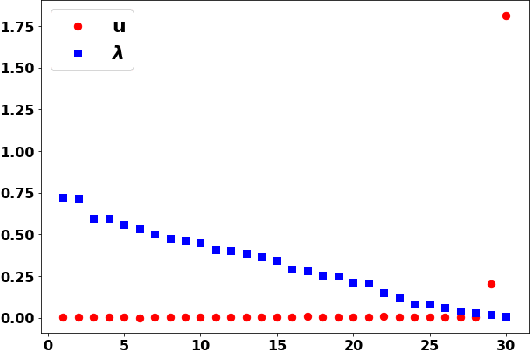
Common practice when using recurrent neural networks (RNNs) is to apply a model to sequences longer than those seen in training. This "extrapolating" usage deviates from the traditional statistical learning setup where guarantees are provided under the assumption that train and test distributions are identical. Here we set out to understand when RNNs can extrapolate, focusing on a simple case where the data generating distribution is memoryless. We first show that even with infinite training data, there exist RNN models that interpolate perfectly (i.e., they fit the training data) yet extrapolate poorly to longer sequences. We then show that if gradient descent is used for training, learning will converge to perfect extrapolation under certain assumption on initialization. Our results complement recent studies on the implicit bias of gradient descent, showing that it plays a key role in extrapolation when learning temporal prediction models.
Regularizing Towards Permutation Invariance in Recurrent Models
Oct 25, 2020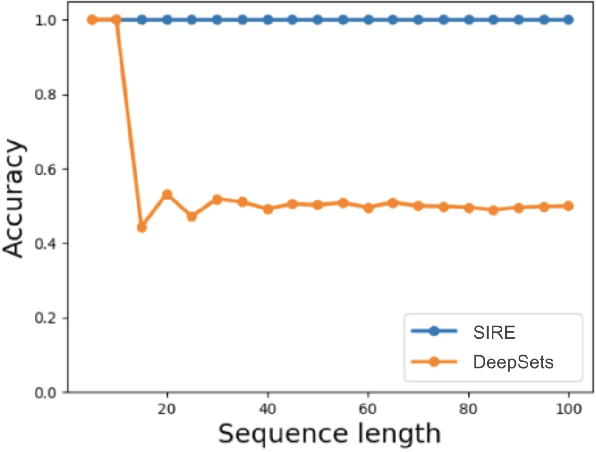
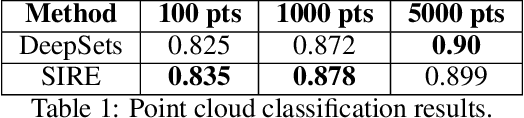
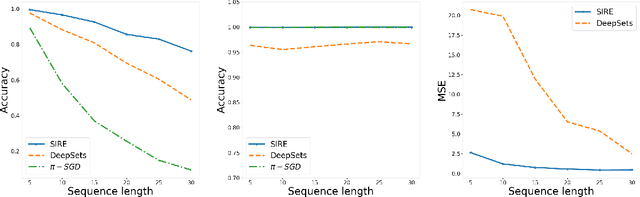

In many machine learning problems the output should not depend on the order of the input. Such "permutation invariant" functions have been studied extensively recently. Here we argue that temporal architectures such as RNNs are highly relevant for such problems, despite the inherent dependence of RNNs on order. We show that RNNs can be regularized towards permutation invariance, and that this can result in compact models, as compared to non-recurrent architectures. We implement this idea via a novel form of stochastic regularization. Existing solutions mostly suggest restricting the learning problem to hypothesis classes which are permutation invariant by design. Our approach of enforcing permutation invariance via regularization gives rise to models which are \textit{semi permutation invariant} (e.g. invariant to some permutations and not to others). We show that our method outperforms other permutation invariant approaches on synthetic and real world datasets.
The workweek is the best time to start a family -- A Study of GPT-2 Based Claim Generation
Oct 13, 2020
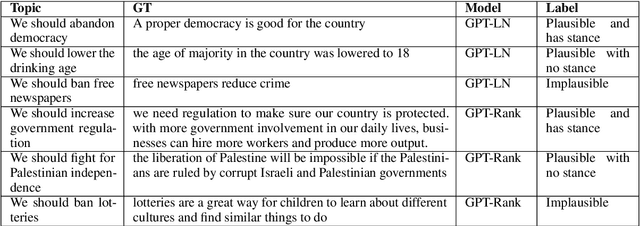


Argument generation is a challenging task whose research is timely considering its potential impact on social media and the dissemination of information. Here we suggest a pipeline based on GPT-2 for generating coherent claims, and explore the types of claims that it produces, and their veracity, using an array of manual and automatic assessments. In addition, we explore the interplay between this task and the task of Claim Retrieval, showing how they can complement one another.
A Large-scale Dataset for Argument Quality Ranking: Construction and Analysis
Nov 26, 2019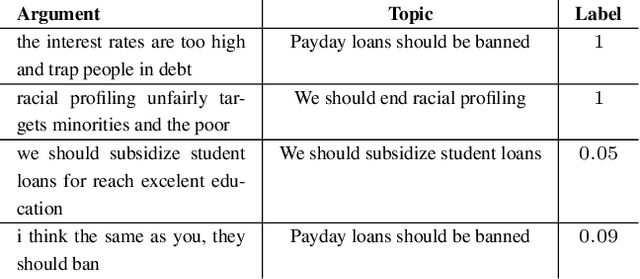
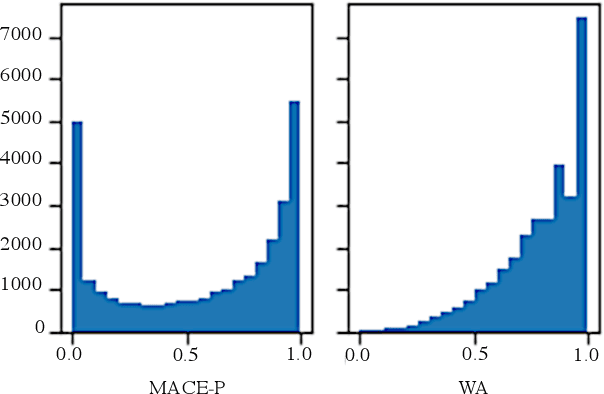

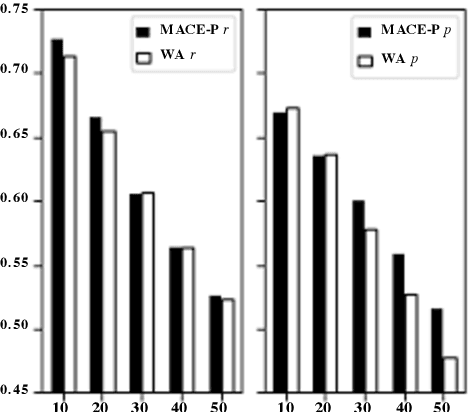
Identifying the quality of free-text arguments has become an important task in the rapidly expanding field of computational argumentation. In this work, we explore the challenging task of argument quality ranking. To this end, we created a corpus of 30,497 arguments carefully annotated for point-wise quality, released as part of this work. To the best of our knowledge, this is the largest dataset annotated for point-wise argument quality, larger by a factor of five than previously released datasets. Moreover, we address the core issue of inducing a labeled score from crowd annotations by performing a comprehensive evaluation of different approaches to this problem. In addition, we analyze the quality dimensions that characterize this dataset. Finally, we present a neural method for argument quality ranking, which outperforms several baselines on our own dataset, as well as previous methods published for another dataset.
Automatic Argument Quality Assessment -- New Datasets and Methods
Sep 03, 2019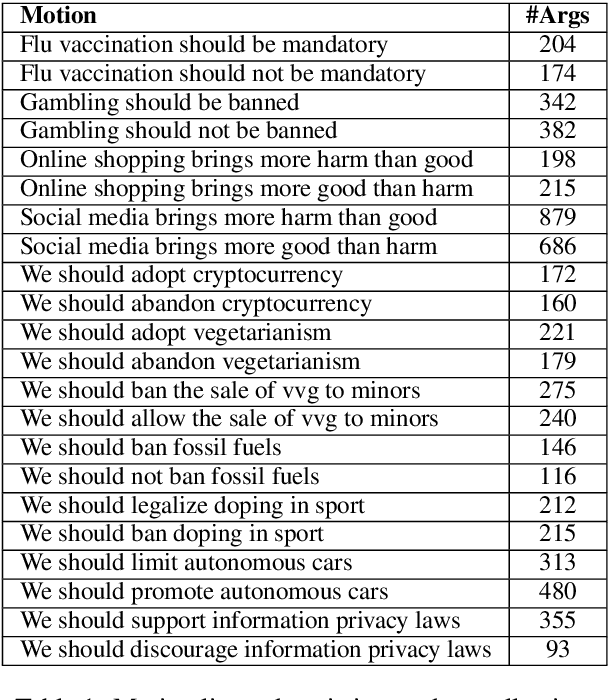
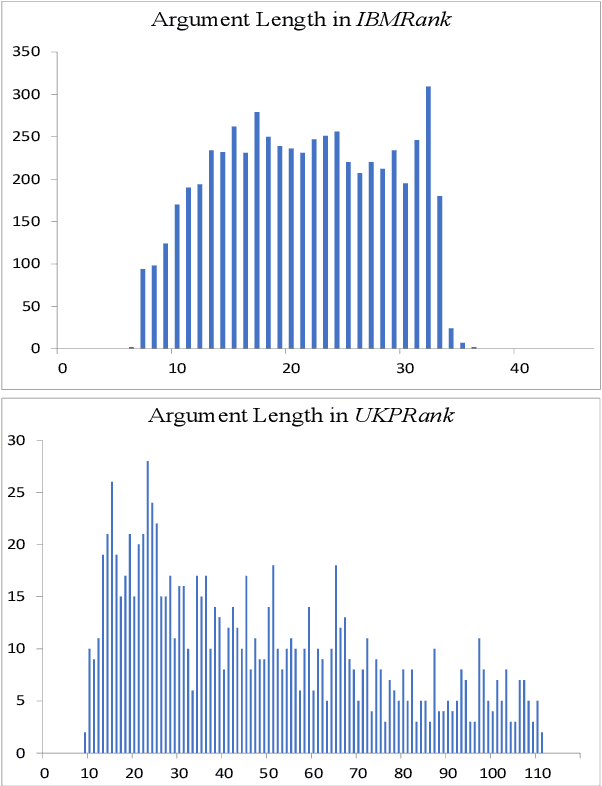
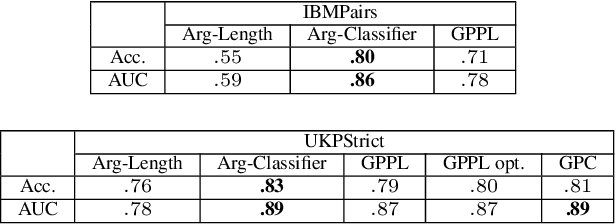
We explore the task of automatic assessment of argument quality. To that end, we actively collected 6.3k arguments, more than a factor of five compared to previously examined data. Each argument was explicitly and carefully annotated for its quality. In addition, 14k pairs of arguments were annotated independently, identifying the higher quality argument in each pair. In spite of the inherent subjective nature of the task, both annotation schemes led to surprisingly consistent results. We release the labeled datasets to the community. Furthermore, we suggest neural methods based on a recently released language model, for argument ranking as well as for argument-pair classification. In the former task, our results are comparable to state-of-the-art; in the latter task our results significantly outperform earlier methods.