 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOutcome-Based RL Provably Leads Transformers to Reason, but Only With the Right Data
Jan 21, 2026Transformers trained via Reinforcement Learning (RL) with outcome-based supervision can spontaneously develop the ability to generate intermediate reasoning steps (Chain-of-Thought). Yet the mechanism by which sparse rewards drive gradient descent to discover such systematic reasoning remains poorly understood. We address this by analyzing the gradient flow dynamics of single-layer Transformers on a synthetic graph traversal task that cannot be solved without Chain-of-Thought (CoT) but admits a simple iterative solution. We prove that despite training solely on final-answer correctness, gradient flow drives the model to converge to a structured, interpretable algorithm that iteratively traverses the graph vertex-by-vertex. We characterize the distributional properties required for this emergence, identifying the critical role of "simple examples": instances requiring fewer reasoning steps. When the training distribution places sufficient mass on these simpler instances, the model learns a generalizable traversal strategy that extrapolates to longer chains; when this mass vanishes, gradient-based learning becomes infeasible. We corroborate our theoretical results through experiments on synthetic data and with real-world language models on mathematical reasoning tasks, validating that our theoretical findings carry over to practical settings.
Do Neural Networks Need Gradient Descent to Generalize? A Theoretical Study
Jun 04, 2025



Conventional wisdom attributes the mysterious generalization abilities of overparameterized neural networks to gradient descent (and its variants). The recent volume hypothesis challenges this view: it posits that these generalization abilities persist even when gradient descent is replaced by Guess & Check (G&C), i.e., by drawing weight settings until one that fits the training data is found. The validity of the volume hypothesis for wide and deep neural networks remains an open question. In this paper, we theoretically investigate this question for matrix factorization (with linear and non-linear activation)--a common testbed in neural network theory. We first prove that generalization under G&C deteriorates with increasing width, establishing what is, to our knowledge, the first case where G&C is provably inferior to gradient descent. Conversely, we prove that generalization under G&C improves with increasing depth, revealing a stark contrast between wide and deep networks, which we further validate empirically. These findings suggest that even in simple settings, there may not be a simple answer to the question of whether neural networks need gradient descent to generalize well.
Revisiting Glorot Initialization for Long-Range Linear Recurrences
May 26, 2025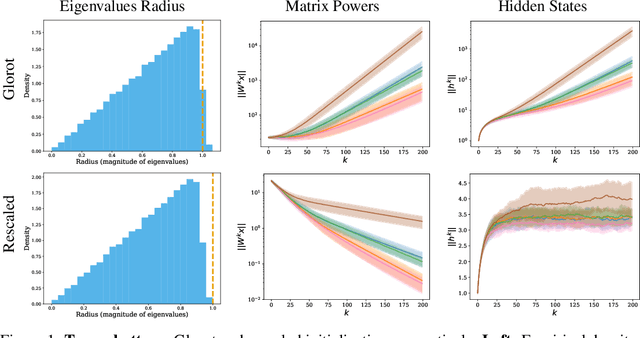
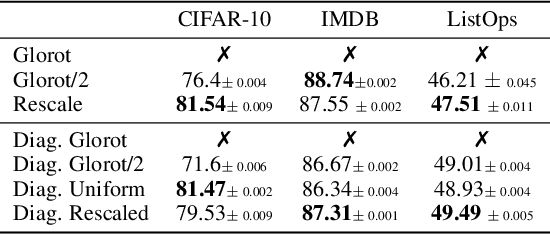
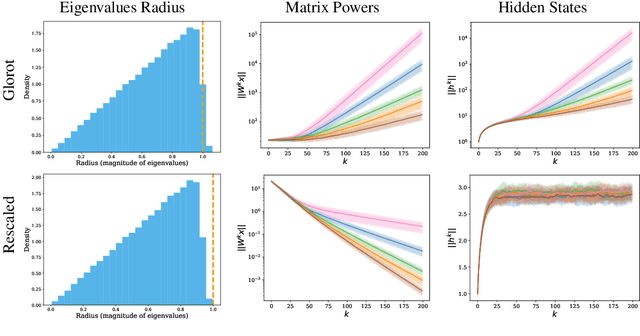
Proper initialization is critical for Recurrent Neural Networks (RNNs), particularly in long-range reasoning tasks, where repeated application of the same weight matrix can cause vanishing or exploding signals. A common baseline for linear recurrences is Glorot initialization, designed to ensure stable signal propagation--but derived under the infinite-width, fixed-length regime--an unrealistic setting for RNNs processing long sequences. In this work, we show that Glorot initialization is in fact unstable: small positive deviations in the spectral radius are amplified through time and cause the hidden state to explode. Our theoretical analysis demonstrates that sequences of length $t = O(\sqrt{n})$, where $n$ is the hidden width, are sufficient to induce instability. To address this, we propose a simple, dimension-aware rescaling of Glorot that shifts the spectral radius slightly below one, preventing rapid signal explosion or decay. These results suggest that standard initialization schemes may break down in the long-sequence regime, motivating a separate line of theory for stable recurrent initialization.
The Implicit Bias of Structured State Space Models Can Be Poisoned With Clean Labels
Oct 14, 2024



Neural networks are powered by an implicit bias: a tendency of gradient descent to fit training data in a way that generalizes to unseen data. A recent class of neural network models gaining increasing popularity is structured state space models (SSMs), regarded as an efficient alternative to transformers. Prior work argued that the implicit bias of SSMs leads to generalization in a setting where data is generated by a low dimensional teacher. In this paper, we revisit the latter setting, and formally establish a phenomenon entirely undetected by prior work on the implicit bias of SSMs. Namely, we prove that while implicit bias leads to generalization under many choices of training data, there exist special examples whose inclusion in training completely distorts the implicit bias, to a point where generalization fails. This failure occurs despite the special training examples being labeled by the teacher, i.e. having clean labels! We empirically demonstrate the phenomenon, with SSMs trained independently and as part of non-linear neural networks. In the area of adversarial machine learning, disrupting generalization with cleanly labeled training examples is known as clean-label poisoning. Given the proliferation of SSMs, particularly in large language models, we believe significant efforts should be invested in further delineating their susceptibility to clean-label poisoning, and in developing methods for overcoming this susceptibility.
Implicit Bias of Policy Gradient in Linear Quadratic Control: Extrapolation to Unseen Initial States
Feb 12, 2024



In modern machine learning, models can often fit training data in numerous ways, some of which perform well on unseen (test) data, while others do not. Remarkably, in such cases gradient descent frequently exhibits an implicit bias that leads to excellent performance on unseen data. This implicit bias was extensively studied in supervised learning, but is far less understood in optimal control (reinforcement learning). There, learning a controller applied to a system via gradient descent is known as policy gradient, and a question of prime importance is the extent to which a learned controller extrapolates to unseen initial states. This paper theoretically studies the implicit bias of policy gradient in terms of extrapolation to unseen initial states. Focusing on the fundamental Linear Quadratic Regulator (LQR) problem, we establish that the extent of extrapolation depends on the degree of exploration induced by the system when commencing from initial states included in training. Experiments corroborate our theory, and demonstrate its conclusions on problems beyond LQR, where systems are non-linear and controllers are neural networks. We hypothesize that real-world optimal control may be greatly improved by developing methods for informed selection of initial states to train on.
What Makes Data Suitable for a Locally Connected Neural Network? A Necessary and Sufficient Condition Based on Quantum Entanglement
Mar 20, 2023



The question of what makes a data distribution suitable for deep learning is a fundamental open problem. Focusing on locally connected neural networks (a prevalent family of architectures that includes convolutional and recurrent neural networks as well as local self-attention models), we address this problem by adopting theoretical tools from quantum physics. Our main theoretical result states that a certain locally connected neural network is capable of accurate prediction over a data distribution if and only if the data distribution admits low quantum entanglement under certain canonical partitions of features. As a practical application of this result, we derive a preprocessing method for enhancing the suitability of a data distribution to locally connected neural networks. Experiments with widespread models over various datasets demonstrate our findings. We hope that our use of quantum entanglement will encourage further adoption of tools from physics for formally reasoning about the relation between deep learning and real-world data.