 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDo Neural Networks Need Gradient Descent to Generalize? A Theoretical Study
Jun 04, 2025



Conventional wisdom attributes the mysterious generalization abilities of overparameterized neural networks to gradient descent (and its variants). The recent volume hypothesis challenges this view: it posits that these generalization abilities persist even when gradient descent is replaced by Guess & Check (G&C), i.e., by drawing weight settings until one that fits the training data is found. The validity of the volume hypothesis for wide and deep neural networks remains an open question. In this paper, we theoretically investigate this question for matrix factorization (with linear and non-linear activation)--a common testbed in neural network theory. We first prove that generalization under G&C deteriorates with increasing width, establishing what is, to our knowledge, the first case where G&C is provably inferior to gradient descent. Conversely, we prove that generalization under G&C improves with increasing depth, revealing a stark contrast between wide and deep networks, which we further validate empirically. These findings suggest that even in simple settings, there may not be a simple answer to the question of whether neural networks need gradient descent to generalize well.
Mamba Knockout for Unraveling Factual Information Flow
May 30, 2025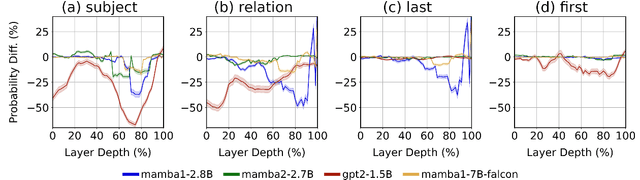
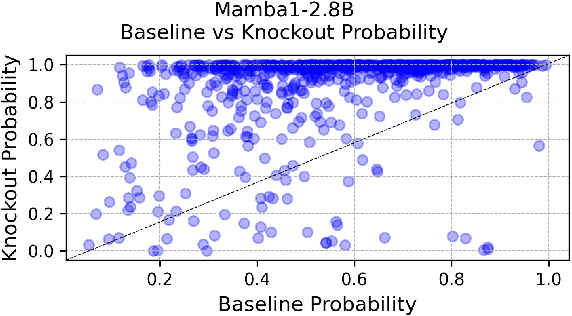


This paper investigates the flow of factual information in Mamba State-Space Model (SSM)-based language models. We rely on theoretical and empirical connections to Transformer-based architectures and their attention mechanisms. Exploiting this relationship, we adapt attentional interpretability techniques originally developed for Transformers--specifically, the Attention Knockout methodology--to both Mamba-1 and Mamba-2. Using them we trace how information is transmitted and localized across tokens and layers, revealing patterns of subject-token information emergence and layer-wise dynamics. Notably, some phenomena vary between mamba models and Transformer based models, while others appear universally across all models inspected--hinting that these may be inherent to LLMs in general. By further leveraging Mamba's structured factorization, we disentangle how distinct "features" either enable token-to-token information exchange or enrich individual tokens, thus offering a unified lens to understand Mamba internal operations.
The Implicit Bias of Structured State Space Models Can Be Poisoned With Clean Labels
Oct 14, 2024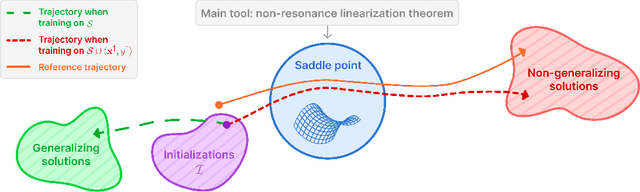



Neural networks are powered by an implicit bias: a tendency of gradient descent to fit training data in a way that generalizes to unseen data. A recent class of neural network models gaining increasing popularity is structured state space models (SSMs), regarded as an efficient alternative to transformers. Prior work argued that the implicit bias of SSMs leads to generalization in a setting where data is generated by a low dimensional teacher. In this paper, we revisit the latter setting, and formally establish a phenomenon entirely undetected by prior work on the implicit bias of SSMs. Namely, we prove that while implicit bias leads to generalization under many choices of training data, there exist special examples whose inclusion in training completely distorts the implicit bias, to a point where generalization fails. This failure occurs despite the special training examples being labeled by the teacher, i.e. having clean labels! We empirically demonstrate the phenomenon, with SSMs trained independently and as part of non-linear neural networks. In the area of adversarial machine learning, disrupting generalization with cleanly labeled training examples is known as clean-label poisoning. Given the proliferation of SSMs, particularly in large language models, we believe significant efforts should be invested in further delineating their susceptibility to clean-label poisoning, and in developing methods for overcoming this susceptibility.