 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOutcome-Based RL Provably Leads Transformers to Reason, but Only With the Right Data
Jan 21, 2026Transformers trained via Reinforcement Learning (RL) with outcome-based supervision can spontaneously develop the ability to generate intermediate reasoning steps (Chain-of-Thought). Yet the mechanism by which sparse rewards drive gradient descent to discover such systematic reasoning remains poorly understood. We address this by analyzing the gradient flow dynamics of single-layer Transformers on a synthetic graph traversal task that cannot be solved without Chain-of-Thought (CoT) but admits a simple iterative solution. We prove that despite training solely on final-answer correctness, gradient flow drives the model to converge to a structured, interpretable algorithm that iteratively traverses the graph vertex-by-vertex. We characterize the distributional properties required for this emergence, identifying the critical role of "simple examples": instances requiring fewer reasoning steps. When the training distribution places sufficient mass on these simpler instances, the model learns a generalizable traversal strategy that extrapolates to longer chains; when this mass vanishes, gradient-based learning becomes infeasible. We corroborate our theoretical results through experiments on synthetic data and with real-world language models on mathematical reasoning tasks, validating that our theoretical findings carry over to practical settings.
Do Neural Networks Need Gradient Descent to Generalize? A Theoretical Study
Jun 04, 2025



Conventional wisdom attributes the mysterious generalization abilities of overparameterized neural networks to gradient descent (and its variants). The recent volume hypothesis challenges this view: it posits that these generalization abilities persist even when gradient descent is replaced by Guess & Check (G&C), i.e., by drawing weight settings until one that fits the training data is found. The validity of the volume hypothesis for wide and deep neural networks remains an open question. In this paper, we theoretically investigate this question for matrix factorization (with linear and non-linear activation)--a common testbed in neural network theory. We first prove that generalization under G&C deteriorates with increasing width, establishing what is, to our knowledge, the first case where G&C is provably inferior to gradient descent. Conversely, we prove that generalization under G&C improves with increasing depth, revealing a stark contrast between wide and deep networks, which we further validate empirically. These findings suggest that even in simple settings, there may not be a simple answer to the question of whether neural networks need gradient descent to generalize well.
Transformer-Based Robust Underwater Inertial Navigation in Prolonged Doppler Velocity Log Outages
Apr 10, 2025
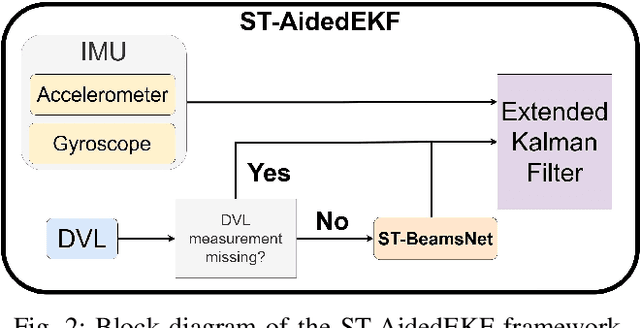
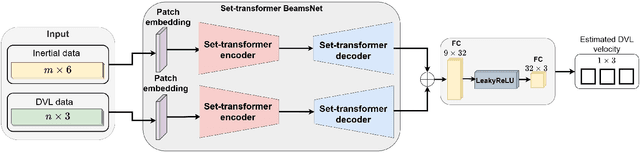

Autonomous underwater vehicles (AUV) have a wide variety of applications in the marine domain, including exploration, surveying, and mapping. Their navigation systems rely heavily on fusing data from inertial sensors and a Doppler velocity log (DVL), typically via nonlinear filtering. The DVL estimates the AUV's velocity vector by transmitting acoustic beams to the seabed and analyzing the Doppler shift from the reflected signals. However, due to environmental challenges, DVL beams can deflect or fail in real-world settings, causing signal outages. In such cases, the AUV relies solely on inertial data, leading to accumulated navigation errors and mission terminations. To cope with these outages, we adopted ST-BeamsNet, a deep learning approach that uses inertial readings and prior DVL data to estimate AUV velocity during isolated outages. In this work, we extend ST-BeamsNet to address prolonged DVL outages and evaluate its impact within an extended Kalman filter framework. Experiments demonstrate that the proposed framework improves velocity RMSE by up to 63% and reduces final position error by up to 95% compared to pure inertial navigation. This is in scenarios involving up to 50 seconds of complete DVL outage.
Enhancing Underwater Navigation through Cross-Correlation-Aware Deep INS/DVL Fusion
Mar 27, 2025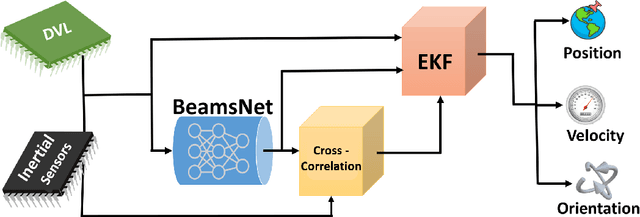
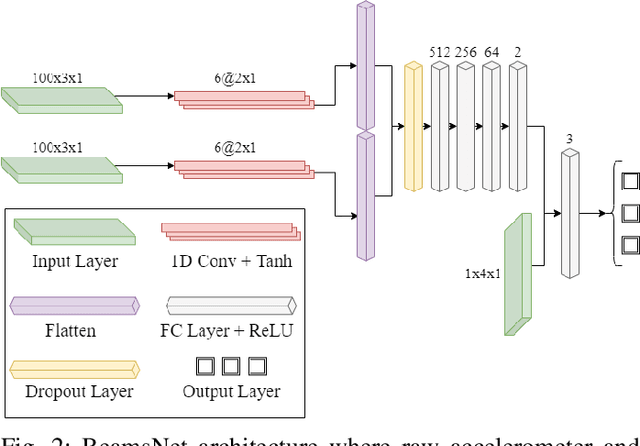
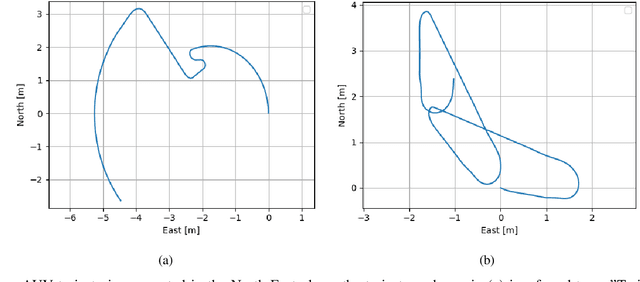
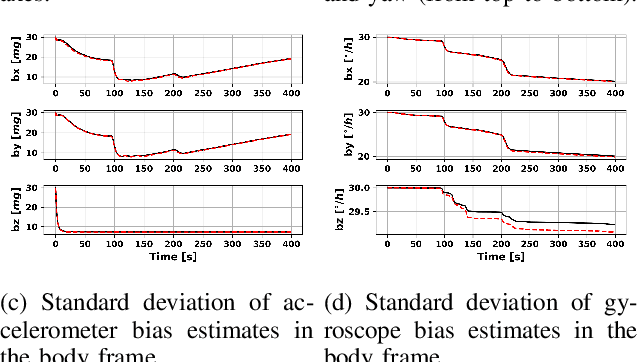
The accurate navigation of autonomous underwater vehicles critically depends on the precision of Doppler velocity log (DVL) velocity measurements. Recent advancements in deep learning have demonstrated significant potential in improving DVL outputs by leveraging spatiotemporal dependencies across multiple sensor modalities. However, integrating these estimates into model-based filters, such as the extended Kalman filter, introduces statistical inconsistencies, most notably, cross-correlations between process and measurement noise. This paper addresses this challenge by proposing a cross-correlation-aware deep INS/DVL fusion framework. Building upon BeamsNet, a convolutional neural network designed to estimate AUV velocity using DVL and inertial data, we integrate its output into a navigation filter that explicitly accounts for the cross-correlation induced between the noise sources. This approach improves filter consistency and better reflects the underlying sensor error structure. Evaluated on two real-world underwater trajectories, the proposed method outperforms both least squares and cross-correlation-neglecting approaches in terms of state uncertainty. Notably, improvements exceed 10% in velocity and misalignment angle confidence metrics. Beyond demonstrating empirical performance, this framework provides a theoretically principled mechanism for embedding deep learning outputs within stochastic filters.
Performance Analysis of Spatial and Temporal Learning Networks in the Presence of DVL Noise
Mar 07, 2025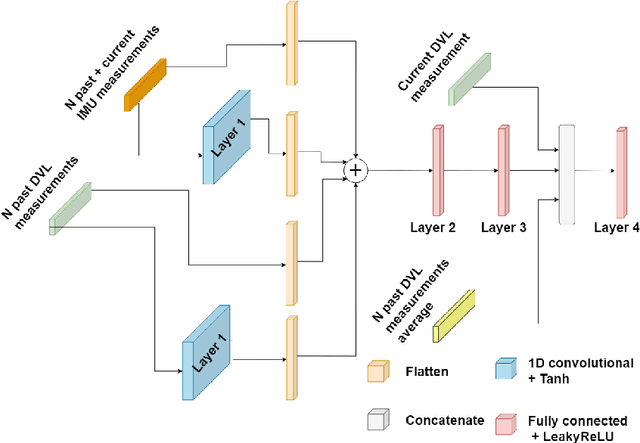
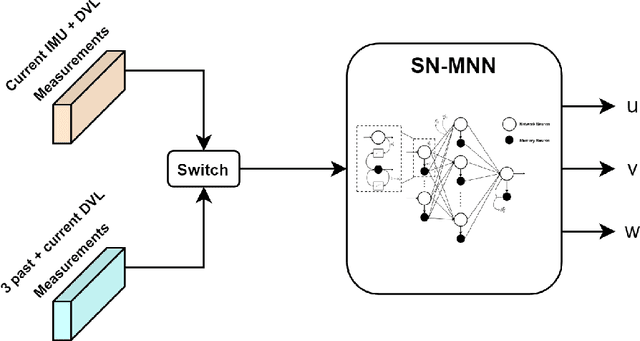
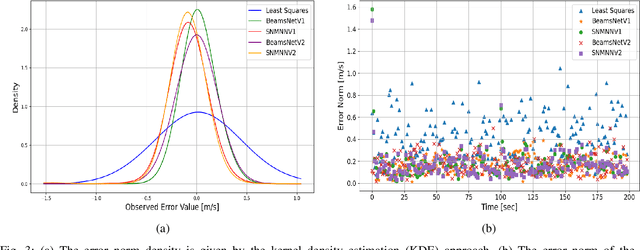

Navigation is a critical aspect of autonomous underwater vehicles (AUVs) operating in complex underwater environments. Since global navigation satellite system (GNSS) signals are unavailable underwater, navigation relies on inertial sensing, which tends to accumulate errors over time. To mitigate this, the Doppler velocity log (DVL) plays a crucial role in determining navigation accuracy. In this paper, we compare two neural network models: an adapted version of BeamsNet, based on a one-dimensional convolutional neural network, and a Spectrally Normalized Memory Neural Network (SNMNN). The former focuses on extracting spatial features, while the latter leverages memory and temporal features to provide more accurate velocity estimates while handling biased and noisy DVL data. The proposed approaches were trained and tested on real AUV data collected in the Mediterranean Sea. Both models are evaluated in terms of accuracy and estimation certainty and are benchmarked against the least squares (LS) method, the current model-based approach. The results show that the neural network models achieve over a 50% improvement in RMSE for the estimation of the AUV velocity, with a smaller standard deviation.
Gaussian Process Regression for Improved Underwater Navigation
Feb 23, 2025Accurate underwater navigation is a challenging task due to the absence of global navigation satellite system signals and the reliance on inertial navigation systems that suffer from drift over time. Doppler velocity logs (DVLs) are typically used to mitigate this drift through velocity measurements, which are commonly estimated using a parameter estimation approach such as least squares (LS). However, LS works under the assumption of ideal conditions and does not account for sensor biases, leading to suboptimal performance. This paper proposes a data-driven alternative based on multi-output Gaussian process regression (MOGPR) to improve DVL velocity estimation. MOGPR provides velocity estimates and associated measurement covariances, enabling an adaptive integration within an error-state Extended Kalman Filter (EKF). We evaluate our proposed approach using real-world AUV data and compare it against LS and a state-of-the-art deep learning model, BeamsNet. Results demonstrate that MOGPR reduces velocity estimation errors by approximately 20% while simultaneously enhancing overall navigation accuracy, particularly in the orientation states. Additionally, the incorporation of uncertainty estimates from MOGPR enables an adaptive EKF framework, improving navigation robustness in dynamic underwater environments.
Data-driven Coreference-based Ontology Building
Oct 22, 2024While coreference resolution is traditionally used as a component in individual document understanding, in this work we take a more global view and explore what can we learn about a domain from the set of all document-level coreference relations that are present in a large corpus. We derive coreference chains from a corpus of 30 million biomedical abstracts and construct a graph based on the string phrases within these chains, establishing connections between phrases if they co-occur within the same coreference chain. We then use the graph structure and the betweeness centrality measure to distinguish between edges denoting hierarchy, identity and noise, assign directionality to edges denoting hierarchy, and split nodes (strings) that correspond to multiple distinct concepts. The result is a rich, data-driven ontology over concepts in the biomedical domain, parts of which overlaps significantly with human-authored ontologies. We release the coreference chains and resulting ontology under a creative-commons license, along with the code.
Provable Benefits of Complex Parameterizations for Structured State Space Models
Oct 17, 2024



Structured state space models (SSMs), the core engine behind prominent neural networks such as S4 and Mamba, are linear dynamical systems adhering to a specified structure, most notably diagonal. In contrast to typical neural network modules, whose parameterizations are real, SSMs often use complex parameterizations. Theoretically explaining the benefits of complex parameterizations for SSMs is an open problem. The current paper takes a step towards its resolution, by establishing formal gaps between real and complex diagonal SSMs. Firstly, we prove that while a moderate dimension suffices in order for a complex SSM to express all mappings of a real SSM, a much higher dimension is needed for a real SSM to express mappings of a complex SSM. Secondly, we prove that even if the dimension of a real SSM is high enough to express a given mapping, typically, doing so requires the parameters of the real SSM to hold exponentially large values, which cannot be learned in practice. In contrast, a complex SSM can express any given mapping with moderate parameter values. Experiments corroborate our theory, and suggest a potential extension of the theory that accounts for selectivity, a new architectural feature yielding state of the art performance.
The Implicit Bias of Structured State Space Models Can Be Poisoned With Clean Labels
Oct 14, 2024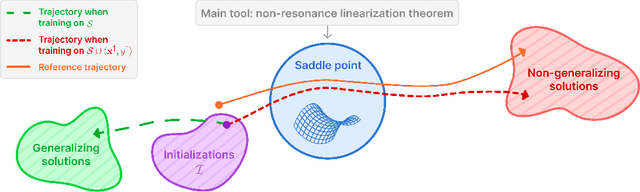



Neural networks are powered by an implicit bias: a tendency of gradient descent to fit training data in a way that generalizes to unseen data. A recent class of neural network models gaining increasing popularity is structured state space models (SSMs), regarded as an efficient alternative to transformers. Prior work argued that the implicit bias of SSMs leads to generalization in a setting where data is generated by a low dimensional teacher. In this paper, we revisit the latter setting, and formally establish a phenomenon entirely undetected by prior work on the implicit bias of SSMs. Namely, we prove that while implicit bias leads to generalization under many choices of training data, there exist special examples whose inclusion in training completely distorts the implicit bias, to a point where generalization fails. This failure occurs despite the special training examples being labeled by the teacher, i.e. having clean labels! We empirically demonstrate the phenomenon, with SSMs trained independently and as part of non-linear neural networks. In the area of adversarial machine learning, disrupting generalization with cleanly labeled training examples is known as clean-label poisoning. Given the proliferation of SSMs, particularly in large language models, we believe significant efforts should be invested in further delineating their susceptibility to clean-label poisoning, and in developing methods for overcoming this susceptibility.
Lecture Notes on Linear Neural Networks: A Tale of Optimization and Generalization in Deep Learning
Aug 25, 2024


These notes are based on a lecture delivered by NC on March 2021, as part of an advanced course in Princeton University on the mathematical understanding of deep learning. They present a theory (developed by NC, NR and collaborators) of linear neural networks -- a fundamental model in the study of optimization and generalization in deep learning. Practical applications born from the presented theory are also discussed. The theory is based on mathematical tools that are dynamical in nature. It showcases the potential of such tools to push the envelope of our understanding of optimization and generalization in deep learning. The text assumes familiarity with the basics of statistical learning theory. Exercises (without solutions) are included.