 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFaithfulness Serum: Mitigating the Faithfulness Gap in Textual Explanations of LLM Decisions via Attribution Guidance
Apr 15, 2026Large language models (LLMs) achieve strong performance and have revolutionized NLP, but their lack of explainability keeps them treated as black boxes, limiting their use in domains that demand transparency and trust. A promising direction to address this issue is post-hoc text-based explanations, which aim to explain model decisions in natural language. Prior work has focused on generating convincing rationales that appear to be subjectively faithful, but it remains unclear whether these explanations are epistemically faithful, whether they reflect the internal evidence the model actually relied on for its decision. In this paper, we first assess the epistemic faithfulness of LLM-generated explanations via counterfactuals and show that they are often unfaithful. We then introduce a training-free method that enhances faithfulness by guiding explanation generation through attention-level interventions, informed by token-level heatmaps extracted via a faithful attribution method. This method significantly improves epistemic faithfulness across multiple models, benchmarks, and prompts.
TensorLens: End-to-End Transformer Analysis via High-Order Attention Tensors
Jan 25, 2026Attention matrices are fundamental to transformer research, supporting a broad range of applications including interpretability, visualization, manipulation, and distillation. Yet, most existing analyses focus on individual attention heads or layers, failing to account for the model's global behavior. While prior efforts have extended attention formulations across multiple heads via averaging and matrix multiplications or incorporated components such as normalization and FFNs, a unified and complete representation that encapsulates all transformer blocks is still lacking. We address this gap by introducing TensorLens, a novel formulation that captures the entire transformer as a single, input-dependent linear operator expressed through a high-order attention-interaction tensor. This tensor jointly encodes attention, FFNs, activations, normalizations, and residual connections, offering a theoretically coherent and expressive linear representation of the model's computation. TensorLens is theoretically grounded and our empirical validation shows that it yields richer representations than previous attention-aggregation methods. Our experiments demonstrate that the attention tensor can serve as a powerful foundation for developing tools aimed at interpretability and model understanding. Our code is attached as a supplementary.
CLIMP: Contrastive Language-Image Mamba Pretraining
Jan 11, 2026Contrastive Language-Image Pre-training (CLIP) relies on Vision Transformers whose attention mechanism is susceptible to spurious correlations, and scales quadratically with resolution. To address these limitations, We present CLIMP, the first fully Mamba-based contrastive vision-language model that replaces both the vision and text encoders with Mamba. The new architecture encodes sequential structure in both vision and language, with VMamba capturing visual spatial inductive biases, reducing reliance on spurious correlations and producing an embedding space favorable for cross-modal retrieval and out-of-distribution robustness-surpassing OpenAI's CLIP-ViT-B by 7.5% on ImageNet-O. CLIMP naturally supports variable input resolutions without positional encoding interpolation or specialized training, achieving up to 6.6% higher retrieval accuracy at 16x training resolution while using 5x less memory and 1.8x fewer FLOPs. The autoregressive text encoder further overcomes CLIP's fixed context limitation, enabling dense captioning retrieval. Our findings suggest that Mamba exhibits advantageous properties for vision-language learning, making it a compelling alternative to Transformer-based CLIP.
Neural Brain Fields: A NeRF-Inspired Approach for Generating Nonexistent EEG Electrodes
Dec 20, 2025Electroencephalography (EEG) data present unique modeling challenges because recordings vary in length, exhibit very low signal to noise ratios, differ significantly across participants, drift over time within sessions, and are rarely available in large and clean datasets. Consequently, developing deep learning methods that can effectively process EEG signals remains an open and important research problem. To tackle this problem, this work presents a new method inspired by Neural Radiance Fields (NeRF). In computer vision, NeRF techniques train a neural network to memorize the appearance of a 3D scene and then uses its learned parameters to render and edit the scene from any viewpoint. We draw an analogy between the discrete images captured from different viewpoints used to learn a continuous 3D scene in NeRF, and EEG electrodes positioned at different locations on the scalp, which are used to infer the underlying representation of continuous neural activity. Building on this connection, we show that a neural network can be trained on a single EEG sample in a NeRF style manner to produce a fixed size and informative weight vector that encodes the entire signal. Moreover, via this representation we can render the EEG signal at previously unseen time steps and spatial electrode positions. We demonstrate that this approach enables continuous visualization of brain activity at any desired resolution, including ultra high resolution, and reconstruction of raw EEG signals. Finally, our empirical analysis shows that this method can effectively simulate nonexistent electrodes data in EEG recordings, allowing the reconstructed signal to be fed into standard EEG processing networks to improve performance.
Efficient Decoding Methods for Language Models on Encrypted Data
Sep 10, 2025Large language models (LLMs) power modern AI applications, but processing sensitive data on untrusted servers raises privacy concerns. Homomorphic encryption (HE) enables computation on encrypted data for secure inference. However, neural text generation requires decoding methods like argmax and sampling, which are non-polynomial and thus computationally expensive under encryption, creating a significant performance bottleneck. We introduce cutmax, an HE-friendly argmax algorithm that reduces ciphertext operations compared to prior methods, enabling practical greedy decoding under encryption. We also propose the first HE-compatible nucleus (top-p) sampling method, leveraging cutmax for efficient stochastic decoding with provable privacy guarantees. Both techniques are polynomial, supporting efficient inference in privacy-preserving settings. Moreover, their differentiability facilitates gradient-based sequence-level optimization as a polynomial alternative to straight-through estimators. We further provide strong theoretical guarantees for cutmax, proving it converges globally to a unique two-level fixed point, independent of the input values beyond the identity of the maximizer, which explains its rapid convergence in just a few iterations. Evaluations on realistic LLM outputs show latency reductions of 24x-35x over baselines, advancing secure text generation.
Differential Mamba
Jul 08, 2025Sequence models like Transformers and RNNs often overallocate attention to irrelevant context, leading to noisy intermediate representations. This degrades LLM capabilities by promoting hallucinations, weakening long-range and retrieval abilities, and reducing robustness. Recent work has shown that differential design can mitigate this issue in Transformers, improving their effectiveness across various applications. In this paper, we explore whether these techniques, originally developed for Transformers, can be applied to Mamba, a recent architecture based on selective state-space layers that achieves Transformer-level performance with greater efficiency. We show that a naive adaptation of differential design to Mamba is insufficient and requires careful architectural modifications. To address this, we introduce a novel differential mechanism for Mamba, empirically validated on language modeling benchmarks, demonstrating improved retrieval capabilities and superior performance over vanilla Mamba. Finally, we conduct extensive ablation studies and empirical analyses to justify our design choices and provide evidence that our approach effectively mitigates the overallocation problem in Mamba-based models. Our code is publicly available.
Overclocking LLM Reasoning: Monitoring and Controlling Thinking Path Lengths in LLMs
Jun 08, 2025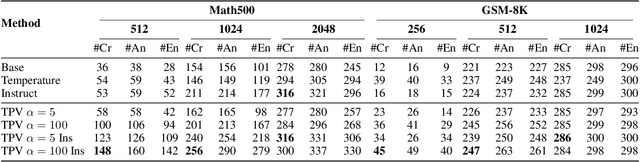
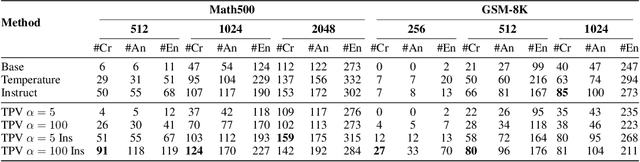
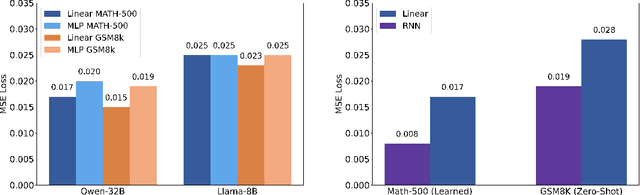
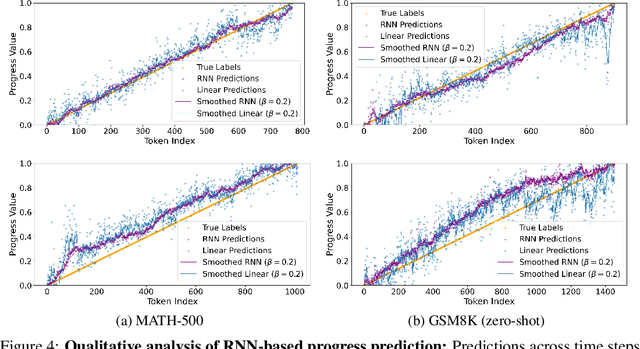
Recently, techniques such as explicit structured reasoning have demonstrated strong test-time scaling behavior by enforcing a separation between the model's internal "thinking" process and the final response. A key factor influencing answer quality in this setting is the length of the thinking stage. When the reasoning is too short, the model may fail to capture the complexity of the task. Conversely, when it is too long, the model may overthink, leading to unnecessary computation and degraded performance. This paper explores and exploits the underlying mechanisms by which LLMs understand and regulate the length of their reasoning during explicit thought processes. First, we show that LLMs encode their progress through the reasoning process and introduce an interactive progress bar visualization, which is then used to reveal insights on the model's planning dynamics. Second, we manipulate the internal progress encoding during inference to reduce unnecessary steps and generate a more concise and decisive chain of thoughts. Our empirical results demonstrate that this "overclocking" method mitigates overthinking, improves answer accuracy, and reduces inference latency. Our code is publicly available.
Overflow Prevention Enhances Long-Context Recurrent LLMs
May 12, 2025A recent trend in LLMs is developing recurrent sub-quadratic models that improve long-context processing efficiency. We investigate leading large long-context models, focusing on how their fixed-size recurrent memory affects their performance. Our experiments reveal that, even when these models are trained for extended contexts, their use of long contexts remains underutilized. Specifically, we demonstrate that a chunk-based inference procedure, which identifies and processes only the most relevant portion of the input can mitigate recurrent memory failures and be effective for many long-context tasks: On LongBench, our method improves the overall performance of Falcon3-Mamba-Inst-7B by 14%, Falcon-Mamba-Inst-7B by 28%, RecurrentGemma-IT-9B by 50%, and RWKV6-Finch-7B by 51%. Surprisingly, this simple approach also leads to state-of-the-art results in the challenging LongBench v2 benchmark, showing competitive performance with equivalent size Transformers. Furthermore, our findings raise questions about whether recurrent models genuinely exploit long-range dependencies, as our single-chunk strategy delivers stronger performance - even in tasks that presumably require cross-context relations.
On the Expressivity of Selective State-Space Layers: A Multivariate Polynomial Approach
Feb 04, 2025



Recent advances in efficient sequence modeling have introduced selective state-space layers, a key component of the Mamba architecture, which have demonstrated remarkable success in a wide range of NLP and vision tasks. While Mamba's empirical performance has matched or surpassed SoTA transformers on such diverse benchmarks, the theoretical foundations underlying its powerful representational capabilities remain less explored. In this work, we investigate the expressivity of selective state-space layers using multivariate polynomials, and prove that they surpass linear transformers in expressiveness. Consequently, our findings reveal that Mamba offers superior representational power over linear attention-based models for long sequences, while not sacrificing their generalization. Our theoretical insights are validated by a comprehensive set of empirical experiments on various datasets.
Power-Softmax: Towards Secure LLM Inference over Encrypted Data
Oct 12, 2024



Modern cryptographic methods for implementing privacy-preserving LLMs such as Homomorphic Encryption (HE) require the LLMs to have a polynomial form. Forming such a representation is challenging because Transformers include non-polynomial components, such as Softmax and layer normalization. Previous approaches have either directly approximated pre-trained models with large-degree polynomials, which are less efficient over HE, or replaced non-polynomial components with easier-to-approximate primitives before training, e.g., Softmax with pointwise attention. The latter approach might introduce scalability challenges. We present a new HE-friendly variant of self-attention that offers a stable form for training and is easy to approximate with polynomials for secure inference. Our work introduces the first polynomial LLMs with 32 layers and over a billion parameters, exceeding the size of previous models by more than tenfold. The resulting models demonstrate reasoning and in-context learning (ICL) capabilities comparable to standard transformers of the same size, representing a breakthrough in the field. Finally, we provide a detailed latency breakdown for each computation over encrypted data, paving the way for further optimization, and explore the differences in inductive bias between transformers relying on our HE-friendly variant and standard transformers. Our code is attached as a supplement.